
Abstract
This study proposes a Deep learning model, the Enhanced Feature Dynamic Fusion-Gated U-Net (EFDG-UNet), for retinal vessel segmentation. To address challenges in segmenting small vessels, handling lesion interference, and adapting to multi-scale structures, the model incorporates optimized feature fusion, dynamic selection, and global position modeling. The Feature Navigation Hub (FN-Hub) captures long-range dependencies across multiple encoder layers, improving multi-scale vessel segmentation. The Adaptive Gated Residual Block (AGRB) uses a dynamic gating mechanism to enhance feature selectivity in lesion areas and low-contrast scenarios. The Parallel Focused Attention Module (PFAM) optimizes channel and spatial information for fine-grained vessel features. Experimental validation on DRIVE, CHASE_DB1, and STARE datasets shows that EFDG-UNet achieves state-of-the-art performance, attaining an AUC of 0.9932 and F1-score of 0.8469 on CHASE_DB1, and an AUC of 0.9886 and F1-score of 0.8412 on DRIVE. The model shows improved performance in low-contrast regions and complex vessel structures compared to baseline methods.
Similar content being viewed by others
Introduction
Retinal vessel segmentation is crucial in modern medicine. As part of the human microcirculatory system, retinal vessel characteristics help diagnose various ocular and systemic diseases1. Structural changes in retinal vessels can indicate early signs of cardiovascular diseases2, providing critical evidence for risk assessment of hypertension, coronary artery disease, and stroke. In chronic hypertension, retinal vessels exhibit arterial narrowing and sclerosis, manifesting as “copper-wire” or “silver-wire” appearance. Manual assessment of these subtle changes is subjective, time-consuming, and prone to inter-observer variability, limiting its use in large-scale screening and longitudinal monitoring3. Therefore, extracting these clinically valuable features requires precise vessel segmentation. Accurate segmentation enables quantitative analysis of vessel morphology—including caliber, tortuosity, and branching patterns—which is essential for identifying pathological changes and developing personalized treatment plans.
Traditional retinal vessel segmentation requires manual annotation by specialists, which is time-consuming and subjective4. Challenges include discontinuities in segmentation, missed detections in low-contrast areas, and difficulties with complex vascular structures. These issues are compounded by imaging device limitations and complex retinal backgrounds.
Deep learning enables automatic feature extraction from annotated datasets, improving segmentation accuracy. Neural networks effectively adapt to complex backgrounds and low-contrast images, capturing multi-scale vascular features without predefined parameters. Models like U-Net5 have shown significant advantages in retinal vessel segmentation. Researchers have optimized network architectures through lightweight design, multi-path information fusion, and adaptation to complex vascular structures, enhancing performance with small vessels and low-contrast regions. Challenges remain in segmenting vessels in lesion areas (exudates and hemorrhages)6. Large vessel segmentation requires global context, while microvessel segmentation needs finer local features7. Current methods often lack specificity in feature extraction strategies, limiting effectiveness in fine-grained tasks.
The key research challenge remains developing models that can flexibly adapt to different vascular types and lesion characteristics while balancing global context with local detail.
The main contributions of this paper are as follows:
-
We propose the Adaptive Gated Residual Block (AGRB) with dynamic gating mechanism to improve segmentation performance in lesion areas and low-contrast regions.
-
We design the Feature Fusion Hub with Transformer-based attention to fuse multi-scale features and balance global context with local details.
-
We introduce the Parallel Focused Attention Module (PFAM) to extract multi-scale vascular features through parallel channel and spatial attention mechanisms.
-
We propose the Enhanced Feature Fusion Dynamic Gated U-Net (EFDG-UNet), which integrates AGRB, Feature Fusion Hub, and PFAM to improve segmentation performance in small vessels and lesion-affected areas.
The rest of the paper is organized as follows: Section “Related work” reviews related work; Section “Methods” details the implementation of EFDG U-Net; Section “Experiment” evaluates the proposed method through experiments; and Section “Conclusion” concludes the paper.
Related work
Recent AI advances have improved automatic retinal vessel segmentation from fundus images, supporting diagnosis and early detection of retinal abnormalities. Figure 1 encapsulates various models developed for retinal vessel segmentation in recent years. In the field of retinal vessel segmentation, the primary challenge initially encountered was the poor performance of traditional machine learning methods in segmenting small and delicate vessels. This limitation arises from the reliance on manually extracted features, which fail to adequately capture the complex morphology of vessels and subtle contrast information. To address this, Ronneberger et al. [5] proposed the U-Net model 1, the first deep learning architecture specifically designed for biomedical image segmentation. U-Net utilizes a symmetric encoder-decoder structure with skip connections to extract multi-scale features and achieve precise pixel-level localization, which has significantly advanced medical image segmentation.

Progression of modeling techniques for retinal vessel Seg-mentation Over the Past Decade.
However, U-Net struggles with vessels in regions of complex morphology and low contrast. Its accuracy in segmenting small vessels is limited, and increasing the network depth may lead to issues such as gradient explosion or vanishing gradients. In response to these limitations, subsequent research has optimized the U-Net architecture. Gegundez-Arias et al. 8 enhanced U-Net by incorporating batch normalization, residual modules, and a novel loss function, which improved the separability between pixels and vascular structures. Although these improvements boosted overall performance, the model’s ability to capture small vessels remained limited.
To further address this issue, DUNet 9 replaced the standard convolutional layers with deformable convolution blocks, enhancing the encoder’s ability to capture contextual information. Additionally, by merging low- and high-level feature maps, the decoder achieved more accurate localization, significantly improving the segmentation of complex vascular shapes. Mou et al. 10 introduced a dual self-attention mechanism, incorporating both spatial and channel attention modules to adaptively integrate local features and global dependencies, thereby improving the model’s sensitivity to small vessels. However, these methods typically introduce additional modules only at the lowest scale, neglecting the capacity to process high-resolution details, resulting in imprecise segmentation of tiny vessels.
To further improve the segmentation of small vessels, Kamran et al. 11 proposed RV-GAN, a multi-scale generative architecture featuring two generators and two multi-scale autoencoding discriminators, which more accurately localize and segment tiny vessels. Despite its strong vessel segmentation capabilities, RV-GAN’s relatively low sensitivity suggests that its ability to extract small vessels is still limited. Zhou et al. 12 developed a noisy label synthesis procedure and proposed a group learning scheme to improve model performance when trained with imperfect labels. However, these strategies primarily focus on improving label quality and do not dynamically adapt to the characteristics of various vascular morphologies and lesion areas.
Recent advances from 2022 to 2025 have introduced novel perspectives to address these challenges. Galdran et al. 13 demonstrated that lightweight U-Net variants with carefully designed training strategies can achieve competitive performance with significantly fewer parameters, challenging the trend toward increasingly complex architectures. The integration of Transformer architectures has marked a paradigm shift, with Lin et al. 14 proposing the Stimulus-Guided Adaptive Transformer Network (SGAT-Net) that combines inductive bias with self-attention mechanisms to extract local–global compound features, effectively balancing the extraction of detailed appearance information with contextual understanding.
More recently, state space models (SSMs) have emerged as a promising alternative to Transformers for capturing long-range dependencies in vessel structures. Wang et al. 15 introduced Serp-Mamba, which employs a serpentine interwoven adaptive scan mechanism to follow curved vessel structures in ultra-wide-field SLO images, demonstrating competitive performance in maintaining vascular continuity. Most recently, research in 2025 16 has focused on enhancing model convergence and feature learning through residual connections and advanced preprocessing techniques, showing promising results in clinical applications.
Despite these advances, several fundamental challenges persist, particularly in achieving dynamic adaptation to diverse vascular morphologies while maintaining computational efficiency and effectively integrating multi-scale feature fusion with global context modeling.
Although significant progress has been made, several fundamental limitations remain. First, existing methods struggle with fine-grained feature extraction for small and delicate vessels. Second, effective dynamic adaptation mechanisms for diverse vascular morphologies and lesion areas (e.g., exudates and hemorrhages) are lacking. Third, current approaches inadequately balance global contextual information with local detailed features. Addressing these challenges through a model that dynamically adapts to various vascular characteristics while integrating multi-scale feature fusion and global context modeling is crucial for advancing retinal vessel segmentation performance.
Methods
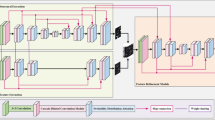
The proposed EFDG-UNet network, as illustrated in Fig. 2, consists of several key components: a U-shaped structure incorporating downsam-pling and upsampling processes, Adaptive Gated Residual Blocks (AGRB), a Parallel Focused Attention Module (PFAM), and a Feature Fusion Hub (FN-Hub). The network uses ReLU activation and processes preprocessed grayscale images.

Overview of the EFDG-UNet Architecture.the network is designed for medical image processing, specifically for extracting vascular structures from retinal images. The Encoder compresses the input image into feature representations, the FM-Hub manages and distributes these features, and the Decoder reconstructs the vascular tree from these features.
The encoder consists of four consecutive AGRBs with downsampling. After each stage, max-pooling halves the spatial dimensions while doubling the channels. Following four downsampling stages, the feature maps are passed to the bottleneck layer. In this layer, the PFAM further processes the features. PFAM leverages an attention mechanism to capture long-range dependencies and location-specific information in the feature maps, enhancing the network’s understanding of global context. Simultaneously, feature maps from each stage of the encoder are passed to the FN-Hub module, which captures global relationships between features and generates enhanced skip connections. The upsampling path of the decoder is symmetric to the encoder structure and consists of four consecutive Up Adaptive Gated Residual Blocks (UpAGRB). During the upsampling process, the spatial dimensions of the feature maps are gradually increased while the number of channels is reduced, restoring the resolution to match the original input. Finally, a 1 × 1 convolutional layer adjusts the number of channels to produce the segmentation results.
Adaptive gated residual block
To address the challenges of interference from pathological regions and poor adaptability to low-contrast scenes in retinal vessel segmentation, we propose the AGRB as a replacement for traditional convolutional blocks, As shown in Fig. 3. The AGRB enhances the model’s representational capacity for feature extraction and enhancement through the combination of residual connections and the adaptive gating mechanism. Additionally, Spatial Dropout is introduced to mitigate overfitting. In both the encoder and decoder, AGRBs perform specific tasks: in the encoder, AGRBs progressively extract and compress features, while in the decoder, they are adjusted to restore the image resolution.

Adaptive gated residual block architecture.
In the encoder, the core structure of the AGRB consists of two convolutional layers, each followed by batch normalization and activation functions. First, the input feature map \(x\) is processed by the first convolutional layer, followed by batch normalization and a ReLU activation function to produce the intermediate feature map \(x_{1}\):
Next, the intermediate feature map \(x_{1}\) is passed through a second convolutional layer and batch normalization, resulting in the feature map \(x_{2}\), as shown in the following equation:
A spatial dropout module is applied to \(x_{2}\) to reduce noise and enhance regularization. The adaptive gating mechanism of the AGRB extracts global context information via global average pooling, followed by two fully connected layers and a Sigmoid activation function to generate the gating coefficient \(g\), as shown in the following equation:
The gating coefficient \(g\) ranges between 0 and 1, adjusting the weight of the residual term. The residual connection performs channel matching on \(x\), ensuring its channel number aligns with that of the main branch feature. It is then weighted and added to \(x_{2}\), followed by a ReLU activation to obtain the output \(y\), the calculation is:
As shown in Fig. 4, the decoder uses UpAGRB, which adds upsampling and skip connections to the AGRB. The input feature map is first upsampled to half the original image size using bilinear interpolation. Then it is concatenated with the feature map from the corresponding FN-Hub layer to combine semantic information from the encoder. The concatenated features pass through the AGRB module for feature fusion. The adaptive gating mechanism in UpAGRB adjusts the weight of the residual connection based on the input, which helps control how different features contribute during upsampling.

Up adaptive gated residual block architecture.
Parallel feature attention module
PFAM is a module with two parts that work in parallel: a Channel Attention (CA) module and a Spatial Attention (SA) module, as shown in Fig. 5. These two parts process channel information and spatial information at the same time and independently. By handling both types of information separately, PFAM avoids losing important features in either dimension. This parallel processing improves the model’s ability to capture fine-grained features, leading to better segmentation accuracy and robustness.

Parallel feature attention module architecture.
The Channel Attention Module generates channel importance weights by aggregating the global features of each channel, thereby adjusting the channel-wise feature representation. Specifically, the input feature map \(X \in {\mathbb{R}}^{B \times C \times H \times W}\) undergoes global average pooling and max pooling to obtain global descriptors for each channel, denoted as \(Y_{{{\text{avg}}}}\) and \(Y_{{{\text{max}}}}\), where \(Y_{{{\text{avg}}}} ,Y_{{{\text{max}}}} \in {\mathbb{R}}^{B \times C}\). The two descriptors are then summed and passed through a two-layer shared fully connected network for feature compression and expansion, producing the channel weights \(W_{{{\text{CA}}}}\), which is given as follows:
Here, \(W_{1} \in {\mathbb{R}}^{C \times C/r}\) and \(W_{2} \in {\mathbb{R}}^{C/r \times C}\) are the weight matrices of the fully connected layers; \(r\) denotes the channel compression ratio, \(\delta\) represents the ReLU activation function, and \(\sigma\) is the Sigmoid activation function. The generated channel weights \(W_{{{\text{CA}}}}\) are then multiplied element-wise with the input feature map along the channel dimension, thereby enhancing the channel-wise feature representation, as shown in the following equation:
The Spatial Attention module captures global spatial information through maximum pooling and average pooling along the spatial dimensions, generating spatial attention weights. The input feature map \({\mathbf{X}}\) undergoes maximum and average pooling along the channel dimension, resulting in two spatial feature maps:
where \(Y_{{{\text{avg}}}} ,Y_{{{\text{max}}}} \in {\mathbb{R}}^{B \times 1 \times H \times W}\). These maps are concatenated along the channel dimension, and the result is passed through a \(7 \times 7\) convolutional layer to generate the spatial attention weights, the calculation is:
where \(\left[ ; \right]\) denotes concatenation along the channel dimension, \(f^{7 \times 7}\) is a \(7 \times 7\) convolution operation, and \(\sigma\) is the Sigmoid activation function. Finally, the spatial weights are element-wise multiplied with the input feature map, enhancing the spatial dimension, the calculation is:
After optimizing both the channel and spatial attention, the module generates the final output feature map through a fusion operation. The results from the channel attention and spatial attention modules are first concatenated along the channel dimension, which is given as follows:
where \(X_{{{\text{fusion}}}} \in {\mathbb{R}}^{B \times 2C \times H \times W}\). The fused feature map undergoes channel compression through a \(1 \times 1\) convolutional layer, followed by batch normalization and ReLU activation for further optimization, which is defined as:
where \(\delta\) represents the ReLU activation function, and “BN” refers to batch normalization. The final feature map \(X_{{{\text{out}}}}\) is used for subsequent task processing.
The PFAM module independently optimizes both channel and spatial attention, capturing global channel dependencies and spatial context information in the feature map. The fusion operation further combines the advantages of these two attention mechanisms, providing high-quality feature representations for downstream tasks.
Feature navigation hub
In this model, we propose a Transformer-based FN-Hub to efficiently integrate feature information from different encoding layers during the decoding phase, as shown in Fig. 6. By incorporating the self-attention mechanism of Transformer, this module captures long-range dependencies between multi-scale features, enhancing its ability to process global context information, especially for fine and coarse vessel structures.

Feature navigation hub architecture.
Let the skip connection features from the encoder be denoted as \(S_{i}\), where \(i = 1,2, \ldots ,n\) represents the number of encoding layers, and \(S_{i} \in {\mathbb{R}}^{{C_{i} \times H_{i} \times W_{i} }}\). To unify the channel dimensions, each feature map \(S_{i}\) is processed through a 3 × 3 convolution, batch normalization, and ReLU activation, resulting in the standardized feature map \(\hat{S}_{i}\), which is defined as:
where \(\hat{S}_{i} \in {\mathbb{R}}^{{C_{h} \times H_{i} \times W_{i} }}\) is the processed feature, \(C_{h}\) is the unified channel count, and Conv, BN, and ReLU represent the convolution, batch normalization, and ReLU activation functions, respectively.
In each decoding layer \(D_{j}\), to match the spatial dimensions of the decoder, the feature map \(\hat{S}_{i}\) is resized to the target resolution \(\left( {H_{j} ,W_{j} } \right)\). This is done via bilinear interpolation, mathematically expressed as:
where \(\hat{S}_{i}^{j} \left( {x,y} \right)\) represents the pixel value at position \(\left( {x,y} \right)\) in the target resolution, and \(\hat{S}_{i} \left( {x_{m} ,y_{n} } \right)\) refers to the values of the four nearest pixels in the original feature map. The interpolation weight \(w_{mn}\) is defined as:
Next, we employ the attention mechanism of the Transformer to capture the dependencies between the multi-scale features \(\left\{ {\hat{S}_{i}^{j} } \right\}\). First, the adjusted features are stacked along a new dimension and reshaped into a sequence representation which is given as follows:
where \(F_{j}\) represents the stacked multi-scale features, \(n\) is the number of feature layers, and \(\left( {H_{j} ,W_{j} } \right)\) is the target resolution.
The features are then reshaped into a tensor with shape \(\left( {B,n \times C_{h} ,H_{j} \times W_{j} } \right)\), and the dimensions are rearranged to \(\left( {H_{j} \times W_{j} ,B,n \times C_{h} } \right)\) to match the input requirements of the Transformer encoder. After passing through the Transformer encoder, the features integrate global context information, yielding the encoded output, which is given as follows:
where \(F_{j}^{{{\text{out}}}} \in {\mathbb{R}}^{{H_{j} \times W_{j} \times B \times (n \times C_{h} )}}\) contains the multi-scale global context information.
The output features are then restored to the original spatial dimensions \((B,n \times C_{h} ,H_{j} ,W_{j} )\), and an averaging operation is performed across the encoding layers to obtain the fused feature map, the calculation is:
where \(\hat{F}_{j} \in {\mathbb{R}}^{{C_{h} \times H_{j} \times W_{j} }}\) is the fused feature map, and \(F_{{\left( {j,i} \right)}}\) denotes the fused result from the i-th encoding layer.
The fused feature \(\hat{F}_{j}\) is then processed using a 1 × 1 convolution, batch normalization, and ReLU activation to match the required channel count \(C_{j}\), resulting in the final output feature map \(O_{j}\), which is given as follows:
where \(O_{j} \in {\mathbb{R}}^{{C_{j} \times H_{j} \times W_{j} }}\) is the generated decoder feature map.
Within the Transformer module, we use the multi-head self-attention mechanism to model the complex dependencies between features. Let the input feature representation be \(F\), where \(F \in {\mathbb{R}}^{L \times B \times d}\) and \(L = H_{j} \times W_{j}\). The core computation for multi-head self-attention is:
where \(Q = FW_{Q}\), \(K = FW_{K}\), and \(V = FW_{V}\), and \(W_{Q} ,W_{K} ,W_{V} \in {\mathbb{R}}^{d \times d}\) are the linear transformation weight matrices for the query, key, and value, respectively. As shown in Fig. 7.

Transformer architecture.
While FN-Hub employs a standard Transformer encoder, its design addresses the data requirements typically associated with Transformer architectures through several key aspects.
First, unlike Vision Transformers that process raw images and must learn visual representations from scratch, FN-Hub operates on pre-extracted encoder features containing rich semantic information. This shifts the learning task from pixel-to-semantic mapping to feature relationship modeling, substantially reducing data requirements.
Second, FN-Hub applies Transformer only at the decoding stage for multi-scale feature integration, rather than replacing the entire architecture. This design inherits the inductive biases (locality and translation invariance) from the pre-trained CNN encoder while maintaining parameter efficiency. The Transformer component builds upon learned representations rather than learning from scratch.
Recent literature validates Transformer-based attention mechanisms on small-scale retinal datasets. Lin et al. 14, Lv et al. 38, and Chen et al. 37 successfully applied similar approaches on datasets of identical scales (DRIVE: 40, CHASE: 28, STARE: 20 images).
Experiment
Datasets
In our experiments, we utilized the DRIVE, CHASE_DB1, and STARE datasets for training and testing. These three datasets are publicly available and serve as standard benchmarks for retinal vessel segmentation, as shown in Fig. 8.

Example samples from DRIVE, CHASE_DB1, and STARE datasets for retinal vessel segmentation.
The DRIVE dataset consists of 40 RGB color fundus images, each with a resolution of 565 × 584 pixels. We divided the dataset into training and validation sets in an 80:20 ratio, using the official training set for the split, while the remaining 20 images were kept as the test set.
The CHASE_DB1 dataset contains 28 RGB color fundus images, with a resolution of 999 × 960 pixels. We assigned the first 14 images to the training set, the following 6 images to the validation set, and the remaining 8 images to the test set.
The STARE dataset comprises 20 RGB color fundus images, each with a resolution of 700 × 605 pixels. We divided the dataset in a 70:20:10 ratio, with the first 10 images used for training, the next 4 for validation, and the remaining 6 for testing.
For all three datasets, we used the annotations from the first expert for evaluating the segmentation performance.
Image preprocessing
We apply green channel extraction and CLAHE to enhance retinal image quality. To reduce color variations from different acquisition devices or lighting conditions, we extracted the green channel from RGB images, as it provides superior vessel-background contrast compared to red and blue channels. This single-channel representation also simplifies subsequent processing while preserving essential vessel information.
where \(I_{{{\text{Gray}}}}\) represents the pixel intensity of the grayscale image, and \(I_{{{\text{Red}}}}\), \(I_{{{\text{Green}}}}\), and \(I_{{{\text{Blue}}}}\) represent the pixel intensities of the red, green, and blue channels, respectively. To further enhance vessel-background contrast, we applied CLAHE preprocessing. CLAHE adaptively equalizes local contrast by redistributing intensity values within non-overlapping image regions, with a clip limit to suppress noise amplification. We set the clip limit to 2.0 and divided images into 8 × 8 grids for region-wise processing. As shown in Fig. 9, these preprocessing steps significantly improved vessel visibility, with small vessels becoming particularly distinguishable from the background.

Example images after each preprocessing step. a Original Images; b Green Channel Extraction; c Images After CLAHE Operation.
To enhance the model’s generalization ability, we applied various data augmentation techniques to the training set. Geometric transformations included horizontal and vertical flips, rotations at 15° and 170°, elastic deformation with large amplitude, and optical distortion with limited distortion strength. Photometric transformations included Gaussian blurring with kernel sizes varying between 3 and 7, Gaussian noise with intensity ranging from 10 to 50, and brightness/contrast adjustment within ± 20%. All augmented images were then cropped into 48 × 48 non-overlapping patches for training.
Image segmentation performance evaluation metrics
In image segmentation tasks, the following performance metrics were used to provide a comprehensive evaluation of segmentation effectiveness: Intersection over Union (IoU), Accuracy (ACC), Sensitivity (Se), Specificity (Sp), F1 Score (F1), and Area Under the Curve (AUC). The specific definitions are as follows:
We used five standard metrics to evaluate model performance: Accuracy (ACC), Sensitivity (Se), Specificity (Sp), F1 Score, and Area Under the Curve (AUC). ACC represents the proportion of correctly classified pixels. Se measures the ability to identify vessel pixels (true positive rate), while Sp measures the ability to correctly identify background pixels (true negative rate). F1 Score balances precision and sensitivity, and AUC evaluates overall performance across different decision thresholds.
Experimental details
We evaluated model performance on three public datasets (CHASE, DRIVE, and STARE), comparing results with state-of-the-art methods. Ablation experiments were conducted to analyze each module’s contribution. The model was implemented in PyTorch and trained using the Adam optimizer with an initial learning rate of 0.0001. Detailed experimental environment and hyperparameter settings are listed in Table 1. We employed the ReduceLROnPlateau strategy to dynamically adjust the learning rate, reducing it to 10% when validation loss showed no improvement. Training was performed for 100 epochs with a batch size of 16 and cross-entropy loss function.
Comparisons with state of the art models
Table 2 presents a performance comparison of various algorithms on the CHASE_DB1 dataset, including classical methods such as U-Net, AttentionU-Net, LadderNet, and ResUNet++, as well as recent advanced models. As shown, EFDG-UNet outperforms the other models on the CHASE_DB1 dataset, achieving superior Acc, Sp, AUC, and F1 score.
EFDG-UNet achieves accuracy of 0.9788, specificity of 0.9893, AUC of 0.9932, and F1 score of 0.8469, leading in overall performance. Compared to the latest 2024–2025 models, EFDG-UNet demonstrates superior accuracy over MVM-UNet with an accuracy of 0.9762 and TCDDU-Net with an accuracy of 0.9723. The sensitivity of 0.8405 is slightly lower than the sensitivity of SDDC-Net of 0.8627 and D-MNet of 0.8541, but higher than MVM-UNet with a sensitivity of 0.8305, DMSU-Net++ with a sensitivity of 0.8281, and TCDDU-Net with a sensitivity of 0.8187, and it shows a 10.5% and 9.8% improvement over U-Net and ResUNet++ in terms of sensitivity, respectively, indicating significant progress in detecting small vessels and complex details. Regarding specificity, EFDG-UNet leads most comparison models with a specificity of 0.9893, surpassing DMSU-Net++ with a specificity of 0.9880, MVM-UNet with a specificity of 0.9860, and TCDDU-Net with a specificity of 0.9823, second only to ResUNet++ with a specificity of 0.9924 and MBSNet with a specificity of 0.9892. This suggests its high reliability in distinguishing vessels from background regions, effectively reducing false positives and enhancing segmentation accuracy. With an AUC of 0.9932, EFDG-UNet outperforms TCDDU-Net with an AUC of 0.9850 and DMSU-Net++ with an AUC of 0.9836. The F1 score of 0.8469 is the highest among all models, exceeding CFFANet with an F1 score of 0.8420, DMSU-Net++ with an F1 score of 0.8281, TCDDU-Net with an F1 score of 0.7838, as well as MBSNet with an F1 score of 0.8386, and is also higher than Attention U-Net with an F1 score of 0.8248 and HRNet with an F1 score of 0.8346, demonstrating a good balance between precision and recall and reflecting its superior overall performance.
Table 3 summarizes the performance of EFDG-UNet and other leading algorithms on the DRIVE dataset. The comparison results show that EFDG-UNet achieves a favorable balance across several key metrics, showcasing its potential as an advanced segmentation model.
From the perspective of accuracy, EFDG-UNet achieves a value of 0.9736, the highest among all compared models, surpassing TCDDU-Net with an accuracy of 0.9698, MVM-UNet with an accuracy of 0.9683, comparable to high-performance models such as UNet3+ and SDDC-Net, and significantly outperforming traditional models with an accuracy of 0.9691 for U-Net and 0.9561 for LadderNet. This indicates that EFDG-UNet offers higher precision in overall segmentation tasks. In terms of specificity, EFDG-UNet scores 0.9856, leading the field and surpassing recent models including DMSU-Net++ with a specificity of 0.9845, TCDDU-Net with a specificity of 0.9838, and MVM-UNet with a specificity of 0.9786, and only slightly behind a few models such as ResUNet++ with a specificity of 0.9837, which reflects its efficiency in recognizing background regions. Regarding sensitivity, EFDG-UNet performs at 0.8438, higher than DMSU-Net++ with a sensitivity of 0.8374 and TCDDU-Net with a sensitivity of 0.8258, but slightly lower than MVM-UNet with a sensitivity of 0.8547, substantially outperforming classical methods such as U-Net with a sensitivity of 0.7948 and some modern models such as ResUNet++ with a sensitivity of 0.7856, demonstrating its greater capability in detecting small vessels. Although its sensitivity is slightly lower than the sensitivity of SDDC-Net of 0.8603 and DCA-CNN of 0.8745, EFDG-UNet’s strong balance in specificity and accuracy makes it more balanced in overall performance.
EFDG-UNet achieves an AUC of 0.9886 and an F1 score of 0.8412, both ranking among the top performers. The AUC of 0.9886 is the highest among all models, outperforming TCDDU-Net with an AUC of 0.9868, DMSU-Net++ with an AUC of 0.9786, and MBSNet with an AUC of 0.9873. The F1 score of 0.8412 is also the highest, exceeding DMSU-Net++ with an F1 score of 0.8275, TCDDU-Net with an F1 score of 0.8265, and CFFANet with an F1 score of 0.8290. The AUC reflects the model’s robustness across different thresholds, while the F1 score highlights the harmony between precision and recall. Compared to other recent models, EFDG-UNet demonstrates superior segmentation performance, particularly in terms of overall capability.
EFDG-UNet excels in multiple key metrics, especially in Acc and comprehensive segmentation performance. Its high Se and Sp values indicate that the model effectively balances segmentation of both small vessels and background regions. Its outstanding AUC and F1 scores further validate its robustness and reliability, making it one of the leading methods for retinal vessel segmentation.
As shown in Table 4, EFDG-UNet achieves an accuracy of 0.9637, specificity of 0.9769, an AUC of 0.9842, and an F1 score of 0.8376, particularly excelling in specificity and AUC. However, compared to other methods, EFDG-UNet’s overall performance still has room for improvement, especially in terms of sensitivity. Although its sensitivity is 0.8575, which is satisfactory, it surpasses MVM-UNet with a sensitivity of 0.8178 and TCDDU-Net with a sensitivity of 0.7920, it remains slightly lower than that of several other methods.
The sensitivity of ResUNet++ and SCS-Net is 0.8173 and 0.8207, respectively, slightly higher than EFDG-UNet’s, suggesting that these methods may be better suited for precise target detection in certain tasks. MMDC-Net, with a sensitivity of 0.8509, is close to EFDG-UNet, indicating comparable performance in target detection. BCU-Net achieves a sensitivity of 0.8500, also comparable to EFDG-UNet.
In terms of specificity, GDF-Net stands out with a specificity of 0.9957, significantly outperforming other methods. This suggests that GDF-Net is particularly effective at reducing false positives. However, GDF-Net’s accuracy and F1 score are 0.9653 and 0.8022, respectively, with the lower F1 score indicating an imbalance in its overall performance despite its high specificity. EFDG-UNet’s specificity of 0.9769 is lower than TCDDU-Net with a specificity of 0.9884 and MBSNet with a specificity of 0.9871, but higher than MVM-UNet with a specificity of 0.9839 and CFFANet with a specificity of 0.9800. In contrast, EFDG-UNet maintains a more balanced performance across accuracy, specificity, and F1 score, without overemphasizing any single metric, demonstrating more stable and comprehensive performance.
U-Net and Attention U-Net achieve accuracies of 0.9738 and 0.9719, respectively, along with TCDDU-Net with an accuracy of 0.9740 and MBSNet with an accuracy of 0.9739, slightly higher than EFDG-UNet. However, their performance in sensitivity and F1 score is somewhat weaker, particularly Attention U-Net, which has an F1 score of 0.8084. Despite the higher accuracy, their overall performance balance is slightly inferior. Notably, EFDG-UNet’s F1 score of 0.8376 is competitive, slightly lower than CFFANet with an F1 score of 0.8400, but exceeding BCU-Net with an F1 score of 0.8223, MBSNet with an F1 score of 0.8213, and TCDDU-Net with an F1 score of 0.8163. Therefore, while other models may outperform EFDG-UNet in specific metrics, EFDG-UNet demonstrates a more balanced performance across multiple key indicators.
In terms of AUC, EFDG-UNet achieves 0.9842, which is competitive with top-performing models, though slightly lower than MBSNet with an AUC of 0.9898 and TCDDU-Net with an AUC of 0.9856. In summary, EFDG-UNet demonstrates exceptional overall performance in accuracy, AUC, and specificity, particularly excelling in specificity and AUC. Although its sensitivity is slightly lower, EFDG-UNet remains highly competitive, especially for medical image segmentation tasks that require balanced and robust overall performance. In comparison, while other methods may excel in specific metrics, their overall performance tends to favor certain aspects, lacking the comprehensive balance that EFDG-UNet offers.
Vascular analysis
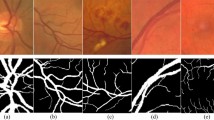
To further demonstrate the segmentation performance of EFDG-UNet on complex small vessel shapes, we conducted comparative experiments on the CHASE_DB1 and STARE datasets, which contain numerous small vessels with intricate shapes. Figure 10 shows the original images and manual annotations from different datasets, along with the segmentation results from Oktay et al. 17, Ronneberger et al. 1, Liu et al. 41, Alom et al. 42, and our proposed EFDG-UNet. Specifically, (a) and (b) are examples from the DRIVE dataset, and (c) and (d) are from the CHASE_DB1 dataset. EFDG-UNet demonstrates significant advantages in segmenting complex vascular regions. For larger vessels, EFDG-UNet exhibits greater coherence and completeness compared to models such as Attention-U-Net, R2U-Net, and FR-UNet, accurately preserving the overall vessel morphology. In the segmentation of smaller vessels, EFDG-UNet not only accurately identifies vessel branches and junctions but also significantly reduces misclassifications, avoiding false-positive segmentation of background regions as vessels. Overall, EFDG-UNet exhibits stronger robustness and higher segmentation precision in fine-grained vascular segmentation tasks.

Comparison of the segmentation results of EFDG-UNet and other methods on the CHASE_DB1 and DRIVE datasets.
To better illustrate the segmentation performance, we present binarized segmentation results on the STARE dataset. Figure 11 shows the segmentation results of all models, including a comparison between EFDG-UNet and other methods.

Comparison of the binarized segmentation results of EFDG-UNet and other methods on the STARE dataset.
As shown in Fig. 11, EFDG-UNet continues to demonstrate clear advantages in vascular extraction tasks, particularly in segmenting small vessels and maintaining vessel connectivity. Compared to other methods, EFDG-UNet more accurately preserves the continuity and integrity of vessels when processing complex vascular networks. Specifically, in the segmentation of small vessels, EFDG-UNet clearly distinguishes vessels from background regions, reducing false positives and missed detections while preventing the background from being incorrectly segmented as vessels. Additionally, EFDG-UNet shows higher coherence in extracting larger vessels, preserving both the vessel’s diameter variations and structural features more effectively than other models such as U-Net and ResUNet.
Ablation study
An ablation study was conducted to assess the individual components of EFDG-UNet on the CHASE_DB1, DRIVE, and STARE datasets, with the original U-Net serving as the baseline model.
As shown in Table 5, the ablation experiments on the CHASE_DB1 dataset demonstrate the contribution of each module to the overall performance of EFDG-UNet.
The baseline U-Net model achieved an accuracy of 0.9734, sensitivity of 0.8791, specificity of 0.9806, AUC of 0.9898, and F1 score of 0.8218. After introducing the AGRB module, accuracy improved to 0.9773, specificity increased to 0.9886, and F1 score rose to 0.8362. However, sensitivity decreased to 0.8287. When combining PFAM with AGRB, specificity further increased to 0.9894 and AUC reached 0.9920, but sensitivity continued to decline to 0.8181. The combination of FN-Hub and AGRB achieved an accuracy of 0.9776, with sensitivity improving to 0.8540 and F1 score reaching 0.8418. The complete EFDG-UNet model, integrating all three modules, achieved the best overall performance with an accuracy of 0.9788, sensitivity of 0.8405, specificity of 0.9893, AUC of 0.9932, and F1 score of 0.8469. It is noteworthy that EFDG-UNet exhibits a decrease in sensitivity (0.8405 vs. 0.8791) compared to the baseline U-Net, which reflects the classical sensitivity–specificity trade-off in medical image segmentation. The model achieves substantially higher specificity (0.9893 vs. 0.9806) at the cost of slightly lower sensitivity. Importantly, the improvements in F1 score (0.8469 vs. 0.8218) and AUC (0.9932 vs. 0.9898) demonstrate that EFDG-UNet achieves superior overall performance and better balance between precision and recall. This trade-off is particularly evident in the ablation results: while AGRB initially reduces sensitivity to 0.8287, the FN-Hub module effectively mitigates this issue by improving sensitivity to 0.8540 in the FN-Hub + AGRB configuration.
As shown in Table 6, the ablation experiments on the DRIVE dataset further validate the effectiveness of each module in EFDG-UNet.
The baseline U-Net model achieved an accuracy of 0.9691, sensitivity of 0.7948, specificity of 0.9860, AUC of 0.9845, and F1 score of 0.8172. With the addition of AGRB, accuracy increased to 0.9716, sensitivity improved to 0.8151, and F1 score rose to 0.8297. The combination of FN-Hub and AGRB further improved performance, achieving an accuracy of 0.9730, sensitivity of 0.8561, and F1 score of 0.8402. When combining PFAM with AGRB, sensitivity reached 0.8584, the highest among module combinations, with an accuracy of 0.9725 and F1 score of 0.8380. The complete EFDG-UNet model achieved an accuracy of 0.9736, sensitivity of 0.8438, specificity of 0.9856, AUC of 0.9886, and F1 score of 0.8412, demonstrating the best overall performance. While the complete model’s sensitivity (0.8438) is slightly lower than the PFAM + AGRB combination (0.8584), it achieves the highest F1 score (0.8412) and maintains competitive AUC (0.9886), indicating optimal overall balance across all performance metrics.
As shown in Table 7, the ablation experiments on the STARE dataset demonstrate consistent improvements from each module integration.
The baseline U-Net model achieved an accuracy of 0.9738, sensitivity of 0.7814, specificity of 0.9897, AUC of 0.9892, and F1 score of 0.8138. After introducing AGRB, sensitivity significantly improved to 0.8505, though accuracy decreased to 0.9632. The F1 score increased to 0.8292. The combination of PFAM and AGRB further improved sensitivity to 0.8661, with F1 score reaching 0.8321. The FN-Hub and AGRB combination achieved an accuracy of 0.9638, sensitivity of 0.8534, and F1 score of 0.8320. The complete EFDG-UNet model achieved an accuracy of 0.9637, sensitivity of 0.8575, specificity of 0.9769, AUC of 0.9842, and F1 score of 0.8376, representing the best balanced performance across all metrics. On the STARE dataset, EFDG-UNet demonstrates a different performance characteristic compared to the baseline U-Net, with decreases in accuracy (0.9637 vs. 0.9738), specificity (0.9769 vs. 0.9897), and AUC (0.9842 vs. 0.9892). However, these changes are accompanied by a substantial improvement in sensitivity (0.8575 vs. 0.7814, a 9.7% increase) and F1 score (0.8376 vs. 0.8138, a 2.9% increase). This performance shift reflects the model’s optimization towards better detection of positive samples (vessel pixels), which is particularly valuable in clinical diagnosis where missing true vessels can have more serious consequences than false alarms. The improved F1 score indicates that EFDG-UNet achieves more clinically relevant performance by better balancing precision and recall on this dataset.
Across all three datasets, the ablation studies show that each module contributes to the overall performance of EFDG-UNet. The AGRB module consistently improved F1 scores and specificity, the PFAM module enhanced sensitivity particularly on DRIVE and STARE datasets, and the FN-Hub module effectively balanced sensitivity and specificity. The complete EFDG-UNet model, integrating all three modules, achieved superior overall performance on all datasets, demonstrating the synergistic effect of the proposed architecture. While dataset-specific performance trade-offs are observed (e.g., sensitivity decrease on CHASE_DB1, accuracy decrease on STARE), these are accompanied by improvements in comprehensive metrics such as F1 score and AUC, indicating that EFDG-UNet optimizes for clinically meaningful overall performance rather than individual metrics. The sensitivity decrease on CHASE_DB1 is attributed to the dataset’s unique characteristics—higher vessel thickness variability and more complex vascular structures—which make the AGRB module’s specificity-enhancing mechanism more conservative in detecting ambiguous vessel pixels, while still achieving superior F1 score (0.8469 vs. 0.8218) and AUC (0.9932 vs. 0.9898). On DRIVE and STARE datasets, sensitivity improvements of 6.2% and 9.7% respectively demonstrate the model’s robust capability in detecting vessel structures across different data distributions.
Cross-dataset generalization
To evaluate the generalization capability of EFDG-UNet, cross-dataset experiments were conducted by training the model on one dataset and testing it on another. The results are presented in Table 8, comparing EFDG-UNet with several state-of-the-art methods including CS-Net, AACA-MLA-D-UNet, TP-Net, and HiDiffSeg.
As shown in Table 8, when trained on DRIVE and tested on STARE, EFDG-UNet achieved an accuracy of 0.9822, specificity of 0.9909, sensitivity of 0.7722, and AUC of 0.9822. Compared to the other methods, EFDG-UNet achieved the highest accuracy, specificity, and AUC. The accuracy of 0.9822 outperformed HiDiffSeg with an accuracy of 0.9649 and CS-Net with an accuracy of 0.9629. The specificity of 0.9909 was notably higher than HiDiffSeg with a specificity of 0.9869 and AACA-MLA-D-UNet with a specificity of 0.9846. However, the sensitivity of 0.7722 was lower than HiDiffSeg with a sensitivity of 0.8244 and TP-Net with a sensitivity of 0.8079.
When trained on STARE and tested on DRIVE, EFDG-UNet achieved an accuracy of 0.9677, specificity of 0.9812, sensitivity of 0.8290, and AUC of 0.9851. In this configuration, EFDG-UNet achieved the higher performance across all metrics compared to the other methods. The accuracy of 0.9677 outperformed HiDiffSeg with an accuracy of 0.9630 and TP-Net with an accuracy of 0.9582. The sensitivity of 0.8290 surpassed TP-Net with a sensitivity of 0.8190 and HiDiffSeg with a sensitivity of 0.8173. The AUC of 0.9851 was significantly higher than AACA-MLA-D-UNet with an AUC of 0.9735 and TP-Net with an AUC of 0.9718.
The cross-dataset experiments show that EFDG-UNet maintains reasonable performance when tested on different datasets. When trained on STARE and tested on DRIVE, EFDG-UNet consistently outperformed all comparison methods across all metrics. When trained on DRIVE and tested on STARE, EFDG-UNet achieved superior performance in accuracy, specificity, and AUC, though with slightly lower sensitivity. These results indicate that EFDG-UNet can effectively adapt to different data distributions and maintain robust performance, making it a reliable model for retinal vessel segmentation in practical clinical applications where training and testing data may come from different sources.
Conclusion
EFDG-UNet achieves competitive results in retinal vessel segmentation across multiple metrics. The model balances accuracy, sensitivity, and specificity, with improved performance in capturing small vessels and segmenting background regions. Compared to baseline methods, EFDG-UNet shows improvements across multiple evaluation metrics, particularly in accuracy, AUC, and specificity.
However, EFDG-UNet also has some limitations. Although the model performs well across several metrics, its sensitivity remains lower than that of some advanced segmentation models in certain cases. This suggests that EFDG-UNet may require further optimization to enhance its ability to capture fine details, particularly for certain types of small vessels or noisy data. Additionally, despite the integration of various modules to enhance feature extraction, EFDG-UNet may still need improvements in its noise robustness when handling highly complex or noisy data.
Future research will focus on further optimizing the EFDG-UNet architecture, particularly in terms of sensitivity and noise resistance. We plan to incorporate more attention mechanisms and self-supervised learning strategies to improve detection of minute vessels and detailed regions. Furthermore, we will explore cross-dataset training and evaluation methods to assess the model’s generalization capabilities. This approach will help evaluate the adaptability of EFDG-UNet in different scenarios and prevent the model from overfitting to specific datasets.
Data availability
The datasets utilized in this study can be accessed via the following links: https://researchinnovation.kingston.ac.uk/en/datasets/chasedb1-retinal-vessel-reference-dataset-4/ (CHASE_DB1), https://www.kaggle.com/datasets/andrewmvd/drive-digital-retinal-images-for-vessel-extraction (DRIVE), and http://cecas.clemson.edu/~ahoover/stare/ (STARE).
References
Allon, R. et al. Retinal microvascular signs as screening and prognostic factors for cardiac disease: A systematic review of current evidence. Am. J. Med. 134(1), 36–47 (2021).
Moss, H. E. Retinal vascular changes are a marker for cerebral vascular diseases. Curr. Neurol. Neurosci. Rep. 15(7), 40 (2015).
Wang, Z. et al. Hypertensive retinopathy can predict stroke: A systematic review and meta-analysis based on observational studies. J. Stroke Cerebrovasc. Dis. 33(11), 107953 (2024).
Jin, K. et al. Fives: A fundus image dataset for artificial intelligence based vessel segmentation. Sci. Data 9(1), 475 (2022).
Ronneberger, O., Fischer, P. & Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention. 234–241 (2015).
Chandhakanond, P. & Aimmanee, P. Diabetic retinopathy detection via exudates and hemorrhages segmentation using iterative NICK thresholding, watershed, and Chi2 feature ranking. Sci. Rep. 15(1), 5541 (2025).
Ma, Z. & Li, X. An improved supervised and attention mechanism-based U-Net algorithm for retinal vessel segmentation. Comput. Biol. Med. 168, 107770 (2024).
Gegundez-Arias, M. E. et al. A new deep learning method for blood vessel segmentation in retinal images based on convolutional kernels and modified U-Net model. Comput. Methods Programs Biomed. 205, 106081 (2021).
Zhang, J. et al. DUNet: A deformable network for retinal vessel segmentation. Knowl.-Based Syst. 178, 149–162 (2019).
Mou, L., Zhao, Y., Chen, L. & Cheng, J. CS-Net: Channel and spatial attention network for curvilinear structure segmentation. IEEE J. Biomed. Health Inform. 25(2), 371–382 (2021).
Kamran, S. A., Akram, M. U., Hassan, M. & Khalid, S. RV-GAN: Segmenting retinal vessels by balancing adversarial and pixel-wise loss. IEEE Access. 8, 172736–172747 (2020).
Zhou, T., Yang, F. & Zhang, S, et al. Collaborative learning of semi-supervised segmentation and classification for medical images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2079–2088 (2019).
Galdran, A. et al. State-of-the-art retinal vessel segmentation with minimalistic models. Sci. Rep. 12(1), 6174 (2022).
Lin, J. et al. Stimulus-guided adaptive transformer network for retinal blood vessel segmentation in fundus images. Med. Image Anal. 89, 102929 (2023).
Wang, H., Chen, Y. & Chen, W., et al. Serp-mamba: Advancing high-resolution retinal vessel segmentation with selective state-space model. IEEE Trans. Med. Imaging (2025).
Lamrani, D., Cherradi, H. & Elasri, A., et al. Enhanced retinal blood vessels segmentation using deep learning and residual network. Intell. Based Med. 100263 (2025).
Oktay, O., Schlemper, J. & Folgoc, L.L., et al. Attention u-net: Learning where to look for the pancreas. arXiv:1804.03999 (2018).
Zhuang, J. LadderNet: Multi-path networks based on U-Net for medical image segmentation. arXiv:1810.07810 (2018).
Jha, D., Smedsrud, P. H. & Riegler, M. A., et al. Resunet++: An advanced architecture for medical image segmentation. In 2019 IEEE International Symposium on Multimedia (ISM). IEEE 225–2255 (2019).
Wang, J. et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 43(10), 3349–3364 (2020).
Zhang, S., Fu, H. & Yan, Y., et al. Attention guided network for retinal image segmentation. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, October 13–17, 2019, Proceedings, Part I 22. Springer 797–805 (2019).
Huang, H., Lin, L. & Tong, R., et al. Unet 3+: A full-scale connected unet for medical image segmentation. In ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE 1055–1059 (2020).
Wang, W., Zhong, J. & Wu, H., et al. Rvseg-net: An efficient feature pyramid cascade network for retinal vessel segmentation. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part V 23. Springer 796–805 (2020).
Zhang, M., Yu, F. & Zhao, J, et al. BEFD: Boundary enhancement and feature denoising for vessel segmentation. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part V 23. Springer 775–785 (2020).
Guo, C., Szemenyei, M. & Yi, Y., et al. Sa-unet: Spatial attention u-net for retinal vessel segmentation. In 2020 25th International Conference on Pattern Recognition (ICPR). IEEE 1236–1242 (2021).
Samuel, P. M. & Veeramalai, T. VSSC Net: Vessel specific skip chain convolutional network for blood vessel segmentation. Comput. Methods Programs Biomed. 198, 105769 (2021).
Wu, H. et al. Scs-net: A scale and context sensitive network for retinal vessel segmentation. Med. Image Anal. 70, 102025 (2021).
Zhong, X. et al. Do you need sharpened details? Asking MMDC-Net: Multi-layer multi-scale dilated convolution network for retinal vessel segmentation. Comput. Biol. Med. 150, 106198 (2022).
Sun, Q. et al. UCR-Net: U-shaped context residual network for medical image segmentation. Comput. Biol. Med. 151, 106203 (2022).
Xu, Y. & Fan, Y. Dual-channel asymmetric convolutional neural network for an efficient retinal blood vessel segmentation in eye fundus images. Biocybern. Biomed. Eng. 42(2), 695–706 (2022).
Deng, X. & Ye, J. A retinal blood vessel segmentation based on improved D-MNet and pulse-coupled neural network. Biomed. Signal Process. Control 73, 103467 (2022).
Jin, S. et al. A novel medical image segmentation approach by using multi-branch segmentation network based on local and global information synchronous learning. Sci. Rep. 13(1), 6762 (2023).
Xu, Q. et al. DCSAU-Net: A deeper and more compact split-attention U-Net for medical image segmentation. Comput. Biol. Med. 154, 106626 (2023).
Yang, B. et al. SDDC-Net: A U-shaped deep spiking neural P convolutional network for retinal vessel segmentation. Digit. Signal Process. 136, 104002 (2023).
Zhang, H. et al. BCU-Net: Bridging ConvNeXt and U-Net for medical image segmentation. Comput. Biol. Med. 159, 106960 (2023).
Li, J. et al. GDF-Net: A multi-task symmetrical network for retinal vessel segmentation. Biomed. Signal Process. Control 81, 104426 (2023).
Chen, Q. et al. CFFANet: Category feature fusion and attention mechanism network for retinal vessel segmentation. Multimedia Syst. 30(6), 1–15 (2024).
Lv, N. et al. TCDDU-Net: Combining transformer and convolutional dual-path decoding U-Net for retinal vessel segmentation. Sci. Rep. 14(1), 25978 (2024).
Ming, L. & Li, Q. DMSU-Net++: A dual multiscale retinal vessel segmentation method based on improved U-Net++. PLoS ONE 20(7), e0325625 (2025).
Hu, H. et al. Multi-scale vision Mamba-UNet: A Mamba-based method for retinal vessel segmentation. Biomed. Signal Process. Control 112, 108435 (2026).
Liu, W. et al. Full-resolution network and dual-threshold iteration for retinal vessel and coronary angiograph segmentation. IEEE J. Biomed. Health Inform. 26(9), 4623–4634 (2022).
Alom, M. Z., Hasan, M. & Yakopcic, C., et al. Recurrent residual convolutional neural network based on u-net (r2u-net) for medical image segmentation. arXiv:1802.06955 (2018).
Gong, Z., et al. CS-Net: a two-step epithelium tissue segmentation regression network with CS-gate attention on histology images. Available at SSRN 4202295 (2022).
Yuan, Y. et al. Multi-level attention network for retinal vessel segmentation. IEEE J. Biomed. Health Inform. 26(1), 312–323 (2021).
Qu, Z. et al. Tp-net: Two-path network for retinal vessel segmentation. IEEE J. Biomed. Health Inform. 27(4), 1979–1990 (2023).
Huang, W. & Fengting, L. HiDiffSeg: A hierarchical diffusion model for blood vessel segmentation in retinal fundus images. Expert Syst. Appl. 253, 124249 (2024).
Acknowledgements
Thank you to the individuals and organizations who have contributed to this paper.
Funding
This research was supported by the Jilin Provincial Department of Science and Technology Major Project (Project No.: SKL202502024JC).
Author information
Authors and Affiliations
Contributions
Y.Y. and D.Y. conceived and designed the study. Y.Y. and Y.L. developed the EFDG-UNet architecture and implemented the adaptive gated residual block. Y.L. and J.W. designed and implemented the feature fusion hub with Transformer-based attention mechanism. H.Z. and W.Z. conducted the experiments on DRIVE, CHASE_DB1, and STARE datasets. X.C. and T.L. performed the statistical analysis and evaluation metrics calculation. W.L. prepared the figures and tables. Y.Y., Y.L., and D.Y. wrote the main manuscript text. J.W. and H.Z. contributed to the methodology section. W.Z. and X.C. contributed to the results and discussion sections. T.L. and W.L. assisted with data preprocessing and validation. D.Y. supervised the project and provided critical revisions. All authors reviewed and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yang, Y., Li, Y., Wang, J. et al. Enhanced feature dynamic fusion gated UNet for robust retinal vessel segmentation. Sci Rep 16, 3767 (2026). https://doi.org/10.1038/s41598-025-33694-0
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-33694-0
