
Abstract
Medical imaging often captures multiple two-dimensional views of three-dimensional anatomic structures, but most artificial intelligence (AI) models analyze two-dimensional data. Here we show that integrating multiple imaging views using a single AI model can improve diagnostic performance. We developed a deep neural network (DNN) architecture that combines information from multiple video views simultaneously. Using echocardiogram data from the University of California, San Francisco, and the Montreal Heart Institute, we applied our multiview DNN approach for three primary demonstration tasks: detecting any left or right ventricular abnormality, diastolic dysfunction, and substantial valvular regurgitation. Across various tasks, our multiview DNNs improved discrimination as measured by the area under the receiver operating characteristic curve by 0.06–0.09 compared to DNNs trained on any single view. This demonstrates that AI models that can combine information from multiple imaging views simultaneously can better capture complex anatomy and physiology for certain tasks, underscoring the value of a multiview paradigm for AI in medical imaging.
Similar content being viewed by others
Main
Medical imaging plays a critical role in cardiovascular medicine, providing insights into anatomic structure, hemodynamics, and function. Although cardiac anatomic structure is three-dimensional (3D), most imaging modalities capture multiple two-dimensional (2D) tomographic image slices of 3D anatomic structures. These multiple 2D slices, also called views, carry complementary information that physicians must interpret to reconstruct a 3D mental model, enabling optimal assessment of the structural or functional characteristics that distinguish disease from non-diseased states. Cardiac ultrasound, or echocardiography (echo), is an example of a common imaging modality that often captures >100 distinct views that together provide 3D information about the heart beating in time.
Advances in artificial intelligence (AI) methods1,2,3 have facilitated analysis of medical imaging, particularly computer vision which uses AI to analyze raw images and videos. The advent of deep neural networks (DNNs) provided the first major advance by enabling analysis of an image’s raw pixels, followed more recently by the development of DNNs that analyze raw video data by integrating information over time across the sequential images of a video4,5,6. Such DNNs trained using either image or video data have been successfully applied in medicine to detect various diseases7,8,9,10,11,12,13,14. However, these existing DNN architectures are poorly suited to integrate multiple 2D imaging views simultaneously as physicians do to accurately comprehend a 3D structure. In cardiac echo, for example, reliable diagnosis most often depends upon the corroboration of information contained across multiple echo views. An interpreting cardiologist routinely performs this mental integration of information as each view captures complementary information from a different perspective.
In this Article, we developed a purpose-built multiview DNN architecture that is specifically designed to integrate 3D video information from multiple complementary 2D imaging views mirroring how a physician interprets 3D anatomic structures. Our multiview DNN architecture simultaneously accepts inputs from multiple views while also being designed to integrate information between these views through dedicated DNN layers. Our multiview DNN architecture uses a mid-fusion approach to combine features from each input view at an intermediate stage enabling the network ample opportunity to integrate inter-view information. Whereas the primary innovation of image-based DNNs was integration of the 2D spatial information of raw image pixels, and the primary innovation of video-based DNNs was integration of temporal information across time (captured by the sequence of frames), our multiview DNN enables integration of spatiotemporal information from multiple views simultaneously to accomplish the target task.
Here we applied the multiview DNN architecture to three primary demonstration tasks in cardiac echo, a commonly obtained medical imaging modality. We show that our multiview DNN architecture readily outperforms standard video-based DNNs trained on any single view for each of the three tasks, which include both standard echo diagnoses and “novel” echo diagnoses—or diagnoses that cannot typically be made by cardiologists using echo data alone.
Results
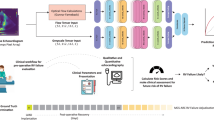
The multiview DNN architecture takes in multiple imaging views at the same time (Fig. 1) and achieves the task(s) it is trained for by learning patterns both within each raw video view and across the views together (Fig. 2). Cardiac echo diagnosis typically requires triangulating information simultaneously across multiple views making it an ideal demonstration modality for the multiview DNN. We trained each of the three demonstration multiview DNNs using three predefined echo views (the views most clinically suitable for each task) obtained from the same echo study for each patient. Training and internal validation echo data was derived from adult patients that received transthoracic echoes from 2012 to 2020 at the University of California, San Francisco (UCSF). All videos were masked and cropped to exclude any burned-in text and annotations and resized to 224 × 224 pixels. We first trained a video-based DNN view classifier to distinguish between 21 echo view classes and another video-based DNN doppler classifier to detect the presence of color doppler within the video. Performance metrics for these view/doppler DNN classifiers are provided in the supplement (Extended Data Fig. 1). We then applied the view and doppler DNN classifiers to all echos in the UCSF dataset to identify the specific echo videos to train and validate each of the three demonstration tasks.

Each single imaging view contains detailed 2D information about a slice (tomograph) of a 3D structure, such as the heart. Multiple 2D tomographic views often contain distinct and complementary information about different anatomic structures contained within that view. To obtain the most comprehensive assessment of any single diagnosis within a complex organ such as the heart, it is necessary to simultaneously consider information from multiple views at once. This is routinely performed by cardiologists who interpret echocardiograms of the heart. This practice of simultaneously considering differential information from multiple imaging views provides the conceptual basis for the development of the multiview DNN architecture. Images copyright Atif Qasim; reproduced with permission.

Multiview neural network architecture and data preprocessing for the demonstration imaging modality of cardiac echo. a, All videos from a single echo study undergo standardized preprocessing (masking to exclude nonmoving pixels and pixels outside the ultrasound region, cropping to ultrasound image region and resizing to 224 × 224 pixels). Each echo video’s view and presence of color-doppler signal are detected using trained view-classification and doppler-detection DNNs. b, One echo video from each predefined echo view (A4c, A2c, and PLAX) accepted by the multiview DNN is selected from the same echo study; these three echo videos are used as simultaneous inputs into the multiview DNN classifier to predict the target task. Embeddings from each video are passed through individual convolutional encoder blocks (Conv1–Conv3) before they are concatenated along a new dimension and then passed through two more convolutional blocks (Conv4 and Conv5) that perform cross-view convolutions to integrate spatiotemporal information between views before the final prediction is made.
Our multiview DNN architecture uses 3D convolutions first to integrate spatial and temporal information across multiple frames of a single video15. The multiview DNN architecture is designed around a video-based DNN backbone—here we used the “Expand 3D”, or “X3D”15 video-based DNN—which allows for other DNN backbones to be used as suitable for future applications. The core innovation of our multiview DNN architecture is the use of dedicated convolutional neural network layers that integrate information between all input views to accomplish the target task (Fig. 2). This allows the DNN to learn patterns within each input video and also the patterns between multiple videos, such as the motion of a heart valve captured over time from multiple views. Additional technical details are described in Methods.
To examine the performance of our multiview DNN architecture, we trained separate single-view DNNs representing the current state of the art7,16,17,18 for each individual view for our three echo tasks. We selected two “standard” composite echo tasks where accurate manual interpretation requires corroboration from more than one view: identification of left or right ventricular (LV/RV) abnormalities and identification of substantial valvular regurgitation (moderate severity or greater in the tricuspid, mitral, or aortic valves). We also selected one “novel” echo task that cannot typically be interpreted via physician manual interpretation using non-doppler, brightness mode (B-mode) echo: identifying diastolic dysfunction. There is no standard approach for cardiologists to manually interpret diastolic dysfunction using non-doppler B-mode echo videos alone, making this a novel AI-enabled echo task.
To derive reference-standard labels for training and testing for each task, we obtained assessments from clinical echo reports that were interpreted by level-3 echo board-certified cardiologists in the UCSF echo lab. Ventricular abnormality was defined as positive if there was any abnormality in LV/RV size or function19. Diastolic dysfunction was defined as any diastolic dysfunction (grades 1–4) as determined by American Society of Echocardiography (ASE) guidelines20,21. Substantial valve regurgitation was defined as moderate or greater regurgitation in any of the mitral, tricuspid, or aortic valves according to ASE guidelines22. For the ventricular abnormality and diastolic dysfunction multiview DNNs, the three input echo views used were non-doppler apical four-chamber (A4c), apical two-chamber (A2c), and parasternal long-axis (PLAX) views; for valve regurgitation, the input echo views were color-doppler A4c, apical five-chamber (A5c), and PLAX views.
Multiview and single-view performance on composite endpoints
To train the LV/RV abnormality multiview DNN, we identified a cohort of 41,790 echo studies from 20,504 patients at UCSF that had all LV and RV measurements available in the clinical echo report. The cohort had a mean age of 63 years (standard deviation (s.d.) 17 years), and 50.3% were female (Table 1). The prevalence of any LV/RV abnormality in this cohort was 24.5%. Data were split by patients into training, development, and testing datasets. Hyperparameters and model checkpoints were chosen based on the development dataset, and final performance metrics were calculated on the held-out test dataset. Additional details are provided in Methods.
In the held-out UCSF test dataset for LV/RV abnormality, the multiview DNN achieved an area under the receiver operating characteristic curve (AUC) of 0.907 (95% confidence interval (CI) 0.900–0.914) to detect LV/RV abnormality, and sensitivity and specificity were 0.810 and 0.840, respectively (Table 2). To provide comparison to single-view DNNs, we trained three separate X3D video-based single-view DNNs for each of the three echo views using the same dataset. The best single-view DNN for ventricular abnormality used the A4c view and achieved an AUC of 0.851 (95% CI 0.841–0.861), followed by PLAX with an AUC of 0.848 (95% CI 0.838–0.857) and then A2c with an AUC of 0.783 (95% CI 0.771–0.795) (Table 2 and Fig. 3). The multiview DNN for ventricular abnormality had a statistically significantly higher AUC than any single-view DNN and outperformed the best single-view A4c DNN AUC by 0.056 (Table 2). The ventricular abnormality multiview DNN F1 score was 0.695 (95% CI 0.679–0.710), which was higher than the F1 score for any single-view DNN (Table 2). As an additional comparator, we took the arithmetic average of the output scores from the three single-view DNNs and compared its discrimination performance to the multiview DNN. This is considered a “late fusion” approach and does not have the benefit of the DNN learning from multiple views simultaneously like our multiview DNN but is less computationally expensive and potentially easier to train compared to a multiview DNN. The average of three single-view DNNs had an AUC of 0.899 (95% CI 0.880–0.898), which was significantly higher than the AUC of any individual single-view DNN and statistically significantly lower than the AUC of the multiview DNN (Table 2 and Fig. 3; P < 0.001).

a–c, Receiver operating characteristic (ROC) curves showing overall performance of DNNs to predict LV/RV ventricular abnormality (a), diastolic dysfunction (b), and valve regurgitation (c) for both multiview DNNs (blue line) and single-view DNNs (orange, green, and red lines). Also shown is the ROC curve for the arithmetic average of the three single-view DNN outputs (purple line). The dotted line represents AUC of 0.5.
Our second echo task was the novel composite task to identify the presence of diastolic dysfunction using non-doppler B-mode echo videos; these non-doppler videos are not used by cardiologists for interpretation of diastolic dysfunction making this a novel echo task. To develop the multiview DNN for diastolic dysfunction, we identified a cohort of 11,411 echo studies from 6,643 UCSF patients that had clinical interpretations of diastolic dysfunction in the echo report. The cohort had a mean age of 65 years (s.d. 16 years), and 50.3% were female (Table 1). The prevalence of any diastolic dysfunction in this cohort was 68.3%. In the held-out UCSF test dataset for diastolic dysfunction, the multiview DNN achieved an AUC of 0.836 (95% CI 0.821–0.851) to detect any diastolic dysfunction, and sensitivity and specificity were both ~0.76. (Table 2). As above, we also trained single-view X3D DNNs for diastolic dysfunction with each of the three views separately using the same dataset. The best single-view DNN performance to detect diastolic dysfunction used the PLAX view, with an AUC of 0.749 (95% CI 0.730–0.767) (Table 2), followed by A4c with an AUC of 0.708 (95% CI 0.688–0.727). The multiview DNN for diastolic dysfunction had a statistically significantly higher AUC than any single-view DNN and outperformed the best single-view PLAX DNN AUC by 0.087. The average of three single-view DNNs had an AUC of 0.783 (95% CI 0.771–0.794). This was significantly higher than the AUC for any individual single-view DNN and was statistically significantly lower than the AUC of the multiview DNN (Table 2 and Fig. 3; P < 0.001).
We then applied our multiview DNN architecture to detect the presence of any substantial valve regurgitation using color doppler echo videos. To develop a multiview DNN for valve regurgitation, we obtained 27,692 echo studies from 18,573 UCSF patients that also had clinical interpretations of valve regurgitation available in the clinical echo report. The cohort had a mean age of 61 years (s.d. 17 years), and 50% were female (Table 1). The prevalence of any valve abnormality in this cohort was 11.3%. In the held-out UCSF test dataset for valve regurgitation, the multiview DNN achieved an AUC of 0.904 (95% CI 0.892–0.915) to detect any substantial valve regurgitation, and sensitivity and specificity were both ~83% (Table 2). We also trained single-view X3D video-based DNNs for valve regurgitation with each of the three views separately using the same dataset. The best single-view DNN performance to detect valve regurgitation was obtained from the A4c view, with an AUC of 0.836 (95% CI 0.821–0.852; Table 2), followed by the PLAX view with an AUC of 0.823 (95% CI 0.806–0.839). The multiview DNN for valve regurgitation had a statistically significantly higher AUC than any single-view DNN and outperformed the best single-view A4c DNN AUC by 0.068 (Table 2). The average of three single-view DNNs had an AUC of 0.891 (95% CI 0.879–0.903), which was significantly higher than the AUC of any individual single-view DNN and was statistically significantly lower than the AUC of the multiview DNN (Table 2 and Fig. 3; P = 0.02).
External validation of the multiview DNNs
To test the generalizability of our trained multiview DNN algorithms to external data from another institution, we measured the performance of our multiview DNNs on echos obtained from the Montreal Heart Institute (MHI) in Canada. This external validation dataset consisted of adult MHI echos acquired during 2022 (Extended Data Table 1). Labels were extracted from MHI clinical echo reports according to guideline criteria. Only linear measurements were available in MHI echos compared to volumetric criteria at UCSF for LV/RV abnormalities. In addition, the prevalence of cardiac abnormalities differed in the MHI test dataset versus UCSF: low LVEF (LV ejection fraction (EF)) was more common, and there was far less higher-grade diastolic dysfunction and abnormal RV function (Extended Data Table 1). We preprocessed MHI echo data and classified views using the same preprocessing algorithms. Upon reviewing the performance of the UCSF view classifier on 350 randomly selected MHI echo videos, the view classifier performed well across our target views with precision (positive predictive value (PPV)) of 100% for A4c, 83.3% for PLAX, 88.5% for A2c, and 81.8% for A5c, with a global accuracy of 79.14%.
On this MHI external validation dataset, the LV/RV abnormality multiview DNN achieved an AUC of 0.909 (95% CI 0.896–0.922; Table 3), and the valve regurgitation multiview DNN had an AUC of 0.924 (95% CI 0.890–0.954), both of which were comparable to DNN performance in the UCSF test dataset with overlapping 95% CIs. The diastolic dysfunction multiview DNN achieved an AUC of 0.791 (95% CI 0.765–0.817) in the MHI dataset, showing reasonable generalization with modest performance degradation compared to the UCSF test dataset (Table 3). In the MHI external dataset, multiview DNNs had higher AUCs than all single-view DNNs and the average of three single-view DNNs. However, for valve regurgitation, which was the smallest external validation cohort, the higher multiview DNN AUC was not statistically significantly higher than single-view DNNs (Table 3).
Multiview and single-view performance on individual components of composite endpoints
Composite endpoints, such as detection of any LV/RV abnormality, may inherently benefit from inclusion of multiple imaging views as each view contributes unique and complimentary information to the composite task. Indeed, we selected composite tasks because the multiview architecture may be best suited for such tasks. However, to investigate the benefit of our multiview DNN approach for more anatomically specific tasks, we trained single-view and multiview DNNs for individual components of our composite endpoints in the UCSF dataset: LV size, LVEF, RV function, RV size, mitral regurgitation, aortic regurgitation, and tricuspid regurgitation. As with previous experiments, single-view models were trained using videos from the same echo studies as multiview models but using only a single view (A4c, A2c, or PLAX for LV/RV abnormalities; A4c, A5c, or PLAX with color Doppler for valvular regurgitation). In the held-out UCSF test datasets for all seven tasks, the multiview DNNs consistently outperformed single-view DNNs, with the exception of tricuspid regurgitation (Table 4). The tricuspid regurgitation multiview DNN had a borderline non-significant difference with A4c DNN (Bonferroni-adjusted P = 0.057) and a non-significant difference with the PLAX DNN.
Furthermore, we examined how the composite task multiview DNNs performed within substrata of the UCSF test set for each component task. Overall for the ventricular abnormality, multiview DNN performance remained high (AUC > 0.90) for all abnormalities of LV/RV size or function (Extended Data Table 2). The diastolic dysfunction multiview DNN showed highest performance for grade 4 diastolic dysfunction, and the valve regurgitation multiview DNN showed highest performance for mitral regurgitation (Extended Data Table 2). Results in substrata of the MHI test dataset are shown in Extended Data Table 3.
Additional examination of multiview DNN performance
Depending on the intended clinical application, the performance of a trained DNN can be modified to favor a higher sensitivity or specificity by selecting a different threshold. Extended Data Table 4 shows sensitivity-optimized and specificity-optimized multiview DNN performance in the UCSF test set achieved by fixing sensitivity or specificity at 0.80.
Multiview DNN performance was similar in strata of sex and age groups in UCSF (Extended Data Table 5). The performance of the multiview DNN for diastolic dysfunction also did not vary substantially when stratifying by LVEF (≥50% versus <50%) (Extended Data Table 6), suggesting that the DNN identified predictors of diastolic dysfunction independently of EF; this is important to confirm because of the association between reduced EF and diastolic dysfunction. Multiview DNN performance was similar when inference was run starting at a random frame of the video clip, rather than the first frame (Extended Data Table 7); although the valve model showed a slight shift in calibration with random frame data, overall discrimination did not change. Performance was also consistent across strata of echo machine manufacturer (Extended Data Table 8).
Explainable AI techniques allow for the identification of patterns within input echo videos that the DNN learned as being important to make its predictions, possibly highlighting physiologic associations with the target task. We used the guided grad-CAM technique (Gradient-weighted Class Activation Mapping)23 to visualize the pixels within images of a video that most strongly contribute to a prediction from a trained DNN (Fig. 4). We present both the grad-CAM and guided grad-CAM visualizations, as the former captures the general image regions influencing the prediction while the latter refines these maps to highlight pixel-level detail. Guided grad-CAM maps of the ventricular abnormality DNN tended to focus on both pixels of the right and left ventricular myocardium, with some preference for the left ventricle. Highlighted pixels for the diastolic dysfunction DNNs focused on the left atrium, but also of the LV myocardium and right atrium. Guided grad-CAM maps for the valvular regurgitation DNN highlighted valve tissue areas as well as the color doppler signal of valvular regurgitation, when present. It is important to appreciate, however, that current explainability techniques such as guided grad-CAM only provide a limited view into DNN function and thus should be considered accordingly. We also show example grad-CAM and guided grad-CAM images from false-positive and low-confidence predictions as comparators (Extended Data Fig. 2).

Grad-CAM and guided grad-CAM heat maps showing the class-weighted activations of the final convolutional layer in our single-view DNNs for (top to bottom) LV/RV abnormalities (VD), diastolic dysfunction (DD), and valvular regurgitation (Valve) using A2c, A4c, and PLAX views for VD and DD, and using A4c, A5c, and PLAX views for valve. For each panel, the left image is the original echo frame, the middle image is the grad-CAM, and the right image is the guided grad-CAM. Brighter red (grad-CAM) or pink (guided grad-CAM) areas indicate areas of greater importance for that DNN’s prediction from that frame.
Discussion
In this study, we developed and validated a multiview DNN architecture that integrates information from multiple input imaging views simultaneously, providing an opportunity to optimize AI algorithms for 3D medical imaging broadly. Across our primary demonstration tasks, our multiview DNN outperformed single-view DNNs improving overall discrimination by 0.06–0.09 AUC. In addition, we showed that by averaging outputs from three separately trained single-view DNNs, discrimination was significantly higher compared to any single-view DNN but also that the multiview DNN had statistically significantly better discrimination than the average of three single-view DNNs. Performance of the multiview DNNs remained robust across various substrata and generalized well to data from an external institution with modest performance degradation for diastolic dysfunction models; this may be partially explained by the difference in the prevalence of diastolic dysfunction at MHI. By integrating spatiotemporal information across multiple imaging video views, the multiview DNN can learn how the complementary information captured by each view relates to information in other views in a disease-specific manner, mirroring how physicians interpret complex medical imaging data. Considering multiple imaging views simultaneously, either through multiview DNN architectures or by averaging several single-view DNNs, provides improvements across various disease tasks, underscoring the value of a multiview paradigm when training AI models for medical imaging.
Medical imaging has always faced the challenge of capturing 2D tomographic slices of 3D anatomic structures. For imaging modalities such as echo, physicians are accustomed to reviewing and integrating findings from all available 2D views of a structure into a 3D (or higher dimensional) mental model before finalizing a final diagnostic impression. This challenge has prompted the development of technology such as 3D ultrasound24 which assists physician diagnosis by depicting 3D anatomic contours. However, 2D echo videos remain the primary diagnostic format, owing in part to limitations in 3D reconstruction, smoothing, artifacts, and spatial resolution25. Therefore, mental integration of information from multiple 2D imaging views remains the standard of care upon which most physician-reviewed echo diagnoses are made. To date, AI has primarily been used to analyze one 2D view at a time—from either images or videos—which limits an AI algorithm’s ability to learn disease-relevant information between views. Therefore, DNN architectures that can integrate information across multiple high-resolution views represent an important step toward maximizing AI performance in medical imaging.
In the case of echo, nearly every important diagnosis necessitates considering information from more than one view because the information from any single view tells only part of the story. For example, for the assessment of LV size or function, the standard A4c view captures the inferoseptal and anterolateral walls of the left ventricle, whereas the A2c view captures the anterior and inferior walls of the left ventricle (Fig. 1). It is not uncommon for the function of LV walls to appear completely normal in one view but for substantial dysfunction to be present in LV walls visible only in another view—this is called “regional myocardial wall motion abnormality” and is often caused by myocardial ischemia26. For composite echo tasks like LV/RV abnormality and diastolic dysfunction, our results suggest that the multiview DNN not only learns the best views to accomplish each subtask but also likely learns interrelated information between features from each view to achieve higher overall performance than any single-view DNN or the late-fusion average of three single-view DNNs. We would highlight, however, that the average of three single-view DNNs does provide a viable alternative to training a multiview DNN that improves performance beyond a single-view DNN and may be less computationally expensive.
As we observed, the performance gains provided by the multiview DNN architecture vary by task and would be expected to provide the greatest benefit for tasks that require simultaneous consideration of complementary inputs. It also may provide similar benefit for imaging modalities beyond echo. For example, we previously used the same DNN architecture to train multiview DNNs to estimate LV systolic function from multiple angiographic videos simultaneously27. We showed that for this “superhuman” task of estimating cardiac pumping function from left coronary artery angiogram videos, using the multiview DNN to consider multiple views simultaneously substantially outperformed DNNs that only considered one angiogram view. Corroborating our present results in echo videos, these results together suggest that for certain imaging tasks multiview DNNs trained with more than one input view can meaningfully improve performance over single-view DNNs alone. Future work should examine how multiview DNN architectures may assist other medical tasks or imaging modalities.
Prior efforts that used DNNs to analyze more than one echo view to accomplish a single task have most commonly done so by combining outputs from DNNs at a late stage. The simplest of these approaches takes the arithmetic average of the predictions from multiple separate single-view DNNs, similar to our reported average of three single-view DNNs. A slightly more complex approach combines representations derived from single-view DNNs just before a final network layer that outputs the final diagnosis11,28. These are both considered late fusion approaches as they fuse representations of separate single-view DNNs at a late stage. Late fusion approaches do not enable the DNNs to learn meaningful patterns or interactions between the views. Another approach that has been taken recently has been “view-agnostic” approaches that take embeddings from arbitrary numbers of views from an echo study to predict echo measurements or report characteristics29,30. In these approaches, all the available views in an echo study are considered together regardless of the target task. By contrast, our multiview DNN accepts the three input views most appropriate for the target task, and then performs multiple convolutions across the views with a mid-fusion approach. This enables the DNN to discover interrelated patterns between the raw videos from each view that most effectively accomplish the target task. Mid fusion approaches can theoretically increase predictive performance by integrating complementary and interrelated features from multiple input types more thoroughly28,31. Our results support this by showing that multiview DNNs outperform the late-fusion averaged single-view DNN performance for most tasks. However, the degree of performance boost provided by the multiview DNN will likely vary depending on the target task and the available training data. While our multiview DNN was significantly better for all of our composite tasks (Table 2), for the individual task of tricuspid regurgitation, the single-view DNNs for A4c and A5c performed similarly well, with A4c having a higher AUC (Table 4). It is also worth noting that the PLAX view does not directly visualize tricuspid regurgitation; therefore, the PLAX DNN likely discriminates tricuspid regurgitation based on correlative echo features. Interestingly, in our external validation MHI dataset, the valve regurgitation single-view and multiview DNN AUCs were all higher than observed in our internal UCSF test dataset; in this context, the higher multiview DNN AUC was not statistically significantly higher than the single-view DNN’s AUCs (Table 4). Overall, our multiview DNN approach and results underscore the concept that for certain medical imaging tasks, optimal AI model training involves considering multiple views simultaneously.
Previously published DNNs for similar echo tasks have typically used single-view models and have not attempted composite echo tasks. Multiview DNNs offer the possibility to accomplish these higher-level composite tasks that may be less ideal to perform using a single view because the necessary information is not contained by any single view. Our work examines DNN performance for composite echo tasks—such as any LV/RV dysfunction or any valve regurgitation—using a single end-to-end multiview DNN. To classify LV dysfunction, ref. 7 trained a video-based model for the single A4c view and reported an AUC of 0.97 to detect reduced LV function, and ref. 16 reported similar results with an earlier image-based DNN classifier. Our LV/RV abnormality multiview DNN identifies abnormal LV function as one component of its composite task but simultaneously also interrogates the three other abnormalities of highest clinical relevance for the left ventricle and right ventricle across three echo views. Together, the multiview DNNs for LV/RV function and valve regurgitation could be clinically used to triage echos as being broadly normal or abnormal, with abnormal-predicted echos receiving more urgent physician review. Single-view DNNs have previously been used for many prior disease identification tasks like amyloid and hypertrophic cardiomyopathy12,16, wall motion abnormalities13, LV hypertrophy12, cardiac constriction and restriction14, myocardial strain16,32, RV function33, and atrial septal defect detection34. Our results suggest that some of these tasks may benefit from a multiview DNN approach, formulated either as individual or composite tasks.
Our study is best interpreted in the context of its limitations. The primary technical limitation of training multiview DNNs is the higher input dimensionality compared to single-view DNNs, which has several implications. First, substantially greater amount of data are often required to adequately train a multiview DNN compared to single-view DNNs for a similar task. In addition, only studies containing all three views needed by the multiview DNN can be used in either training or inference. In our experiments, the proportion of studies excluded due to missing views was 10.9% for LV/RV abnormality, 6.1% for diastolic dysfunction, and 56.1% for valve regurgitation (mitral valve, aortic valve, and tricuspid valve). This limitation may make it harder to train multiview DNNs for rare diseases. Second, given their high input dimensionality, multiview DNNs require greater computational capacity and graphical processing unit memory to train. In this context, the average of the three single-view DNN outputs may provide an attractive alternative requiring lower data and computational capacity despite the lower overall performance compared to a multiview DNN. Multiview DNNs are best suited for specific tasks or clinical settings where it is imperative to consider the information from multiple input views simultaneously. Another limitation is that our definition of “substantial valvular regurgitation” does not include the pulmonic valve; we chose not to include this because it requires a dedicated echo view that is often not clearly visualized in echo and because pulmonary regurgitation has lower clinical consequence compared to other valvular regurgitation. Discussion points are continued in the Supplementary Information.
In conclusion, we describe a general-purpose multiview DNN architecture and demonstrate that it achieves substantial performance improvements compared to single-view DNNs across a range of cardiac echo tasks. If confirmed by future work applying multiview DNNs to other imaging modalities and diseases and in multi-institutional settings, the multiview approach provides a powerful paradigm to train multiview optimized AI models for medical imaging.
Methods
Cohort selection and data sources
Our UCSF echocardiogram dataset comprised studies acquired on adult patients at UCSF between 2012 and 2020. These raw imaging data are linked with structured diagnoses and measurement data, including quantitative and qualitative measures adjudicated by level 3 echocardiographers at the UCSF echo lab. Measurement of RV parameters was standard practice in the UCSF echo lab during the study period; RV size and function labels were present for the majority of studies. Pixel data were extracted from the Digital Imaging and Communications in Medicine format, and the echo imaging region (cone) was identified by generating a mask of pixels with intensity changes over time. We then applied erosion and dilation operations to remove smaller moving elements such as electrocardiogram waveforms. Videos were then cropped to the smallest square that contained the entire echo imaging cone and resized to 224 × 224 pixels. All analyses excluded the following study types: transesophageal, intracardiac, and stress tests of any kind. This study was reviewed and received approval from the Institutional Review Boards of UCSF and the University of Montreal which waived the need to obtain informed consent in the setting of this minimal-risk retrospective record research.
To train the video-based view classifier, 6,549 echocardiograms from 1,437 patients were manually labeled. The 20 most common views were labeled, with the remainder classified as “other.” To simulate real-world data flow where all clinically obtained videos would undergo view classification, “other” was included as a trained class for the DNN. Views in the “other” class included view from transesophageal echo, color compare, split screen, among others. By training the DNN view classifier to classify 21 distinct echo views, more views than previously published image-based view classifiers, this served to reduce input variance into the DNN; this allows for discrimination, for example, between standard depth PLAX views, PLAX zoomed on the left atrium, or PLAX zoomed on the aortic valve16. This view classifier DNN achieved a mean AUC of 0.972 across the 21 classes (Extended Data Fig. 1). We trained a similar video-based DNN to classify the presence or absence of color doppler within the echo video which achieved an AUC of 0.991 (Extended Data Fig. 1).
These view/doppler-classifier DNNs automatically identified input echo videos comprising the predefined view and doppler combination for each task. We then applied these view/doppler DNN classifiers to all UCSF echos to identify the specific echo videos needed for training and validation for each of the three demonstration tasks. For the ventricular abnormality and diastolic dysfunction multiview DNNs, the three input echo views used were non-doppler A4c, A2c, and PLAX views; and for valve regurgitation, the input echo views were color-doppler A4c, A5c, and PLAX views. To ensure a fair comparison between single-view and multiview models, we first excluded all studies that were missing any required views. Both model types were trained and evaluated on videos from the same studies, the only difference being whether a model received a single view or three views as input.
For the ventricular abnormality dataset, we included all patients in our dataset with measures of ventricular function, comprising 36,023 echo studies from 11,334 patients. Of these, 2,907 patients were identified as having a ventricular abnormality, defined as having any abnormal measure of EF, LV size, RV size, or RV function. Ventricular abnormality was defined as positive if there was any abnormality in LV/RV size or function. LV size abnormality was defined as greater than mild dilation, which was LV end diastolic volume index of >86 ml m−2 for men or >70 ml m−2 for women. LV functional abnormality was defined as LVEF < 50%, measured by Simpson’s biplane approach19. RV size abnormality was defined as moderately increased or greater, and abnormal RV function was defined as moderately decreased or greater19.
For diastolic dysfunction, we included all patients with measures of diastolic dysfunction, comprising 11,341 echo studies from 6,649 patients. Diastolic dysfunction was defined as any diastolic dysfunction (grades 1–4) as determined by ASE guidelines20,21. Of these, we identified 4,774 patients showing any diastolic dysfunction measure above grade 0. Grades 1–2 included any annotation of abnormal or impaired relaxation, or increased filling pressure. Grade 3 included all pseudonormal diastolic function, and grade 4 included restrictive diastolic function.
For valve regurgitation, we included all patients with measures of valve regurgitation, comprising 27,652 echo studies from 18,533 patients. Any substantial valve regurgitation was defined as moderate or greater regurgitation in any of the mitral, tricuspid, or aortic valves according to ASE guidelines22. Of these, we identified 969 patients with mitral valve regurgitation, 329 patients with aortic valve regurgitation, and 1,299 patients with tricuspid valve regurgitation.
Our external validation dataset consisted of all echos acquired at the MHI in 2022 on patients over the age of 18 years. These studies were similarly linked to the clinical echo reports from which we obtained qualitative and quantitative reference labels. The MHI echo lab uses linear measurements (compared with volumetric measurements at UCSF), which resulted in our needing to use linear measurements to define certain “abnormal” findings at MHI, as described below. For LV function, we labelled studies with an EF < 50% to be abnormal. Studies with a basal RV size measurement >4.4 cm were labelled abnormal. Studies with a basal LV size measurement of 6.3 cm for men or 5.6 cm for women were defined to be abnormal. For RV function, abnormality was defined as more than moderately decreased function (qualitative). Diastolic function grade labels were available in MHI and followed ASE guidelines20,21. Measurement of RV parameters was standard practice in the MHI echo lab during the study period. MHI echos were processed using identical preprocessing as described above. Preprocessing and view classification performance in MHI were assessed by randomly reviewing 350 MHI clips labelled by the UCSF-trained view classifier. The view classifier performed well across our target views with precision (PPV) of 100% for A4c, 83.3% for PLAX, 88.5% for A2c, and 81.8% for A5c, with a global accuracy of 79.14%. We deployed our trained multiview DNNs on all MHI echos that had pertinent diagnostic labels and the three predefined views for each task. We then ran inference using the three multiview DNNs on all MHI studies containing the appropriate views.
DNN architectures
For view classification, doppler detection, and all single-view models, we chose as our video-based DNN backbone the 3D convolutional neural network X3D-Medium (X3D-M), from the family of X3D architectures15. We tested other video-based DNN backbones, including R2-1D and the transformers ViViT, MoviNet, and STAM, and found X3D the most performant backbone overall. X3D-M had the additional benefit of being relatively lightweight compared to these other models, with 3.8 million parameters compared to R2-1D’s 33.3 million. This computational efficiency enabled faster training, larger batch sizes, and, eventually, expansion of the architecture to incorporate multiview video input.
For our multiview analysis, we developed a bespoke architecture to integrate multiple views with an enhanced mid-fusion strategy. First, the DNN passes each view, consisting of a 64 × 224 × 224 × 3 video, through five convolutional blocks consisting of 3D convolutions, batch normalization, and a rectified linear unit non-linearity, producing temporally and spatially reduced embeddings of shape (B, C, T, H, W) representing batch, channel, time, height, and width. These first five blocks are unchanged from the original X3D-M architecture15. The resulting embeddings are stacked along a new view dimension, V, to produce a tensor of shape (B, C, V, T, H, W). This tensor is then flattened across the time, height, and width dimensions, resulting in a tensor of shape (B, C, V, THW). A sixth convolutional block (following the same convolution, batch normalization, rectified linear unit format) performs a 2D convolution across the view and combined spatiotemporal dimensions to fuse information across the views. The tensor is then reshaped to (B, CT, V, H, W) and passed to the final convolutional block. This final block expands the number of channels by a factor of 128 as it performs a 3D convolution across view, height, and width. This step is crucial for deep integration of spatiotemporal information across views. The resulting tensor is then reshaped to (B, CV, T, H, W), and we perform average pooling on time, height and width dimensions before passing the final tensor through a fully connected layer and a decision head. The final multiview DNN has 230 million parameters.
DNN training
All DNNs were developed and trained in Python (version 3.8.8) using the Pytorch library35 (version 1.8.8). Training of single-view DNNs took approximately 3 h; training of multiview DNNs took approximately 30–50 h on dual NVIDIA Quadro RTX 8000. For binary classification, we used a sigmoid decision head and the binary cross entropy loss, and for multiclass classification, we used a softmax decision head and the cross entropy loss function. For each of the three demonstration echo tasks separately, the data were divided into training/development/test datasets specific to that task in a 70/15/15 ratio, split by patient. The development dataset was used during training for learning rate decay scheduling and selection of the final models. The test dataset was held out from any model training or development and used to calculate evaluation metrics once the final DNNs for each task were trained.
Input videos to the DNN consisted of the first 64 frames of the video. Videos shorter than 64 frames were padded with empty frames. Echo video frame rates were 33 ± 17 frames per second. We did not normalize frame rates in the final training process, as this was tried and did not improve performance. The view classifier DNN was trained for 1,000 epochs starting with a learning rate of 0.01 and reducing learning rate using a factor of 0.5 with a patience of 50 and a loss threshold of 0.01. A separate doppler detection algorithm was trained on the same data with the same parameters. After training, the checkpoint achieving the lowest loss on the validation set was selected as the final DNN.
To train the single- and multiview DNNs, we used a standard hyperparameter sweep paradigm to allow all models to achieve their optimal performance and enable comparison. We performed separate hyperparameter sweeps over identical ranges of learning rate, threshold, and patience for learning rate decay for each task and view combination. For each sweep, we sampled learning rate from a log-uniform distribution between 1 × 10−6 and 5 × 10−2. For learning rate decay, we used the ReduceLRonPlateau scheduler monitoring validation loss with a 5% threshold. The scheduler patience was randomly sampled from (3, 5, 7, 10) and factor from (0.3, 0.5, 0.7). All models were trained for a total of 50 epochs without early stopping over 40 sweep trials with fixed random seeds for reproducibility. All models were trained on a single fixed data split for each task dataset. Both the input data size and model parameter sizes are substantially larger for the multiview DNNs resulting in increased training time for multiview models. We used the stochastic gradient descent optimizer (momentum = 0.9; weight decay = 0.0001) for all training runs. Training data were augmented gently using random resized crop between 0.95 and 1.0, color jitter between 0.8 and 1.2, and random rotation between −5 and 5 degrees. After training, the checkpoint achieving the highest AUC on the development set was selected as the final DNN.
All DNNs were evaluated using a combination of AUC and sensitivity/specificity at an optimal threshold defined as the threshold at which the geometric mean of sensitivity and specificity was maximal. Multiclass DNNs were evaluated using the mean AUC per class.
Explainability analysis
To examine the features from the input video that contributed to the DNN predictions, we used a custom adaptation of the guided class-discriminative gradient class activation mapping algorithm (guided grad-CAM) to examine single-view model performance23. This adapted the 2D implementation to expand the dimensionality to accommodate 3D video data. This provides an approximation of what echo video pixels the multiview DNN model may be focusing on, with the caveat that these are single-view approximations. Representative videos were chosen for high diagnostic quality and confident disease-positive predictions (>0.95), and the adapted guided grad-CAM approach was used to generate heat maps corresponding to the pixels that most strongly contributed to that DNN’s prediction. In addition to the guided grad-CAM, we also generated standard grad-CAM maps to provide a course, class-discriminative localization of relevant regions, while guided grad-CAM highlights fine-grained pixel-level features.
Statistical analysis
All continuous values are presented as mean ± 95% CI. For binary classification DNNs, the output of the final sigmoid function was a score ranging [0–1]. We report performance metrics using a default threshold for each DNN that was selected to maximize the F1 score on the development dataset for each task36. For the sensitivity/specificity-optimized sensitivity analysis, DNN performance metrics are reported at thresholds in the test dataset that fix sensitivity or specificity at 0.800. Statistical analyses were conducted in Python using pandas 2.3.0, numpy 1.26.4, scikit-learn 1.6.1, statsmodels 0.14.5, and MLstatkit 0.1.7.
The multiclass view classification DNN output consists of 21 continuous values ranging [0–1] with the predicted view corresponding to the maximum of the 21 values. For all test datasets, we present the AUC, sensitivity, specificity, and F1 score. CIs were derived by sampling the test set with replacement for 1,000 iterations to obtain 5th and 95th percentile values.
Differences in AUCs were tested using DeLong’s test37; in settings of multiple comparisons, Bonferroni correction was performed by adjusting the P values while retaining the threshold for significance at <0.05 (ref. 38). DeLong’s test was implemented using the MLstatkit package (version 0.1.7) in Python, and Bonferroni correction was implemented using the statsmodels package (version 0.14.5) in Python. Statistical significance was defined as P < 0.05.
For stratified analyses, we computed performance metrics for each DNN separately on strata of the test sets regarding age, gender, and disease subtypes. We defined disease substrata as those studies meeting previously described criteria for each abnormality compared to studies without criteria for abnormalities within each of the three echo tasks separately.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The complete development dataset used in this study is derived from patient care and thus is not made publicly available due to data privacy concerns. A limited deidentified dataset to demonstrate algorithm functionality is available at https://www.openicpsr.org/openicpsr/project/241296. Reasonable requests for collaboration using the data can be made from the authors, as feasible and permitted by the Regents of the University of California.
Code availability
The multiview DNN architecture for non-commercial purposes is available at https://github.com/JoshBarrios/omniread-echo. The code that supports this work is copyright of the Regents of the University of California and can be made available for commercial purposes through license.
References
Bahdanau, D., Cho, K. H. & Bengio, Y. Neural machine translation by jointly learning to align and translate. In 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings 1–15 (ICLR, 2015).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proc. IEEE Computer Society Conference on Computer Vision and Pattern Recognition 770–778 (IEEE, 2016).
Karpathy, A. et al. Large-scale video classification with convolutional neural networks. In Proc. IEEE Computer Society Conference on Computer Vision and Pattern Recognition 1725–1732 (IEEE, 2014); https://doi.org/10.1109/CVPR.2014.223
Tran, D. et al. A closer look at spatiotemporal convolutions for action recognition. In Proc. IEEE Computer Society Conference on Computer Vision and Pattern Recognition 6450–6459 (IEEE, 2018); https://doi.org/10.1109/CVPR.2018.00675
Ji, S., Xu, W., Yang, M. & Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 35, 221–231 (2013).
Carreira, J. & Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proc. 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017 4724–4733 (IEEE, 2017).
Ouyang, D. et al. Video-based AI for beat-to-beat assessment of cardiac function. Nature 580, 252–256 (2020).
Hughes, J. W. et al. Deep learning evaluation of biomarkers from echocardiogram videos-NC-ND license (http://creativecommons.org/licenses/by-nc-nd/4.0/) (2021); https://doi.org/10.1016/j.ebiom.2021.103613
Goto, S. et al. Artificial intelligence-enabled fully automated detection of cardiac amyloidosis using electrocardiograms and echocardiograms. Nat. Commun. 12, 2726 (2021).
Pirruccello, J. P. et al. Genetic analysis of right heart structure and function in 40,000 people. Nat. Genet. 54, 792–803 (2022).
Ulloa Cerna, A. E. et al. Deep-learning-assisted analysis of echocardiographic videos improves predictions of all-cause mortality. Nat. Biomed. Eng. 5, 546–554 (2021).
Duffy, G. et al. High-throughput precision phenotyping of left ventricular hypertrophy with cardiovascular deep learning. JAMA Cardiol. 7, 386–395 (2022).
Kusunose, K. et al. A deep learning approach for assessment of regional wall motion abnormality from echocardiographic images. JACC Cardiovasc. Imaging 13, 374–381 (2020).
Chao, C. J. et al. Echocardiography-based deep learning model to differentiate constrictive pericarditis and restrictive cardiomyopathy. JACC Cardiovasc. Imaging 17, 349–360 (2023).
Feichtenhofer, C. X3D: expanding architectures for efficient video recognition. Preprint at https://arxiv.org/abs/2004.04730 (2020).
Zhang, J. et al. Fully automated echocardiogram interpretation in clinical practice: feasibility and diagnostic accuracy. Circulation 138, 1623–1635 (2018).
Arnaout, R. et al. An ensemble of neural networks provides expert-level prenatal detection of complex congenital heart disease. Nat. Med. 27, 882–891 (2021).
Gao, X. et al. Deep echocardiography: data-efficient supervised and semi-supervised deep learning towards automated diagnosis of cardiac disease. NPJ Digit. Med. 1, 59 (2018).
Lang, R. M. et al. Recommendations for cardiac chamber quantification by echocardiography in adults: an update from the American Society of Echocardiography and the European Association of Cardiovascular Imaging. J. Am. Soc. Echocardiogr. 28, 1–39.e14 (2015).
Nagueh, S. F. et al. Recommendations for the evaluation of left ventricular diastolic function by echocardiography. J. Am. Soc. Echocardiogr. 22, 107–133 (2009).
Nagueh, S. F. et al. Recommendations for the evaluation of left ventricular diastolic function by echocardiography: an update from the American Society of Echocardiography and the European Association of Cardiovascular Imaging. J. Am. Soc. Echocardiogr. 29, 277–314 (2016).
Zoghbi, W. A. et al. Recommendations for noninvasive evaluation of native valvular regurgitation: a report from the American Society of Echocardiography developed in collaboration with the Society for Cardiovascular Magnetic Resonance. J. Am. Soc. Echocardiogr. 30, 303–371 (2017).
Selvaraju, R. R. et al. Grad-CAM: visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 128, 336–359 (2020).
Lang, R. M., Mor-Avi, V., Sugeng, L., Nieman, P. S. & Sahn, D. J. Three-dimensional echocardiography. The benefits of the additional dimension. J. Am. Coll. Cardiol. 48, 2053–2069 (2006).
Mittal, R. et al. 3D reconstruction of brain tumors from 2D MRI scans: an improved marching cube algorithm. Biomed. Signal Process. Control 91, 105901 (2024).
Wohlgelernter, D. et al. Regional myocardial dysfunction during coronary angioplasty: evaluation by two-dimensional echocardiography and 12 lead electrocardiography. J. Am. Coll. Cardiol. 7, 1245–1254 (1986).
Avram, R. et al. Automated assessment of cardiac systolic function from coronary angiograms with video-based artificial intelligence algorithms. JAMA Cardiol. 8, 586–594 (2023).
Stahlschmidt, S. R., Ulfenborg, B. & Synnergren, J. Multimodal deep learning for biomedical data fusion: a review. Brief. Bioinform. 23, bbab569 (2022).
Holste, G. et al. Complete AI-enabled echocardiography interpretation with multitask deep learning. JAMA https://doi.org/10.1001/jama.2025.8731 (2025).
Lau, E. S. et al. Deep learning–enabled assessment of left heart structure and function predicts cardiovascular outcomes. J. Am. Coll. Cardiol. 82, 1936–1948 (2023).
Hall, D. L. & Llinas, J. An introduction to multi-sensor data fusion. Proc. IEEE 85, 6–23 (1997).
Kwan, A. C. et al. Deep learning-derived myocardial strain. JACC Cardiovasc. Imaging https://doi.org/10.1016/j.jcmg.2024.01.011 (2024).
Tokodi, M. et al. Deep learning-based prediction of right ventricular ejection fraction using 2D echocardiograms. JACC Cardiovasc. Imaging 16, 1005–1018 (2023).
Lin, X. et al. Echocardiography-based AI for detection and quantification of atrial septal defect. Front. Cardiovasc. Med. 10, 985657 (2023).
Paszke, A. et al. PyTorch: an imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 32, 8024–8035 (2019).
Ferri, C., Hernández-Orallo, J. & Modroiu, R. An experimental comparison of performance measures for classification. Pattern Recognit. Lett. 30, 27–38 (2009).
DeLong, E. R., DeLong, D. M. & Clarke-Pearson, D. L. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics 44, 837–845 (1988).
Bland, J. M. & Altman, D. G. Multiple significance tests: the Bonferroni method. Brit. Med. J. 310, 170 (1995).
Acknowledgements
We thank D. Glidden at UCSF for guidance about statistical analyses, J. Hesse at UCSF for assistance with image data acquisition, UCSF Academic Research Services for support with electronic health record data acquisition, and UCSF Cardiovascular Research Institute Information Technology for graphical processing unit cluster support. Support for this work was received from the National Institutes of Health: K23HL135274 (G.H.T.), R56HL161475 (G.H.T.), and DP2HL174046 (G.H.T.).
Author information
Authors and Affiliations
Contributions
J.P.B., G.H.T., and J.E.O. contributed to project planning. J.P.B., M.U.A., S.A., and G.H.T. conducted experiments, performed data analysis, and drafted the paper. J.D., E.L.L. and R.A. conducted experiments for the Montreal external validation cohort.
Corresponding author
Ethics declarations
Competing interests
G.H.T. has previously received research grants from Janssen Pharmaceuticals and MyoKardia, Inc., a wholly owned subsidiary of Bristol Myers Squibb, and is an advisor to Prolaio Inc. and Viz.ai. S.A. was at UCSF during his contribution to this work; the information and views herein are solely S.A.’s and do not represent his current employer (Point72). The other authors declare no competing interests.
Peer review
Peer review information
Nature Cardiovascular Research thanks the anonymous reviewers for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 Performance of video-based echo 21-view classifier and color doppler detector.
(A) Receiver operating characteristic curves and (B) confusion matrix for the 21 class echo view classifier. The view classifier DNN achieved a mean AUC of 0.972 across 21 classes. (C) Receiver operating characteristic curve and (D) confusion matrix for the DNN color doppler classifier. The color doppler classifier achieved an AUC of 0.991. View class number view labels: 0: parasternal long axis, 1: parasternal long axis (zoom on left atrium), 2: parasternal long axis (standard zoom), 3: apical two chamber, 4: apical two chamber (left atrium occluded), 5: apical two chamber (left ventricle occluded), 6: apical three chamber, 7: apical three chamber (left atrium occluded), 8: apical three chamber (left ventricle occluded), 9: apical four chamber, 10: apical four chamber (left ventricle occluded), 11: apical four chamber (left atrium occluded), 12: apical five chamber,13: parasternal short axis apical level 14: parasternal short axis (mitral valve level), 15: parasternal short axis (zoom on left atrium), 16: parasternal short axis (aortic valve zoom), 17: subcostal, 18: suprasternal, 19: right ventricle inflow, 20: other.
Extended Data Fig. 2 Grad-CAM and guided grad-CAM examples for false positive or low confidence DNN predictions.
Grad-CAM and guided grad-CAM heatmaps showing the class-weighted activations of the final convolutional layer in our single-view DNNs for left/right ventricular abnormalities (VD) and diastolic dysfunction (DD) using apical two chamber (A2c), four chamber (A4c), and parasternal long axis (PLAX) views, and valvular regurgitation (valve) using A4c, apical 5 chamber (A5c) and PLAX views. These are shown for high confidence true positive examples, false positive examples and low confidence examples. For each panel, the left image is the original echo frame, the middle image is the Grad-CAM and the right image is the guided Grad-CAM. Brighter red (Grad-CAM) or pink (guided Grad-CAM) areas indicate areas of greater importance for that DNN’s prediction from that frame.
Supplementary information
Supplementary Information (download PDF )
Discussion and references.
Source data
Source Data Fig. 3 (download XLSX )
Source data for ROC plots.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Barrios, J.P., Ansari, M.U., Olgin, J.E. et al. Multiview deep learning improves detection of major cardiac conditions from echocardiography. Nat Cardiovasc Res 5, 234–245 (2026). https://doi.org/10.1038/s44161-026-00786-7
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s44161-026-00786-7
