
Abstract
With the rapid advancement and application of Unmanned Aerial Vehicles (UAVs), target detection in urban scenes has made significant progress. Achieving precise 3D reconstruction from oblique imagery is essential for accurate urban object detection in UAV images. However, challenges persist due to low detection accuracy caused by subtle target features, complex backgrounds, and the prevalence of small targets. To address these issues, we introduce the Polysemantic Cooperative Detection Transformer (Pc-DETR), a novel end-to-end UAV image target detection network. Our primary innovation, the Polysemantic Transformer (PoT) Backbone, enhances visual representation by leveraging contextual information to guide a dynamic attention matrix. This matrix, formed through convolutions, captures both static and dynamic features, resulting in superior detection. Additionally, we propose the Polysemantic Cooperative Mixed-Task Training scheme, which employs multiple auxiliary heads for diverse label assignments, boosting the encoder’s learning capacity. This approach customizes queries and optimizes training efficiency without increasing inference costs. Comparative experiments show that Pc-DETR achieves a 3% improvement in detection accuracy over the current state-of-the-art MFEFNet, setting a new benchmark in UAV image detection and advancing methodologies for intelligent UAV surveillance systems.
Similar content being viewed by others

Introduction
The advancement of UAV technology has led to the increased use of drones for aerial imaging in urban settings, aiding tasks such as traffic monitoring and urban reconstruction. In a recent study1, researchers introduced a template-guided frequency-attention mechanism and an adaptive cross-entropy loss function, aiming to improve the robustness of UAV visual tracking. The method performs well in frequency domain information extraction and can enhance the processing of complex motion patterns. MobileTrack2 has designed an efficient mobile tracking system based on a lightweight Siamese network for high frame rate UAV applications that significantly reduces computational overhead, its advantages in computational efficiency and speed. Further3, multi-UAV cooperative single-target tracking is explored, which improves the tracking accuracy by consistency characterisation mining. Xue et al.4 proposed a query-guided redetection-based visual tracking method for UAVs, which effectively mitigates the target occlusion problem. In SmallTrack5, a UAV small target tracking method combining wavelet pooling and graph-enhanced classification is proposed, which significantly improves the tracking performance of small targets in complex scenes. Although its wavelet pooling strategy achieves good resolution performance at different scales, its real-time performance and generalisation ability to different types of small targets in dynamic scenes are still limited. Although UAV algorithms have achieved significant advances in the field of detection and tracking, they still suffer from poor real-time performance as well as low accuracy for small targets. And UAV images frequently feature small, easily obscured targets, complicating accurate detection.
To address this issue, data enhancement techniques-such as rotation, cropping, and splicing-have been employed to improve the representation of small targets in typically sparse datasets. For instance, Zhang et al.6 proposed cropping UAV images into smaller segments for better feature extraction, although this method risks slicing through targets. Tang et al.7 used rotational copying to augment datasets, but this approach fails to effectively capture small target features. Additionally, Chen et al.8 introduced the CSRGAN network to enhance low-resolution images, though this can amplify background noise. Zhou et al.9 combined SRGAN with FPN to better detect small targets, although up-sampling may degrade image quality, while Hou et al.10 developed a GAN with centroid weights to refine feature mapping, which also risks increasing background clutter.
Context learning has shown promise in enhancing small target detection by providing additional feature information. For example, Oliva et al.11 highlighted the importance of context in target detection, and Liang et al.12 measured spatial distances between targets, although this method requires high computational resources. Hong et al.13 created a contextual attention module that adjusts feature map scales but risks data overload. These systems, depicted in Fig. 1a, mainly rely on isolated interactions between queries and keys to form attention matrices but often overlook the contextual data provided by adjacent keys.
Traditional detection methods, such as the Viola-Jones algorithm and HOG, struggle with speed and accuracy14,15,16,17. In contrast, CNNs dominate modern detection, with single-stage algorithms like YOLOv318 offering faster detection at a slight accuracy cost. Two-stage algorithms, like Faster R-CNN19, require more computational resources but provide higher accuracy. Recent advancements focus on multi-scale fusion, attention mechanisms, and super-resolution feature generation.
Object detection has emerged as an important field with the R-CNN family19,20,21 and a series of variants such as ATSS22, RetinaNet23, FCOS24, and PAA25, achieving remarkable breakthroughs. The main idea is a one-to-many label matching rule, where the detector assigns multiple coordinates to the ground truth box to supervise the generation of the final target, fitting it with an anchor23, among others. While these models demonstrate superior performance, they are heavily reliant on hand-designed components (e.g., non-maximum suppression). To simplify the implementation of end-to-end detectors and achieve convenient functionality, the DEtection TRansformer (DETR)26 emerged. This framework views object detection as a prediction problem for ensembles, forming a one-to-one configuration process by introducing a Transformer encoder and decoder, whereby each ground truth box is matched with a single query, avoiding the tediousness associated with redundant hand-designed components. While Transformers have significantly improved Natural Language Processing and have been adapted for target identification in computer vision, DETR26 has revolutionized target detection by conceptualizing it as an ensemble prediction task. However, its one-to-one matching mechanism often leads to inferior performance compared to classical detectors that utilize one-to-many label assignments. This is due to the drawback of the one-to-one set matching rule, which results in a small number of positive queries that can be effectively applied, leading to inefficient training.
Based on previous studies, two main algorithmic issues need to be addressed to achieve accurate target detection in UAV aerial imagery:
-
The traditional self-attention module fails to capture contextual information between adjacent keys, leading to reduced feature richness and difficulty in accurately identifying small targets.
-
One-to-one matching in end-to-end object detectors results in poorer performance compared to models that assign multiple labels to a single item.

Comparison of details of ordinary self-attention mechanisms with Polysemantic Transformer(PoT). (a) Conventional self-attention mechanisms only use individual query-keys to compute the correlation-attention matrix, but the contextual information between the keys cannot be adequately extracted, (b) the PoT module firstly utilises a 3\(\times\)3 convolution to mine the static contextual information between the keys. Subsequently, based on the extracted query as well as the context keys, two consecutive 1\(\times\)1 convolutions are used to generate the attention and dynamic context information. The final combination is performed for target output.
In Fig. 1b, this work introduces the Polysemantic Transformer (PoT), which integrates contextual mining with self-attention to enhance feature representation. The PoT employs a 3\(\times\)3 convolution to gather contextual information from adjacent keys, followed by 1\(\times\)1 convolutions to generate attention matrices that leverage the relationships between queries and keys.
Furthermore, we present the Pc-DETR architecture for UAV image detection, which utilizes a one-to-many label assignment strategy to enhance training efficiency. By employing auxiliary heads with diverse label assignments, we optimize the learning capabilities of the encoder, significantly improving detection performance.
Our contributions are outlined as follows:
-
1.
Development of the Polysemantic Transformer (PoT) block to enhance visual recognition in UAV aerial imagery by leveraging contextual information.
-
2.
Introduction of the Polysemantic Cooperative Mixed-Task Training (Pc-DETR) scheme to optimize DETR-based detectors through diverse label assignment methods.
-
3.
Improvement in training efficiency for the decoder by extracting the coordinates of positive instances from auxiliary heads, streamlining inference without adding computational burden.
-
4.
Experimental results on the VisDrone dataset demonstrate that our approach outperforms leading UAV detection algorithms, achieving a 3% higher mean average precision (mAP) score compared to MFEFNet.
Review work
Review of the transformer
The Transformer’s self-attention mechanism has shown excellent results in natural language processing (NLP) tasks, which has sparked researchers’ interest in applying self-attention mechanisms to visual scenes. Initially in NLP, the self-attention mechanism27 was designed to capture long-distance dependencies in sequence modeling. In the field of computer vision (CV), a straightforward way to adapt this mechanism from NLP to CV is to perform self-attention operations on feature vectors at different spatial locations within an image.
One of the early studies in ConvNet that attempted to introduce the self-attention mechanism was the non-local operation28, which applies self-attention as an additional module on the convolutional output. In29, convolutional operations were augmented by the introduction of a global multi-head self-attention mechanism to improve the performance of image classification and object detection. However, due to the limited scalability of global self-attention28,29 when applied to the entire feature map,30,31 proposed a scheme to apply self-attention in local blocks (e.g., 3\(\times\)3 grids). This local self-attention design effectively reduces the parameters and computation required by the network, allowing it to potentially replace convolutional operations throughout the deep architecture.
Recently, self-supervised representation learning has been investigated by reshaping the original image into a one-dimensional sequence and employing Sequence Transformer32 for autoregressive prediction. Subsequently,26,33 directly applied pure Transformer to a sequence of local features or image blocks for object detection and image recognition. In a more recent study,34 designed a high-performance backbone network by replacing the last three 3\(\times\)3 convolutional layers of ResNet with a global self-attention layer. To this end, we focus on the self-attention mechanism in the visual backbone. One of the main drawbacks of directly exploiting traditional self-attention is that it neglects to explicitly model the rich contextual information between neighboring elements. In contrast, the Polysemantic Transformer (PoT) fully incorporates the rich contextual information between keys and feature maps, unifying the learning process within a single architecture while maintaining a favorable number of parameters.
BiFormer35 proposes a bi-level routing attention mechanism, which divides the attention computation into two levels, local and global, to enhance the efficiency and performance of Vision Transformer in multi-scale feature processing. The method enhances the computational efficiency of the model by reducing redundant computations, while maintaining the ability to express complex image features, effectively balancing performance and resource consumption. The key core lies in the bi-level routing attention mechanism, which divides the attention computation into local and global levels and focuses on computational efficiency and multi-scale feature processing to enhance the computational resource utilisation under the premise of ensuring performance. Based on the research idea of BiFormer, we propose the more advantageous Polysemantic Transformer (PoT) module, the core idea of which is to improve contextual modelling so that the model can better capture the inter-relationships of different regions of an image in visual tasks. Unlike BiFormer, which focuses on improving attention computation through the Bi-Level Routing Attention mechanism to improve efficiency and perform better in multi-scale feature processing, Polysemantic Transformer (PoT) focuses more on improving global Polysemantic Transformer (PoT) focuses more on improving the fusion of global and local information through an explicit contextual mechanism to improve the model’s understanding of complex scenes.Polysemantic Transformer (PoT) introduces an explicit contextual mechanism that does not only rely on the local features, but also takes into account the more global contextual information in the image. In this way, the model is able to recognise relationships between objects in complex visual scenes and process visual tasks more efficiently.
Review of matching rules
One-to-one target matching rules are prevalent in contemporary research. In DETR26, this strategy is implemented using the Hungarian algorithm, which addresses an optimal assignment problem to minimize the total cost between predicted and true labels. The cost function typically comprises cross-entropy loss for category prediction, along with L1 loss and GIoU loss for bounding box prediction.
DN-DETR36 enhances the attention mechanism in DETR by introducing deformable attention, allowing the model to focus more on smaller regions within the image rather than the entire image. Despite this modification, DN-DETR retains the Hungarian algorithm for its ensemble matching strategy, preserving the fundamental one-to-one matching framework. DINO37 advances the design of DN-DETR by incorporating an improved deformable attention module to bolster detection performance. Like its predecessors, DINO also utilizes the Hungarian algorithm for the one-to-one matching strategy. DAB-DETR38 integrates the concept of anchor frames into DETR, enhancing the model’s ability to detect small-sized targets. Even with the addition of anchor frames, DAB-DETR continues to employ the Hungarian algorithm for one-to-one matching between predictions and actual labels, ensuring the integrity of the ensemble predictions. Group-DETR39 modifies the encoder structure of DETR by segmenting the image into multiple groups and conducting target detection within each group to elevate performance. Despite these structural adjustments, Group-DETR maintains the Hungarian algorithm for ensemble matching, facilitating one-to-one optimal matching. H-DETR40 merges the strengths of DETR with anchor-based methods and seeks to rectify the limitations of DETR in handling objects of various sizes by introducing layered features and multi-scale detection. In its ensemble matching strategy, H-DETR persists in using the Hungarian algorithm to ensure effective correspondence between predicted and actual labels.
In summary, although DETR and its variants differ in model architecture and specific implementations, they consistently employ the Hungarian algorithm as the central strategy for one-to-one ensemble matching. The essence of this approach lies in transforming the target detection challenge into an optimization problem, where the best match is determined by calculating the minimum total cost between predicted and true labels, leading to efficient and accurate target detection.
One-to-many target matching rules are also prevalent in contemporary research. Faster R-CNN41 employs a Region Proposal Network (RPN) and subsequent Region of Interest (RoI) pooling layer to generate potential target candidate regions. During the RPN stage, each anchor point is classified as foreground or background based on its Intersection over Union (IoU) with any real bounding box. These candidate regions are further refined through a series of network layers, leading to category classification and bounding box regression.
RetinaNet23 utilizes an approach known as Focal Loss, designed to mitigate the effects of category imbalance by focusing on a large number of easily categorized negative samples (background). It arranges anchor points at multiple scales, predicting categories and bounding box offsets for each. Anchor points are matched with true bounding boxes based on the IoU, with those above a certain threshold (e.g., 0.5) considered positive samples. FCOS42 (Fully Convolutional One-Stage Detector) discards traditional anchor-box mechanisms, adopting a point-level prediction approach. Each position directly predicts the category and bounding box relative to that position. FCOS uses a centrality score to optimize the matching process, reducing inaccuracies due to positional bias. ATSS22 optimizes training sample selection by dynamically choosing a positive sample matching threshold for each anchor point based on the IoU distribution between each anchor point and its nearest true bounding box. This method improves upon the biases and instabilities inherent in traditional static threshold methods. PAA25 (Probabilistic Anchor Assignment) introduces a probability-based anchor assignment mechanism to address traditional anchor assignment issues. By calculating the likelihood of each anchor belonging to the foreground and dynamically selecting positive samples based on this probability, this approach aims to reduce the detrimental effects of incorrect label assignments and enhance model performance.
In summary, the matching strategies of these models focus on efficiently assigning multiple predictions to real labels and managing the relationships between these predictions and real labels. Each model employs unique mechanisms to optimize this process, thereby enhancing the accuracy and efficiency of detection.
To address the issues of low detection accuracy and imbalance in UAV aerial imagery, as well as challenges related to the extraction of feature information among contextual images or excessive extraction of irrelevant information, we introduce the Polysemantic Transformer module. This module is designed to thoroughly integrate the image feature extraction capabilities across both static and dynamic contexts. Furthermore, we propose the Pc-DETR model, which effectively addresses the issues of supervised sparsity and preservation of the encoder’s discriminative properties. This model enables the realization of an end-to-end detector equipped with multiple auxiliary heads, enhancing the efficiency of detecting positive samples in UAV surveillance and significantly ameliorating the prevalent challenges in UAV aerial image detection.
Review of DETR
DETR, introduced by Carion et al. in 202026, is a target detection methodology that relies entirely on the Transformer architecture. This model leverages the Transformer’s self-attention mechanism to address challenges in target detection, entirely eliminating the need for anchor frames and complex post-processing steps, such as non-maximum suppression (NMS), traditionally employed in target detection algorithms. DETR redefines the target detection task as a direct ensemble prediction problem, simplifying the approach while maintaining efficacy.

Traditional DETR Architecture Diagram. The left side starts with the input image and passes through the Backbone module subsequently through the traditional Transformer Encoder and Decoder structure, resulting in a one-to-one label matching rule.
As illustrated in Fig. 2, the DETR (Detection Transformer) model comprises three principal components: a Convolutional Neural Network (CNN) for feature extraction, a Transformer encoder-decoder, and a simple Feedforward Network (FFN) for prediction. Initially, the input image is processed through a standard CNN, such as ResNet, to extract feature maps. These feature maps are subsequently fed into the Transformer’s encoder for further refinement. The encoder processes these features, enhancing their contextual relationships through self-attention mechanisms and a feedforward network. The decoder employs a fixed number of learned object queries, each of which progressively refines its corresponding output via self-attention and encoder-decoder attention mechanisms.
In DETR, the Transformer’s self-attention mechanism is computed as follows:
Here, \(Q\), \(K\), and \(V\) represent the query, key, and value matrices, respectively, and \(d_k\) denotes the dimension of the key. This mechanism enables the model to exchange information across different parts of the input sequence, thereby capturing complex spatial relationships.
The output of the decoder is processed through a linear layer to predict the category of the targets and a vector consisting of four scalars to predict the bounding box (coordinates of the center point, height, and width).
For training DETR, the authors designed a matching loss based on the Hungarian algorithm. Each output of the decoder must match a unique real object. The loss function comprises classification loss and bounding box regression loss:
In this formula, \(c_i\) and \(b_i\) denote the category and bounding box of the \(i\)-th real object, respectively, \(p_i\) and \(\hat{b}_i\) are the corresponding predictions, \(\sigma\) is the output permutation from the Hungarian algorithm that minimizes prediction cost, and \(\textbf{L}_{\text {box}}\) usually combines L1 loss and the generalized Intersection over Union (GIoU) loss. This approach enables DETR to directly learn the optimal method for predicting a set of objects from an image without the need for complex post-processing, marking a novel breakthrough in the field of object detection.
Despite DETR’s achievements, it still lacks the capability to extract polysemantic contextual information from images, leading to difficulties in feature extraction. Additionally, it cannot match the powerful accuracy advantages offered by one-to-many matching rules. To address the issues of low detection accuracy and imbalance in images, as well as challenges related to the extraction of relevant feature information or the excessive extraction of irrelevant information in contextual images, we have introduced a multi-semantic transformer module. This module is designed to thoroughly integrate feature extraction capabilities in both static and dynamic contexts. Furthermore, we propose the Pc-DETR model, which effectively addresses issues of supervision sparsity and preserves encoder discriminative characteristics. This model implements an end-to-end detector equipped with multiple auxiliary heads, enhancing the detection efficiency of positive samples in images. It significantly improves common challenges in image detection and has been successfully applied to drone aerial image detection tasks, achieving excellent results and resolving difficulties in detecting small targets from drones.
Pc-DETR
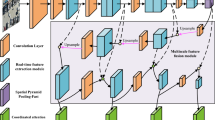
This chapter provides a detailed introduction to our innovative model, the Polysemantic Cooperative Detection Transformer (Pc-DETR), as illustrated in Figure 3. We have made significant modifications to the traditional transformer in the backbone section, termed the Polysemantic Transformer Backbone (PoT). The intricate details of these modifications are discussed in section “Multi-projection attention mechanisms in visual backbone” and “Polysemantic transformer module”. Additionally, following the integration of the PoT feature extraction block, training will proceed in a parallel auxiliary manner, with specific details provided in sections “Cooperative mixed-task training” and “Specific positive query generation”. The chapter concludes with section “Explanation of how Pc-DETR works”, where we explain how the Pc-DETR operates and the functionalities it brings to enhance image detection tasks.

Our Pc-DETR overall network architecture. Includes our core module Polysemantic Backbone and the supplementary module Cooperative Mixed-Task Training. Note: Auxiliary branches are only generated during the training phase and will not be generated during the test evaluation phase. The core architecture focuses on the PoT Backbone module of our design and the training mode of one-to-many labelled auxiliary heads for multi-head auxiliary training, which achieves the best auxiliary effect by setting up a certain number of parallel auxiliary heads. The rest of the unspecified parts are traditional generic forms of various DETR variants.
Multi-projection attention mechanisms in visual backbone
This study explores the limitations of conventional attention mechanisms in traditional visual backbones, particularly in detecting very small targets in high-altitude urban UAV imagery. To resolve this issue, we propose the Polysemantic Transformer (PoT), an innovative transformer block designed to handle dense and complex UAV tilt images. This design surpasses the constraints of traditional self-attention by utilizing aggregated semantics between input keys, thereby enhancing self-attention learning and improving the network’s representational abilities. Additionally, we introduce two aggregated semantic transform networks based on ResNet43, where PoT blocks replace the standard \(3 \times 3\) convolutions throughout the architecture.
In this section, we present a comprehensive mathematical framework for a scalable local polytope in self-attention mechanisms used in visual backbones30,31. The framework is depicted in Fig. 4a. We start with a 2D feature map \(\chi\) that has dimensions \(h \times \omega \times c\), where \(h\) represents the height, \(\omega\) represents the width, and \(c\) represents the number of channels. The variable \(\chi\) is transformed into \(q = \chi \omega _q\) (Queries), \(k = \chi \omega _k\) (Keys), and \(v = \chi \omega _v\) (Values) by utilizing the embedding matrices \(\{\omega _q, \omega _k, \omega _v\}\), which are implemented as \(1 \times 1\) convolutions. The local relation moments \(r\) are determined by taking the dot product between \(k\) and \(q\), where \(r\) is a tensor of shape \(\mathbb {R}^{h \times \omega \times (k \times k \times c_h)}\).
The symbol \(c_h\) represents the count of heads, whereas \(\odot\) specifies the operation of local matrix multiplication. It is used to evaluate the similarity between each \(q\) and \(k\) within a grid of size \(k \times k\). Each feature \(r^{(i)}\) at the \(i\)-th position in space is a \(k \times k \times c_h\) vector that contains \(c_h\) local \(q-k\) relationships. This method enhances the variable \(r\) by incorporating positional information into every \(k \times k\) grid.
The variable \(p\) belongs to the set of real numbers raised to the power of \(k \times k \times c_k\), representing the 2-dimensional relative position embedding. This embedding is common to all \(c_h\) heads. The attention matrix \(a\) is generated by applying the softmax function to the vector \(\hat{r}\) after normalizing it along the channel dimension for each head. The final output feature maps are produced by combining every value within each \(k \times k\) grid in the \(c_h\) localized attention matrices, which are derived from reshaping \(a\).
Each head’s local attention matrix blends \(v\), the feature maps divided by channel dimensions, resulting in the ultimate output \(y\), which is a concatenation of the combined feature maps from all heads.

(a) Ordinary self-attention module and (b) our Polysemantic Transformer (PoT) structure. \(+\) and \(\odot\) denote element-by-element summation and local matrix multiplication, respectively.
Polysemantic transformer module
Traditional self-attention mechanisms facilitate the interaction of features across different spatial locations based solely on the input itself. However, these mechanisms learn query-key relationships independently without considering the rich semantics between them, which presents challenges for dense target detection in urban UAV imagery. This limitation diminishes the effectiveness of self-attention in visual representation learning via 2D feature maps, resulting in lower detection accuracy.
To tackle this issue, we introduce the Polysemantic Transformer (PoT) block, depicted in Fig. 4b. This block integrates semantic information mining and self-attention learning into a unified architecture. Our goal is to exploit the polysemantic contextual information between neighboring keys to enhance self-attention learning and improve the quality of the output feature map.
Let \(\chi\) be a 2D map of features with dimensions \(h \times \omega \times c\). We define the keys, queries, and values as follows: \(k\) is equal to \(\chi\), \(q\) is equal to \(\chi\), and \(v\) is equal to \(\chi \omega _v\). Instead of utilizing \(1 \times 1\) convolutions as is typically done in self-attention, the PoT block employs \(k \times k\) group convolutions on neighboring keys within the \(k \times k\) lattice to contextualize each key representation.
It is important to note that the context keys \(k^1 \in \mathbb {R}^{h \times \omega \times c}\) serve as the static contextual representation of \(\chi\) and reflect the static polysemantic contextual information that exists between different local neighborhood keys. The attention matrices are calculated using two successive \(1 \times 1\) convolutions (\(\omega _\theta\) with ReLU activation and \(\omega _\delta\) without), which are obtained by concatenating \(k^1\) and \(q\), as explained in the following illustration:
Instead of using isolated query-key pairs, the local attention matrix for each head is obtained by integrating query features with polysemantic context key features. This provides a more comprehensive understanding of the local attention matrix. By incorporating information from static polysemantic contexts \(k^1\), this technique significantly enhances the process of self-attention learning. Using the aggregated semantic attention matrix \(a\), we construct the participation feature map \(k^2\) by aggregating all of the values \(v\). This is done in accordance with the traditional self-attention approach.
Since \(k^2\) represents dynamic feature interactions, it is referred to as the dynamic representation of semantics. Using the attention technique, the PoT module integrates the static semantics \(k^1\) and dynamic semantics \(k^2\) to create the final result \(y\).
Backbone of the polysemantic transformer
PoT is a cohesive self-attention component designed to substitute conventional convolutions in ConvNet. This enables the improvement of the visual framework by incorporating semantic self-attention. We integrate PoT blocks into the advanced ResNet architecture43 without substantially augmenting the parameter allocation. Table 1 displays different configurations of the aggregated semantic transformer network (PoT) that utilize the ResNet-50 backbone. These configurations are collectively referred to as PoT-50.
PoT-50 is generated by substituting all \(3 \times 3\) convolutions in ResNet-50 (in the resnet-2, resnet-3, resnet-4, and resnet-5 stages) with PoT blocks. Due to the computational similarity between PoT blocks and standard convolutions, the number of parameters and FLOPs in PoT-50 is similar to those in ResNet-50.
In addition, we analyze the intricate connections and distinctions between the Polysemantic Transformer and other prominent visual frameworks.
-
1.
Blueprint Separable Convolution44: This technique approximates traditional convolution by employing a \(1 \times 1\) pointwise convolution, followed by a \(k \times k\) depthwise convolution to decrease redundancy in the depth dimension. It exhibits resemblances to Transformer-style blocks, such as our PoT block, in that they both apply \(1 \times 1\) pointwise convolution to transform inputs into values, then use \(k \times k\) local attention matrices depth-wise to perform aggregation calculations. Furthermore, Transformer-style blocks employ a channel-sharing technique for aggregation, which can be perceived as a packaged block convolution. This strategy involves sharing filters across channel blocks without compromising accuracy.
-
2.
Dynamic Region-Aware Convolution45: This technique employs a filter generator module that utilizes two \(1 \times 1\) convolutions to obtain filters for area characteristics at various spatial locations. The attention matrix generator in our PoT block is designed as follows: the attention matrix generator in our system employs intricate feature interactions between polysemantic context keys and queries to facilitate self-attention learning. In contrast, the filter generator described relies solely on the principal feature input maps.
-
3.
Bottleneck Transformer34: This approach enhances ConvNet’s self-attention by replacing \(3 \times 3\) convolutions with Transformer-style modules. Its global multi-head self-attention layer is more computationally costly than our PoT block’s local self-attention. BoT50 uses Bottleneck Transformer blocks to replace the last three convolutions in the ResNet backbone. In comparison, our PoT block may replace all \(3 \times 3\) convolutions in the architecture. By using the broad polysemantic context of input keys, our PoT block improves self-attention learning.
Utilizing the conventional Transformer design, we incorporate input detection images into a backbone network and encoder to generate an initial feature map of possible items. Within the decoder, pre-established object queries engage with these features through cross-attention. To enhance the learning of features in the encoder and attention in the decoder, we propose the use of Pc-DETR. This approach combines a collaborative hybrid task training scheme with tailored forward query generation. We provide a comprehensive explanation of these processes and analyze their efficacy.
Cooperative mixed-task training
Using auxiliary heads that leverage label assignment paradigms such as ATSS and Faster R-CNN is an example of one-to-many approaches that can reduce the sparse supervision of encoder output caused by minimizing decoder active queries. Various label assignments improve encoder output monitoring, ensuring it remains discriminative enough to permit head training convergence.
To convert the potential features \(\varvec{A}\) of the encoder into a feature pyramid, we employ a multiscale adapter. This adapter generates a set of feature maps \(\{\varvec{A}_1, \ldots , \varvec{A}_\textbf{J}\}\), where \(\varvec{A}_\textbf{J}\) corresponds to feature maps that have undergone a downsampling step of \(2^{2 + \textbf{J}}\). Like ViTDet46, we generate feature pyramids by extracting features from separate feature maps in the single-scale encoder. However, we utilize bilinear interpolation and PoT blocks for the upsampling process. For example, the encoder generates single-scale features, which are then transformed into a feature pyramid by repeatedly reducing the size (e.g., using convolution with a step size of 2 and a \(3 \times 3\) kernel) or increasing the size of the features.
The feature pyramid in the multiscale encoder is built by downsampling only the coarsest features. We define a set of collaborating heads, denoted as \(\textbf{K}\), along with their corresponding label assignments, denoted as \(\textbf{A}_\textbf{K}\). To acquire the prediction \(\hat{\textbf{P}}_i\), we send \(\{\varvec{A}_1, \ldots , \varvec{A}_\textbf{J}\}\) to the \(i\)th collaborating head. At the \(i\)th head, the supervised aim for the positive and negative samples is computed by that head, denoted by the symbol \(\textbf{A}_i\). The method requires the use of the ground truth set, denoted by the mathematical symbol \(\textbf{G}\).
The sets \(\{Pos\}\) and \(\{Neg\}\) represent the positive and negative coordinate pairings in \(\textbf{J}\), respectively. The value of \(\varvec{A}_j\) is determined by \(\textbf{A}_i\), where \(\textbf{J}\) represents the index of a feature in the set \(\{\varvec{A}, \ldots , \varvec{A}_\textbf{J}\}\). \(\textbf{B}_i^{\{Pos\}}\) represents the collection of positive spatial coordinates, while \(\textbf{P}_i^{\{Pos\}}\) and \(\textbf{P}_i^{\{Neg\}}\) refer to the supervised targets at those specific coordinates, which include categories and regression offsets. The specific characteristics of each variable are outlined in Table 2. The loss function is defined as follows:
The regression loss for negative samples is disregarded. The training objective for maximizing the \(K\) auxiliary heads is stated as follows:
Specific positive query generation
In the one-to-one matching paradigm, each ground truth box is assigned as a supervised target to a given query. This ensures that the data is accurate and reliable. However, as shown in Fig. 5, a restricted number of good queries might lead to inefficient cross-attention learning in the Transformer decoder. To address this issue, we assign labels to every auxiliary head based on the value of \(\textbf{A}_i\). This allows us to generate a sufficient number of customized affirmative queries, ultimately enhancing the effectiveness of the model’s training.

Plot of feature scores in the encoder versus attention scores in the decoder.

Comparison of feature visualisation compositions for different models.
The positive samples for the \(i\)th auxiliary head are represented by the coordinates \(\textbf{B}_i^{\{Pos\}}\) in the \(\mathbb {R}^{\textbf{M}_i \times 4}\) space, where \(\textbf{M}_i\) is the total number of positive samples. To generate more personalized favorable queries, we employ the following approach:
Here, the notation \(\text {PE}(\cdot )\) represents positional encoding. We utilize the index pair \(\textbf{J}\) and \(\varvec{A}_\textbf{J}\) to select the relevant features from \(\text {E}(\cdot )\) based on positive or negative coordinates.
Multiple sets of queries, totaling \(\textbf{K} + 1\), are used throughout the training procedure. The one-to-one set matching branch uses one set, while the auxiliary paths that utilize one-to-many label assignments employ the remaining sets (\(\textbf{K}\)). This matching technique is unnecessary because all queries in the auxiliary branches are considered affirmative. The loss for the \(\mathfrak {L}\) decoder stage in the \(i\)-th auxiliary channel is as follows:
where \(\tilde{\textbf{P}}_{i,l}\) denotes the outcome prediction of the \(\mathfrak {L}\) decoder stage in the \(i\)-th auxiliary branch. The principal objective of the training is to:
The loss in the first one-to-one matching branch is represented as \(\tilde{\mathfrak {L}}_l^{Dec}\), and \(\alpha _1\) and \(\alpha _2\) are coefficients used to balance this loss.
Explanation of how Pc-DETR works
Pc-DETR greatly improves detectors based on DETR. We assess the efficacy of the method by employing both qualitative and quantitative measures. Specifically, we utilize Deformable-DETR47 with a ResNet-50 backbone in a training configuration that spans 42 epochs.
In order to enhance the supervision of the encoder, it has been observed that a scarcity of affirmative queries results in sparse supervision, as only one query per ground truth is supervised by regression loss. A technique that assigns labels in a one-to-many manner offers more focused supervision to positive samples, thereby improving the learning of latent features. We analyze the latent features generated by the encoder to investigate the impact of sparse supervision on model training.
The encoder output discriminability score was measured using the \(\text {IoF-IoB}\) curve. As seen in Fig. 6, using images found online for feature visualization ensures objectivity. The IoF-IoB curve, where IoF is the intersection with the foreground and IoB is the intersection with the background, is computed from this representation.
Once the encoder features at level \(\textbf{J}\) (\(\varvec{A}_j \in \mathbb {R}^{c \times h_j \times \omega _j}\)) have been obtained, we compute the \(\textbf{L}^2\)-norm \(\hat{\varvec{A}}_j \in \mathbb {R}^{1 \times h_j \times \omega _j}\) and adjust its size to match the image size \(h \times \omega\). The Discriminability Score, represented as \(\textbf{D}(\varvec{A})\), is computed by averaging the scores over all levels:
Figure 6 shows the discriminability scores of some models: ATSS, Deformable-DETR, and Pc-Deformable-DETR. Both ATSS and Pc-Deformable-DETR exhibit superior capability in discerning crucial object areas compared to Deformable-DETR, which is frequently impeded by the background. The foreground and background metrics are defined as follows: The expression \(\mathbb {Z}(\textbf{D}(\varvec{A}) > \textbf{S}) \in \mathbb {R}^{h \times \omega }\) indicates that the matrix resulting from the operation \(\mathbb {Z}(\textbf{D}(\varvec{A}))\) is greater than the matrix \(\textbf{S}\), with both matrices having dimensions \(h \times \omega\). Similarly, the expression \(\mathbb {Z}(\textbf{D}(\varvec{A}) < \textbf{S}) \in \mathbb {R}^{h \times \omega }\) signifies that \(\textbf{S}\) represents a predetermined threshold, while \(\mathbb {Z}(\chi )\) takes the value of 1 when \(\chi\) is true and 0 otherwise. The foreground mask, denoted as \(\textbf{M}^{fg}\) and having dimensions \(\mathbb {R}^{h \times \omega }\), takes the value of 1 if the coordinates \((h, w)\) correspond to a point inside the foreground; otherwise, it takes the value of 0. The calculation of the foreground intersecting area (IoF) \(\textbf{I}^{fg}\) is as follows:
We calculate the intersection for the background region (IoB) in a similar manner. The graph in Fig. 5, obtained by changing the value of \(\textbf{S}\), displays both the Index of Forwardness (\(\text {IoF}\)) and the Index of Backwardness (\(\text {IoB}\)). ATSS and Pc-Deformable-DETR demonstrate superior performance in terms of IoF and IoB metrics compared to Deformable-DETR, suggesting that the encoder benefits from the one-to-many label assignment.
Improving cross-attention learning requires lowering the volatility of Hungarian matching. One of the most basic one-to-one set matching algorithms, Hungarian matching, is unstable because it learns different positive queries within the same image at different times. Figure 7 shows that our method improves the stability of this process.
To provide a more precise measurement of cross-attention optimization, we computed the attention score using the IoF-IoB curve. To obtain several IoF-IoB pairs, we established different criteria for the attention score. Figure 5 illustrates a comparison between Deformable-DETR, Group-DETR, and Pc-Deformable-DETR. DETRs with a greater number of active queries typically show larger IoF-IoB curves compared to Deformable-DETR, indicating the success of our method.
The approach we employ is distinct from previous methods such as Group-DETR48, H-DETR40, and SQR49. These methods utilize one-to-many assignments with duplicate groups and truth frames. Pc-DETR assigns several positive values to each ground truth spatial coordinate, effectively utilizing densely supervised signals to directly enhance the discriminability of the prospective feature map. Although additional active queries have been implemented, other approaches continue to experience instability in Hungarian matching. Our method utilizes consistent one-to-many assignments while preserving precise correspondence between positive queries and accurate frames.
We are pioneers in examining detectors using both classic one-to-many allocation and one-to-one matching, which allows us to gain insights into their disparities and synergies. This enables us to improve DETR learning by utilizing standard one-to-many assignment designs without requiring any additional specific efforts.
Unlike other approaches that result in a large number of negative queries-which leads to a significant increase in GPU memory utilization-our decoder does not generate negative queries. As indicated in Table 11, our method exclusively handles positive coordinates in the decoder, resulting in decreased memory usage.

Comparison of model instability performance on the VisDrone dataset.
Experiments
In this chapter, we conduct ablation studies on each innovative aspect of our model and comparative experiments with other models. In section “Polysemantic transformer evaluation”, we focus specifically on the innovative Polysemantic Transformer Backbone (PoT), conducting comparative experiments to evaluate the efficiency and practicality of PoT from multiple dimensions. In section “Experiments on target detection in tilted images of UAVs”, we assess the performance enhancements brought about by applying the PoT module to traditional models.
In section “Depth experiments with Pc-DETR”, we undertake in-depth experiments on drone detection using the Pc-DETR model integrated with the PoT, including an analysis of the advantages offered by various auxiliary branches and levels. In section “Comparative analysis of advanced model experiments”, we compare the application of our modules against various advanced models to demonstrate the robust capabilities of our components. Section *Ablation Experiments on Pc-DETR Comparing and Visualizing Advanced Models* thoroughly examines the performance differences resulting from varying numbers of auxiliary heads and the performance disparities of individual auxiliary heads to identify the best auxiliary matching options.
Finally, in Section *Specifically Designed for UAV Image Inspection*, we compare our model with the most advanced drone aerial image detection models, showing a significant overall enhancement in capability.
Datasets
We use the public VisDrone dataset50 for our experiments, which encompass the training, validation, and testing phases. Our extensive model comparisons and ablation studies are based on this dataset.
To showcase our model’s capabilities, we selected the VisDrone dataset, known for target classification and object detection. This dataset includes images captured from UAVs in various scenes, weather conditions, and times of day. It features scenarios such as city streets, countryside, coastlines, and car parks. The dataset contains 10,209 images: 6471 for training, 3190 for testing, and 548 for validation, each with a resolution of 2000\(\times\)1500 pixels. It includes 342,391 objects categorized into 10 classes: car, truck, pedestrian, motor, tricycle, van, bus, people, awning-tricycle, and bicycle.
Additionally, to validate the model’s capabilities, we also use the UAVDT dataset51, which contains a total of 40,735 images, including 24,206 images in the training set and 16,529 images in the validation set. Unlike the VisDrone dataset, UAVDT focuses primarily on vehicle detection from the UAV viewpoint and contains only three predefined vehicle classes: car, bus, and truck.
Polysemantic transformer evaluation
This section presents an assessment of the usefulness of the Polysemantic Transformer (PoT) as a backbone through empirical evaluations on several computer vision tasks, such as image recognition and object detection. First, PoT is trained from scratch on 30% of the VisDrone dataset for the purpose of image classification. Afterwards, we perform pre-training on the complete VisDrone dataset using PoT. We then evaluate the capacity of the pre-trained Pc-DETR for object detection on the entire VisDrone dataset to determine its generalization capabilities.
Setup
Our initial step involves pre-training on 30% of the VisDrone benchmark dataset, which consists of 10 categories: vehicle, truck, pedestrian, motor, bicycle, tricycle, van, bus, people, and awning-tricycle. The model’s performance is assessed by measuring its top-1 and top-5 accuracies on the validation set. This evaluation is conducted under two different training settings: default and advanced.
The default parameters adhere to traditional vision architectures such as ResNet and SENet, employing typical preprocessing techniques for approximately 100 epochs. The input image is resized to dimensions of 224 \(\times\) 224 and undergoes random cropping and flipping with a 50% chance. All hyperparameters follow the official implementation without any further adjustments.
The PoT backbone is trained using stochastic gradient descent (SGD)52 with a momentum value of 0.9 and label smoothing of 0.1, in an end-to-end manner. The batch size is configured at 512, distributed evenly across 8 GPUs. During the initial five epochs, the learning rate is gradually increased from 0 to 0.1 times the batch size divided by 256. After that, it is reduced using a cosine schedule. During training, we utilize an exponential moving average with a weight of 0.99999.
The expanded training setup incorporates longer training durations and improved data augmentation and regularization techniques to ensure a fair comparison with state-of-the-art backbones such as ResNeSt53, EfficientNet54, and LambdaNetworks55. In this configuration, the PoT model is trained for 350 epochs using additional data augmentation techniques such as RandAugment56 and mixup57, as well as regularization techniques like dropout58 and DropConnect59.
Comparative performance experiments
We evaluate the performance of various cutting-edge visual backbones on the dataset using two training configurations: default and advanced. Table 3 shows the performance comparison for both settings at the same depth. We developed several versions of the PoT model with 50 and 101 layers, termed PoT-50 and PoT-101, respectively. In the advanced settings, we introduce an enhanced version of PoT called SE-PoTD-101, which replaces the 3 \(\times\) 3 convolutions in the ResNet-4 and ResNet-5 stages with PoT blocks under the SE-ResNetD-50 trunk. We also present the model’s performance using exponential moving averages in the default configuration to fairly compare with Lambda-ResNet.
Results in Table 3 consistently show that PoT-50 and PoT-101 outperform existing visual backbones, such as ResNet-50/101 and attention-based models like Stand-Alone and AA-ResNet-50/101, in top-1 and top-5 accuracy at the same depth. This improvement is achieved through efficient parameter utilization, highlighting the benefits of polysemantic contextual information in self-attentive learning for visual recognition tasks.
LRNet-50 and Stand-Alone models improve performance by effectively managing remote feature interactions through local self-attention, unlike ResNet-50. AA-ResNet-50 and Lambda-ResNet-50 enhance performance with global self-attention across the feature graph, but still lag behind more advanced ConvNet models that use channel feature recalibration to improve visual representation.
PoTNet-50 outperforms SE-ResNet-50 by replacing all 3 \(\times\) 3 convolutions with PoT blocks throughout the ResNet-50 structure. This study demonstrates that integrating polysemantic contextual mining with self-attentive learning and key aggregation in a single architecture significantly enhances representation learning and visual recognition. Additionally, applying the exponential moving average technique from Lambda-ResNet boosts the top-1 accuracy of PoT-50 and PoT-101 to 33.89% and 34.72%, respectively, surpassing the highest performance of TPH-YOLOv5 on the VisDrone dataset.
Ablation experiments on tilted images of UAV cities
This section focuses on analyzing the influence of each individual design feature in the PoT block on the overall performance of PoT-50. The PoT block begins by employing a 3\(\times\)3 convolution to extract the fixed polysemantic context among keys. By combining the question with these keys, we generate dynamic polysemantic contexts via self-attention. The PoT block integrates the static and dynamic contexts to provide the ultimate result. Additionally, we examine a modified version of the PoT block known as linear fusion, where the two contexts are combined by directly adding them together. Table 4 displays the results of various techniques used to investigate the multiple meanings of contextual information in the PoT-50 backbone. By exclusively relying on static polysemantic contexts for image identification, the accuracy of correctly identifying the top-ranked image is 31.37%. This approach operates similarly to a ConvNet without self-attention. The utilization of dynamic polysemantic contexts through self-attention leads to enhanced performance. The combination of static and dynamic contexts through linear fusion results in a top-1 accuracy of 33.15%, demonstrating the mutually beneficial relationship between the two. The PoT block, which effectively integrates both contexts, achieves a top-1 accuracy of 33.83%.
As shown in Table 5, we obtained the best matching rules by applying different size scales of \(k \times k\) grids in the ResNet-2 to ResNet-5 phases using PoT modules.
To demonstrate the correlation between performance and the number of PoT block replacement stages, we systematically replace stages (ResNet-2 \(\rightarrow\) ResNet-3 \(\rightarrow\) ResNet-4 \(\rightarrow\) ResNet-5) with PoT blocks in the ResNet-50 backbone and analyze the outcomes. Table 6 shows that increasing the number of PoT block replacements generally improves performance, even with a modest decrease in parameters and FLOPs.
Examining the data on transfer rate and precision reveals that substituting PoT blocks in the final two stages (ResNet-4 and ResNet-5) significantly enhances performance. However, introducing additional substitutions in the earlier stages (ResNet-1 and ResNet-2) yields only a slight improvement (a 0.2% increase in top-1 accuracy overall) while also resulting in a 1.18 times longer inference time. To achieve a more optimal balance between speed and accuracy, we developed SE-PoT-D-50, which replaces only the \(3 \times 3\) convolutions in ResNet-4 and ResNet-5 with PoT blocks in the SE-ResNet-D-50 backbone. The SE-ResNet-D-50 backbone is a modified version of ResNet-50 that incorporates ResNet-D and Squeeze-and-Excitation60 in all bottleneck blocks. Table 6 demonstrates that SE-PoT-D-50 outperforms SE-ResNet-D-50 with only a slight decrease in throughput.
Experiments on target detection in tilted images of UAVs
We assess the performance of pre-trained Points of Interest Transformers (PoT) on the complete VisDrone dataset for target recognition. We employ Faster R-CNN and Cascade R-CNN as the underlying detectors, substituting the ResNet backbone with PoTs. Based on the parameters specified in reference61, we evaluate the model’s performance on both the VisDrone training set (consisting of 6.5K images) and the validation set (consisting of 0.5K images) using a single-scale standard Average Precision (AP) measure.
During the training process, the size of the shorter edge of each input image is randomly selected from a range of 640–800 pixels. Feature Pyramid Networks (FPN) and batch normalization are utilized in training all models, employing a 1x learning rate scheme. To achieve a fair comparison with other visual backbones, we standardized all hyperparameters and detection heads based on the specifications provided in the reference paper by Zhang et al.53.
Table 7 presents a summary of the performance comparison on the VisDrone dataset. The comparison is based on the use of Faster R-CNN and Cascade R-CNN for target identification, utilizing various pre-trained backbones. We categorize visual trunks based on their network depth, which can be either 50 or 101 layers. The performance of our pre-trained PoT model (PoT-50/101) is significantly better than that of ConvNet backbones (ResNet-50/101) across all IoU thresholds and object sizes. The results demonstrate the benefits of integrating self-attentive learning with polysemantic contextual information mining in PoT, resulting in excellent accuracy in recognizing small UAV targets.
Depth experiments with Pc-DETR
We perform comprehensive model trials on the VisDrone dataset, showcasing results specifically for the validation subset. Additionally, we present the outcomes of the model’s evaluation on the test development subset, which consists of 3.2K images.
Experiment details
We incorporate Pc-DETR into the current DETR-like pipeline, following the same training settings as the baseline. We utilize ATSS and Faster-RCNN as auxiliary heads with a value of \(\textbf{K} = 2\), but we retain only ATSS when \(\textbf{K} = 1\). The number of learnable object queries is set to 300, with coefficients \(\{\alpha _1, \alpha _2\}\) assigned values of \(\{1.0, 2.0\}\). For Pc-DINODeformable-DETR++, we employ a technique known as large-scale dithering via copy-paste, as described in the paper by Ghiasi et al.63.
Core results
In this section, we evaluate the efficacy and capacity for generalization of Pc-DETR in comparison to different forms of DETR, as demonstrated in Tables 8 and 9. All results are replicated using the mmdetection framework (Chen et al.64). Initially, we utilized collaborative hybrid task training on single-scale DETRs using C5 features. Notably, Conditional-DETR and DAB-DETR achieved improvements of 2.5% and 2.2% in average precision (AP), respectively, compared to the baseline when using the long-term training approach.
The utilization of multi-scale features in Deformable-DETR resulted in a significant enhancement in detection performance, increasing the average precision (AP) from 27.1% to 33%. The overall enhancement (+ 3.6% AP) remained stable despite the prolonged training period of 42 epochs. Additionally, testing conducted on the improved Deformable-DETR (Deformable-DETR++) showed a 2.2% increase in average precision (AP). When our method is applied to the advanced DINO-Deformable-DETR, it achieves an average precision (AP) of 49.5%, which is 1.6% higher than the benchmark set by competitors.
We expanded the capacity of the backbone network from ResNet-50 to PoT-50, building upon two cutting-edge baseline models. Table 3 demonstrates that Pc-DETR attained an average precision (AP) of 51.3%, surpassing the Deformable-DETR++ baseline by a notable margin of 1.5% AP. Furthermore, the performance of DINO-Deformable-DETR with PoT-50 was enhanced from 51.2% to 52.6% in terms of average precision (AP).
Comparative analysis of advanced model experiments
We utilize the \(\textbf{K} = 2\) methodology for both Deformable-DETR++ and DINO. Additionally, our Pc-DINO-Deformable-DETR incorporates mass focus loss65 and non-maximum suppression (NMS).
As indicated in Table 10, our approach exhibits more rapid convergence on the VisDrone validation set compared to our competitors. A successful model, Pc-DINO-Deformable-DETR, achieves an impressive 35.7% average precision (AP) in only 18 epochs using the PoT-50 backbone. Our PoT-50 technique achieves an average precision (AP) of 35.3% utilizing a 1\(\times\) scheduler, surpassing other cutting-edge frameworks that use 3\(\times\) schedulers.
Our leading model, Pc-DINO-Deformable-DETR++, achieves an impressive 31.2% Average Precision (AP) when using ResNet-50 as the backbone and 37.1% AP with PoT-50 after 42 epochs of training. It is worth noting that our model outperforms all other detectors that use the same backbone.
Ablation experiments on Pc-DETR
The ablation tests were conducted on a Deformable-DETR model using a PoT-50 backbone. By default, we assign a value of 1 to the auxiliary head \(\textbf{K}\) and set the total batch size to 42.
Elimination of various auxiliary heads
We analyzed the criteria used to choose auxiliary heads, as presented in Tables 11 and 12. The findings suggest that including an auxiliary head with label assignments that have a one-to-many relationship consistently enhances the performance of the baseline model. Among the various approaches, ATSS demonstrates the highest level of performance. Our findings indicate that the accuracy of the results improves as the number of auxiliary heads, denoted as \(\textbf{K}\), increases, but only when \(\textbf{K}\) is less than 3. However, performance diminishes when the value of \(\textbf{K}\) is set to 6, most likely due to conflicts arising from the auxiliary heads. As the value of \(\textbf{K}\) increases, inconsistent feature learning among auxiliary heads can hinder development.
The additional material analysis demonstrates that any head can function as an auxiliary head, with ATSS and Faster-RCNN being frequently employed to achieve optimal performance when \(\textbf{K} \le 2\). To mitigate optimization conflicts, we refrain from utilizing an excessive number of distinct entities, such as six.

Comparison of different K values for auxiliary heads.

Primitive and customised query matching.

Model attention visualisation heatmap. The first column is the original image, the second column is the MFEFNet model, and the third column is our model Pc-DETR.

Some visualisation results of our Pc-DETR on the test set challenge, with different categories using different coloured bounding boxes. This performance is good at localising tiny objects, dense objects and objects with blurred motion, in addition to achieving better forward capture in terms of capturing objects, with fewer invalid areas to capture.
Conflicts may hinder the training of detectors when multiple foreground boxes are assigned the same spatial coordinates or when those coordinates are considered background in different auxiliary heads. To tackle this issue, we estimate the mean gap of \(\textbf{H}_i\) and the gap between head \(\textbf{H}_j\) to quantify the conflict in improvement.
When the same spatial coordinates are assigned to separate foreground areas or considered as background in several auxiliary heads, conflicts may complicate detector training. We measure both the average gap of \(\textbf{H}_i\) and the gap between head \(\textbf{H}_j\) to quantify this optimization conflict. This distance considers the class activation map, dataset, input image, and dispersion.
We calculate the average distance between auxiliary heads for \(\textbf{K} > 1\) and the distance between the DETR heads and one auxiliary head for \(\textbf{K} = 1\), as shown in Figure 8. After conducting the analysis, we found that for \(\textbf{K} = 1\), the distance metric for each auxiliary head is not statistically significant. Table 12 shows that this is consistent with the results. When the value of \(\textbf{K}\) is equal to 1, the performance of the DETR head is enhanced by the presence of any auxiliary head. As the value of \(\textbf{K}\) increases to 2, the distance metric experiences a modest increase, resulting in the best performance, as indicated in Table 11.
However, as the value of \(\textbf{K}\) increases from 3 to 6, there is a significant spike in the distance, suggesting severe conflicts in optimization between these auxiliary heads, which results in a decline in performance. For example, after substituting the 6 ATSS with 6 distinct heads, the achieved average precision (AP) decreases from 42.6% to 41.8%. Therefore, we hypothesize that the presence of more than three distinct auxiliary heads intensifies disagreements. Optimizing for conflict depends on the quantity and interconnections of auxiliary heads.
Collaborative training that includes two ATSS heads (with an average precision of 39.2%) yields better results compared to using only one ATSS head (with an average precision of 38.9%). This improvement can be attributed to the complementary nature of the ATSS and DETR heads. By incorporating several auxiliary heads, such as Faster-RCNN, instead of duplicating the same head, there is a significant improvement in performance, yielding a 42.6% increase in average precision (AP). This confirms our prior finding: employing a small number of distinct heads (\(\textbf{K} \le 2\)) results in optimal performance with low disagreement, whereas employing a large number of distinct heads (\(\textbf{K} \ge 3\)) leads to substantial disputes.
Composition analysis experiments
We conducted component ablation to evaluate the influence of each element, as shown in Table 13. Merging the auxiliary heads leads to significant enhancements, as the inclusion of comprehensive spatial supervision improves the encoder’s capacity to distinguish between different inputs. In addition, the inclusion of personalized affirmative inquiries greatly enhances the overall results and improves the effectiveness of individualized set matching training. These strategies improve both the speed of convergence and the overall performance.
Overall, the enhancements arise from the utilization of more discerning encoder characteristics and more effective attention-based learning in the decoder. As shown in Table 14, the performance of Deformable-DETR does not improve with extended training and reaches a plateau. On the other hand, Pc-DETR significantly speeds up the process of reaching a solution and improves the highest level of performance. Furthermore, Pc-DETR regularly enhances the auxiliary heads, as demonstrated in Table 15. This illustrates that our training methodology enhances the encoder’s ability to distinguish between different inputs, thereby benefiting both the decoder and the auxiliary heads.
Comparison of differences in original query distribution
The disparity in the allocation of unaltered and tailored affirmative inquiries is illustrated in Fig. 9a, which shows the spatial distribution of both types of requests. Each image displays a solitary object enclosed in a green box. In the decoder, positive questions from Hungarian matches are indicated in red, whereas positive queries from ATSS and Faster-RCNN are marked in blue and orange, respectively. These customized queries target the central region of the case and provide the detector with a wealth of supervisory signals. As shown in Fig. 9b, we also calculate the mean gap between the initial and adapted searches. Initial inquiries and the customized negative queries are separated by a significantly smaller mean distance than the initial negative questions and the customized positive queries. Training remains constant since there is a modest distribution difference between raw and tailored queries.
Comparing and visualizing advanced models specifically designed for UAV image inspection
To illustrate our Pc-DETR model’s significant advantages for UAV image identification, we not only outperform several state-of-the-art baseline target detection models but also conduct a comparison with the leading UAV image detection models, namely TPH-YOLOv5 (Zhu et al.72) and MFEFNet (Zhou et al.73).
As shown in Table 16, our model achieves a mean average precision (mAP) of 54.9%, which is 3% greater than the most recent state-of-the-art (SOTA) model, MFEFNet. Especially in the AP_ s metric, our model achieves an accuracy of 36.9%, which is higher than the existing state-of-the-art detection models in both small target detection capabilities. The FPS processing capability demonstrates strong performance compared to other advanced models, enabling potential applications in realistic scenarios. Furthermore, our model consistently achieves a high level of accuracy across nearly all areas. As depicted in Fig. 10, our model surpasses MFEFNet in terms of model attention heat maps, effectively capturing a wider range of targets with greater accuracy.
In Fig. 11, we optimized the parameters of the Pc-DETR model using the VisDrone2019 dataset for testing. The results clearly demonstrate that our model successfully detects various types of targets with exceptional accuracy.
Finally, as shown in Table 17, in order to validate the general ability of our model on other datasets, we conducted a performance evaluation of our model on the UAVDT dataset. Compared with advanced UAV target detection models, we have achieved a high level of performance in all metrics, and are still substantially ahead of advanced models in small target detection capability, while still maintaining fast detection performance, ensuring that the model is suitable for real-time applications in a variety of real-world scenarios.
Discussion
The comprehensive ablation experiments conducted in this research showcase the distinct capabilities of each individual component. The PoT Backbone module effectively substitutes typical convolutions in ResNet designs while adhering to a favorable parameter budget. By merging contextual mining and self-attention into a single architecture, this module utilizes contextual data from input keys to support self-attention learning, enhancing the visual representation of UAV images.
In the Pc-DETR framework, we demonstrate the benefits of employing multiple label assignments and parallel auxiliary heads, which are governed by one-to-many label assignments. This approach improves the efficiency and effectiveness of end-to-end UAV image detectors and enhances the encoder’s ability to learn while optimizing the training of positive samples in the decoder.
Nevertheless, Pc-DETR still has the potential for further optimization. Although the accuracy is significantly improved, the addition of more auxiliary heads results in increased computational requirements and parameter counts during training, leading to higher time and cost. Future studies will prioritize enhancing precision while minimizing computational requirements and the number of parameters used in training. This will help preserve the model’s lightweight attributes during both training and inference, making it more deployable and suitable for real-time detection of small targets in UAV aerial photography.
Conclusion
To address the challenges associated with detecting objects in UAV aerial photos, we propose a new module called the Polysemantic Transformer (PoT) block, which is based on the Transformer architecture. This module is designed to enhance target visual identification by utilizing contextual information between input keys to accelerate the development of dynamic attention matrices.
Furthermore, we introduce the Polysemantic Cooperative Mixed-Task Training scheme (Pc-DETR), which employs several label assignment techniques to improve the efficiency of DETR-based detectors. This approach enhances the learning capacity of the encoder in end-to-end detectors for UAV images. Additionally, we incorporate customized positive queries and extract positive positioning from the auxiliary head to further improve the learning efficacy of positive samples in the decoder.
Our Pc-DETR network has been extensively tested using comparison and ablation experiments. The results clearly demonstrate that our network improves visual representation and provides a more efficient end-to-end UAV image detector by integrating various label assignment methods into the learning process. The Pc-DETR network shows a 3% increase in mAP@0.5 compared to the state-of-the-art MFEFNet UAV detection network on the VisDrone public dataset.
While there has been notable advancement in detecting aerial images using UAVs, the inclusion of supplementary heads during the training process adds processing burden; however, this is not the case during inference. Future research will focus on optimizing the computational cost of training to establish a mode that is both efficient and accurate in terms of inference. We will continue to advance studies on UAV target detection.
Data availability
The datasets used and/or analyzed during the current study available from the corresponding author on reasonable request.
References
Xue, Y., Jin, G., Shen, T., Tan, L. & Wang, L. Template-guided frequency attention and adaptive cross-entropy loss for uav visual tracking. Chin. J. Aeronaut. 36, 299–312 (2023).
Xue, Y. et al. Mobiletrack: Siamese efficient mobile network for high-speed uav tracking. IET Image Proc. 16, 3300–3313 (2022).
Xue, Y. et al. Consistent representation mining for multi-drone single object tracking. IEEE Trans. Circuits Syst. Video Technol. 2024, 56 (2024).
Xue, Y. et al. Handling occlusion in uav visual tracking with query-guided redetection. IEEE Trans. Instrum. Meas. 2024, 96 (2024).
Xue, Y. et al. Smalltrack: wavelet pooling and graph enhanced classification for uav small object tracking. IEEE Trans. Geosci. Remote Sens. 2023, 785 (2023).
Zhang, X., Izquierdo, E. & Chandramouli, K. Dense and small object detection in uav vision based on cascade network. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (2019).
Tang, T., Deng, Z., Zhou, S. et al. Fast vehicle detection in uav images. In 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP) 1–5 (IEEE, 2017).
Chen, Y., Li, J., Niu, Y. et al. Small object detection networks based on classification-oriented super-resolution gan for uav aerial imagery. In 2019 Chinese Control And Decision Conference (CCDC) 4610–4615 (IEEE, 2019).
Zhou, J. et al. Scale adaptive image cropping for uav object detection. Neurocomputing 366, 305–313 (2019).
Hou, X. et al. Object detection in drone imagery via sample balance strategies and local feature enhancement. Appl. Sci. 11, 3547 (2021).
Oliva, A. & Torralba, A. The role of context in object recognition. Trends Cogn. Sci. 11, 520–527 (2007).
Liang, X. et al. Small object detection in unmanned aerial vehicle images using feature fusion and scaling-based single shot detector with spatial context analysis. IEEE Trans. Circuits Syst. Video Technol. 30, 1758–1770 (2019).
Hong, M. et al. Sspnet: Scale selection pyramid network for tiny person detection from uav images. IEEE Geosci. Remote Sens. Lett. 19, 1–5 (2021).
Viola, P. & Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, vol. 1 I–I (IEEE, 2001).
Viola, P. & Jones, M. J. Robust real-time face detection. Int. J. Comput. Vis. 57, 137–154 (2004).
Dalal, N. & Triggs, B. Histograms of oriented gradients for human detection. In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), vol. 1 886–893 (IEEE, 2005).
Felzenszwalb, P., McAllester, D. & Ramanan, D. A discriminatively trained, multiscale, deformable part model. In 2008 IEEE Conference on Computer Vision and Pattern Recognition 1–8 (IEEE, 2008).
Redmon, J. & Farhadi, A. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767 (2018).
Ren, S. et al. Faster r-cnn: towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 28, 859 (2015).
Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision 1440–1448 (2015).
He, K., Gkioxari, G., Dollár, P. & Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision 2961–2969 (2017).
Zhang, S., Chi, C., Yao, Y. et al. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 9759–9768 (2020).
Lin, T.-Y., Goyal, P., Girshick, R. et al. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision 2980–2988 (2017).
Tian, Z., Shen, C., Chen, H. & He, T. Fcos: Fully convolutional one-stage object detection. arxiv 2019. arXiv preprint arXiv:1904.01355 (2019).
Kim, K. & Lee, H. S. Probabilistic anchor assignment with iou prediction for object detection. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXV 355–371 (Springer International Publishing, 2020).
Carion, N., Massa, F., Synnaeve, G. et al. End-to-end object detection with transformers. In European Conference on Computer Vision 213–229 (Springer International Publishing, 2020).
Vaswani, A. et al. Attention is all you need. Adv. Neural Inf. Process. Syst. 30, 236 (2017).
Wang, X., Girshick, R., Gupta, A. & He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 7794–7803 (2018).
Bello, I., Zoph, B., Vaswani, A. et al. Attention augmented convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision 3286–3295 (2019).
Hu, H., Zhang, Z., Xie, Z. et al. Local relation networks for image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision 3464–3473 (2019).
Zhao, H., Jia, J. & Koltun, V. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 10076–10085 (2020).
Chen, M. et al. Generative pretraining from pixels. In International Conference on Machine Learning 1691–1703 (PMLR, 2020).
Dosovitskiy, A., Beyer, L., Kolesnikov, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
Srinivas, A., Lin, T.-Y., Parmar, N. et al. Bottleneck transformers for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 16519–16529 (2021).
Zhu, L., Wang, X., Ke, Z., Zhang, W. & Lau, R. W. Biformer: Vision transformer with bi-level routing attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 10323–10333 (2023).
Li, F., Zhang, H., Liu, S. et al. Dn-detr: Accelerate detr training by introducing query denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 13619–13627 (2022).
Zhang, H., Li, F., Liu, S. et al. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv preprint arXiv:2203.03605 (2022).
Liu, S., Li, F., Zhang, H. et al. Dab-detr: Dynamic anchor boxes are better queries for detr. arXiv preprint arXiv:2201.12329 (2022).
Chen, Q., Chen, X., Zeng, G. et al. Group detr: Fast training convergence with decoupled one-to-many label assignment. arXiv preprint arXiv:2207.130852, 12 (2022).
Jia, D., Yuan, Y., He, H. et al. Detrs with hybrid matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 19702–19712 (2023).
Ren, S. et al. Faster r-cnn: towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39, 1137–1149 (2016).
Tian, Z., Shen, C., Chen, H. et al. Fcos: Fully convolutional one-stage object detection. arXiv preprint arXiv:1904.01355 (1904).
He, K., Zhang, X., Ren, S. et al. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 770–778 (2016).
Haase, D. & Amthor, M. Rethinking depthwise separable convolutions: How intra-kernel correlations lead to improved mobilenets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 14600–14609 (2020).
Chen, J., Wang, X., Guo, Z. et al. Dynamic region-aware convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 8064–8073 (2021).
Li, Y., Mao, H., Girshick, R. et al. Exploring plain vision transformer backbones for object detection. In European Conference on Computer Vision 280–296 (Springer Nature Switzerland, 2022).
Zhu, X., Su, W., Lu, L. et al. Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159 (2020).
Chen, Q., Chen, X., Wang, J. et al. Group detr: Fast detr training with group-wise one-to-many assignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision 6633–6642 (2023).
Chen, F., Zhang, H., Hu, K. et al. Enhanced training of query-based object detection via selective query recollection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 23756–23765 (2023).
Du, D., Zhu, P., Wen, L. et al. Visdrone-det2019: the vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (2019).
Du, D. et al. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV) 370–386 (2018).
Loshchilov, I. & Hutter, F. Stochastic gradient descent with warm restarts. arXiv preprint arXiv:1608.03983 (2016).
Zhang, H. et al. Resnest: Split-attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2736–2746 (2022).
Tan, M. & Le, Q. Efficientnet: rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning, Proceedings of Machine Learning Research 6105–6114 (2019).
Bello, I. Lambdanetworks: modeling long-range interactions without attention. arXiv preprint arXiv:2102.08602 (2021).
Cubuk, E. D., Zoph, B., Shlens, J. & Le, Q. V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops 702–703 (2020).
Zhang, H., Cisse, M., Dauphin, Y. N. & Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412 (2017).
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I. & Salakhutdinov, R. Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15, 1929–1958 (2014).
Wan, L., Zeiler, M., Zhang, S., Le Cun, Y. & Fergus, R. Regularization of neural networks using dropconnect. In International Conference on Machine Learning, Proceedings of Machine Learning Research 1058–1066 (2013).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 7132–7141 (2018).
Xie, S., Girshick, R., Dollár, P., Tu, Z. & He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 1492–1500 (2017).
Cai, Z. & Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 6154–6162 (2018).
Ghiasi, G. et al. Simple copy-paste is a strong data augmentation method for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2918–2928 (2021).
Chen, K. et al. Mmdetection: Open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155 (2019).
Li, X. et al. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural. Inf. Process. Syst. 33, 21002–21012 (2020).
Meng, D. et al. Conditional detr for fast training convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision 3651–3660 (2021).
Wang, Y., Zhang, X., Yang, T. & Sun, J. Anchor detr: Query design for transformer-based detector. In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36 2567–2575 (2022).
Gao, Z., Wang, L., Han, B. & Guo, S. Adamixer: A fast-converging query-based object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 5364–5373 (2022).
Wu, T.-H., Wang, T.-W. & Liu, Y.-Q. Real-time vehicle and distance detection based on improved yolo v5 network. In 2021 3rd World Symposium on Artificial Intelligence (WSAI) 24–28 (IEEE, 2021).
Zhou, L. et al. A multi-scale object detector based on coordinate and global information aggregation for uav aerial images. Remote Sens. 15, 3468 (2023).
Wang, G. et al. Uav-yolov8: a small-object-detection model based on improved yolov8 for uav aerial photography scenarios. Sensors 23, 7190 (2023).
Zhu, X., Lyu, S., Wang, X., Zhao, Q. & Wang, X. Tph-yolov5: Improved yolov5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2778–2788 (2021).
Zhou, L., Zhao, S., Wan, Z. & Zhang, Y. Mfefnet: a multi-scale feature information extraction and fusion network for multi-scale object detection in uav aerial images. Drones 8, 186 (2024).
Ge, Z., Liu, S., Wang, F., Li, Z. & Sun, J. Yolox: exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430 (2021).
Acknowledgements
The authors would like to express their gratitude to the National Natural Science Foundation of China (Grant No. 11761066) and the Doctoral Fund of Xinjiang University (Grant No. 62031224735) for their financial support of this study.
Author information
Authors and Affiliations
Contributions
Conceptualization, X.L. and A.R.; Methodology, X.L. and X.G.; Software, X.L. and X.G. ; Validation, X.L. and X.G.; Formal Analysis, X.L.; Investigation, X.L.; Resources, X.L.; Data Curation, X.L.; Writing-Original Draft Preparation, X.G. and Y.Z.; Writing-Review & Editing, A.R.; Visualization, X.G. and X.L.; Supervision, A.R. and A.H.; Project Administration, A.R. and A.H.; Funding Acquisition, A.R. and A.H.; All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liao, X., Guo, X., Rozi, A. et al. End to end polysemantic cooperative mixed task trainer for UAV target detection. Sci Rep 14, 29775 (2024). https://doi.org/10.1038/s41598-024-81201-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-81201-8
