
Abstract
With the development of automatic driving technology, the correct driving of autonomous vehicles on the road is a research hotspot at present. Affected by the complex road traffic conditions and driving environment, the current autonomous vehicle’s ability to accurately identify road targets through on-board cameras still needs to be improved. Aiming at the problems of near-target error detection and remote target missing detection in road target detection of autonomous vehicles, an improved road target detection algorithm YOLOv8-RTDAV based on YOLOv8n was proposed. To address the issue of false alarms caused by close-range overlapping road targets, we propose a new C2f module, C2f-EFB, which combines an efficient channel attention (ECA) mechanism. To address the issue of missed detections in long-distance road target recognition, we have added a P2 small target detection layer for improvement. To improve the adaptability of the model and better capture image details and feature information, we replaced the SPPF module of the original model with the SPPELAN module and implemented upsampling using the point sampling module DySample. Improve the loss function CIOU of the original model to EIOU to further enhance the detection accuracy of the model for road targets. Experiments have shown that in the KITTI and TT100K datasets, the improved road object detection algorithm has improved accuracy to varying degrees compared to YOLOv8n. Improved the recognition accuracy of close-range overlapping targets on the road and increased the recognition rate of small targets at long distances.
Similar content being viewed by others
Introduction
Against the backdrop of the rapid development of autonomous driving technology, the ability of autonomous vehicles to accurately detect road targets has become a crucial prerequisite for ensuring the safe and stable operation of these vehicles. As a vital component of vehicle perception tasks, target detection has achieved remarkable progress in recent years. However, with the increasing complexity of urban road environments, autonomous vehicles are prone to encountering the problem of pedestrians and vehicles overlapping in close-range complex scenarios during driving, as well as the situation of missed detections in long-distance target detection. Both of these issues pose severe challenges to the performance of target detection algorithms. These challenges have made improving the accuracy of vehicle target detection the top priority in current research.
The development of YOLO series algorithms, from YOLOv31 to YOLOv8, has brought continuous progress and transformation to road object detection in autonomous vehicle driving. Xiaolan et al.2 improved the Tiny—YOLOv3 algorithm by adding a Spatial Pyramid Pooling (SPP) module to increase the number of feature channels, thereby enhancing the feature extraction ability of the network. However, as the input image size increases or the number of pyramid layers increases, the computational cost increases significantly. In YOLOv8, the SPPF was introduced. Sharing convolution kernels at different scales and using other methods, reduces the computational cost and number of parameters. While ensuring the feature extraction effect, it improves the running speed of the model, enabling YOLOv8 to maintain a good performance in real-time object detection tasks. Huixuan et al.3 added a Convolutional Block Attention Module (CBAM) to the YOLOv4 network. This increases the weights of the useful features while suppressing the weights of invalid features, thereby improving the detection accuracy of the model. The ability of CBAM, its ability to enhance and select features is of great assistance to object-detection networks. For example, when detecting road objects, the weights of information channels related to the unique colors of objects in the color channels will increase facilitating the model to better identify road objects. Hao et al.4 introduced a Bidirectional Feature Pyramid Network (BiFPN) based on the addition of CBAM to the YOLOv5 network, thereby enhancing the detection ability for objects of different sizes. By performing multiple fusion operations between feature maps at different scales, the BiFPN can effectively integrate multi-scale information. Kawoosa et al.5 improved the C3 module of YOLOv5 by introducing a GAM attention mechanism, enhancing the module’s feature extraction ability for images, and achieving an improvement in accuracy. Ahmed et al.6 proposed a Residual Channel Attention (RCA) network, which can more effectively extract the key features in images. In practical applications, the data features in different scenarios often vary. Ahmed7 utilized semi-automated dataset construction and the enhanced YOLOv8 to address the generalization problem of the object detection model caused by the differences in data from different domains. Ahmed et al.8using a semi-self-built dataset and the modified YOLOv4, combined with domain adaptation technology, enabled the improved YOLOv4 model to achieve good detection results on data from different domains. Different from enhancing the feature extraction ability of images in model design, Ahmed et al.9 adopted top-hat and bottom-hat transformations to assist morphological operations in the detection stage, which effectively enhanced the features of vehicle targets. Chi et al.10 introduced the BiFormer attention mechanism into the YOLOv7 network to improve the accuracy of the detection model for road traffic signs. The detection accuracy was improved while maintaining almost the same speed as the original network, the detection accuracy is improved. BiFormer, through the sparse sampling of the dual-layer routing attention mechanism, greatly reduces the computational cost and memory usage without losing too much information. Najihah Muhamad Zamri et al.11 introduced a P2 detection layer based on the YOLOv8n model to increase the detection accuracy of small aerial targets. However, the model size is significantly increased, which is not conducive to deployment on edge devices. From an aerial overhead perspective, both the ground targets and the distant targets during vehicle driving are small. Designing and improving the model using deep learning technology in remote sensing data has certain reference significance for improving the recognition accuracy of small targets12.
In the running scene of autonomous vehicles, close-distance road conditions are complex and changeable, and pedestrians and vehicles interact frequently, which often leads to false detection problems. When autonomous vehicles are near environments such as city streets, narrow intersections, or crowded parking lots, the motion trajectories of pedestrians and vehicles are intertwined. For example, at intersections near commercial pedestrian streets, pedestrians may suddenly exit between vehicles parked on the roadside or shuttles between vehicles as they move more slowly. At this point, when the vehicle’s perception camera captures road target information, the image features of pedestrians and vehicles may interfere with each other owing to a partial overlap in the two-dimensional space. For deep-learning-based object detection algorithms, the overlapping features may be difficult to extract and distinguish correctly. The target detection algorithm may mistakenly identify overlapping features as a new, fuzzy target, mistakenly identify pedestrians and vehicles as the same type of target, and mistakenly recognize road traffic signs, thus causing deviations in the perception of the vehicle auto-drive system to the surrounding environment. This type of false detection may lead to a series of serious consequences, such as unnecessary sudden braking and incorrect driving route planning, which seriously affect the safety and driving efficiency of autonomous vehicles. Focusing on autonomous vehicles, with the increase of the target distance on the road, the detection and recognition of the target by the perception camera gradually becomes difficult. The characteristics of distant targets themselves are also key to the frequent problem of missed object detection. Some distant targets are small from a two-dimensional perspective, have low contrast with the surrounding environment, and are easily overlooked. The schematic diagrams of the two main detection problems mentioned above are shown in Fig. 1.
To improve the problem of false detection of close targets on the road and missed detection of remote targets by the on-board camera of autonomous vehicles while driving, this paper proposes a solution using an improved model, YOLOv8-RTDAV, based on YOLOv8n. Its innovative points are as follows:
-
1)
To address the problem of target overlap caused by factors such as angle and color at close range when autonomous vehicles are driving on the road, a C2f-EFB module integrating the ECA13 attention mechanism is proposed.
-
2)
To tackle the issue of missed detection of small long-range targets when autonomous vehicles are driving on the road, a small target detection layer P2 is introduced.
-
3)
To further improve the detection and recognition ability of autonomous vehicles to road targets, the dynamic point sampling module DySample14 and the SPPELAN module of YOLOv915 are introduced.
-
4)
The original loss function CIOU in the model is replaced with EIOU16 to better optimize the model’s detection accuracy.

Main target detection and existing problems of autonomous vehicles.
Method
Compared with previous versions of the YOLO series algorithms, YOLOv8 has made adjustments to models of different scales. Faced with different testing environments and requirements, YOLOv8 is divided into five specific model categories: n, s, m, l, and x. The main structure of YOLOv8 consists of a backbone, neck, and head. Multiple C2f and Conv modules are used to extract features from input images and further process them, ultimately outputting object detection results. This study is based on the YOLOv8 model. The improved model structure is shown in Fig. 2, where the improved modules have been marked in the figure.

YOLOv8-RTDAV structure diagram.
Improvement of close-range target detection
When autonomous vehicles are driving on complex roads such as urban street scenes, they need to identify and distinguish road targets due to many factors such as traffic conditions. This relies on the efficient operation of the perception system, and as one of the main perception devices, the onboard camera plays a crucial role in detecting and recognizing road targets. Aiming at the problem of false detection caused by overlapping close targets when autonomous vehicles use on-board cameras to detect road targets, improved methods based on YOLOv8n target detection algorithm are proposed:
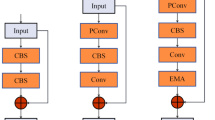
1) The C2f-EFB module: From the perspective of network structure, the C2f module was designed to efficiently process the feature maps. In terms of feature processing, the C2f structure integrates the advantages of the focal mechanism. The focus mechanism usually processes the input feature map through slicing operations at the front end of the network, increasing the number of channels and reducing the spatial dimensions, thereby enabling the network to focus on the important feature information. In the C2f module, this effective feature filtering and enhancement mechanism is further deepened, which can better capture target features at different scales. However, further improvements are required for the feature extraction of road targets. Therefore, the concept of FasteBlock is introduced to replace some Bottleneck modules in C2f, and the ECA attention mechanism is introduced after the PConv convolution operation and MLP stage in this module. ECA is added in the final output stage of C2f to form C2f-EFB, which reduces the model parameter quantity, improves the computational efficiency, and ultimately enhances the ability to extract road target features. In general, the feature fusion process of the C2f-EFB module is as follows: The input image first undergoes feature extraction through a convolutional layer (Conv), and then the convolved data is split. The split images are processed in the EFaterBlock layer. The processed features are concatenated through a concatenation operation (Concat), and the concatenated image is further processed through another convolutional layer. Finally, the ECA module performs an attention operation on the channels to obtain the final output.
The structure of C2f-EFB is shown in Fig. 3(b). Compared with the original C2f model (as shown in Fig. 3(a)), the input image is first subjected to a convolutional layer (Conv) for feature extraction, and the convolved data are then split. The segmented images are then processed in EFaterBlock layers, as shown in Fig. 3(c). The features are then concatenated through a concatenation operation (Concat), and the merged image is further processed through a convolutional layer. Finally, the ECA module performed attention operations on the channels to obtain the final output.
2) The ECA attention mechanism: Wang et al.13 proposed an Efficient Channel Attention mechanism ECA (efficient channel attention), which improved the performance compared to channel attention mechanisms with fewer parameters. Specifically, ECA avoids the dimensionality reduction operation in the channel attention module by adopting a local cross-channel interaction strategy and utilizing 1D convolution to achieve efficient channel attention calculation. Applying ECA to road target detection networks can filter and extract key information from images, eliminate other interfering factors, and improve the model’s detection and recognition of main road targets by the model.

Schematic diagram of C2f(a), C2f-EFB(b), and EFasterBlock(c) structures.

The ECA schematic diagram.
The above Fig. 4 specifically describes the principle of ECA. First, perform a Global Average Pooling (GAP) operation on the input features, assuming that the shape of the input features is \(\:H\times\:W\times\:C\) (where \(\:H\:\)is height, \(\:W\:\)is width, and \(\:C\) is the number of channels). After the GAP operation, the feature map is compressed into a vector of \(\:1\times\:1\times\:C\). This vector represents the global average for each channel. After obtaining the features aggregated through GAP, the ECA module generates channel weights by performing a fast 1D convolution of size. Assume that the size of the convolution kernel is k, and the intermediate result is shown in formula (2). The figure is labeled \(\:k=\left(\text{C}\right)\), which indicates that the kernel size is adaptively selected based on the number of channels. This figure shows an example of \(\:k=5\). The result of the 1D convolution is passed through the sigmoid activation function to map the output value to the (0,1) interval to obtain the channel attention weights. The channel attention weights are multiplied element by element with the original input feature map to obtain the feature map processed by the channel attention mechanism, with the final shape still being \(\:H\times\:W\times\:C\). The formula are:
Where \(\:{\omega\:}_{m}\) is the weight of the convolution kernel at position m. For each channel c of the output feature \(\:{X}_{conv}\), it is obtained by summing the products of the elements within the range of \(\:\left[\frac{k}{2}\right]\) channels to the left and right centered on channel c in \(\:{X}_{gap}\) (the boundary-handling function \(\:\text{max}\left(0,\text{min}\left(C-1,c+m\right)\right)\) is used to prevent channel index out-of-bounds) and the convolution kernel weights \(\:{\omega\:}_{m}\).
3) The PConv module: Partial Convolution (PConv)17 is an operation in convolutional neural networks aimed at improving computational efficiency, as shown in Fig. 5. It performs convolution operations only on a portion of the input feature map rather than the comprehensive application of traditional convolution operations. PConv achieves fast and efficient feature extraction by applying filters to only a small portion of the input channels while keeping the remaining channels unchanged.

The PConv schematic diagram.
Improvement of Long-distance target detection
To address the issue of missing recognition and detection of long-distance targets on roads by onboard cameras, a small target detection layer P2 (as shown in Fig. 1) has been added for long-distance targets. The original input image size of YOLOv8 is 640 × 640 pixels, and its minimum detection scale is 80 × 80 pixels. When an autonomous vehicle detects a road target, the remote target image is small and fuzzy from a two-dimensional perspective. When it is recognized as a small target, its size is small and the sampling coefficient is large. Moreover, small road targets occupy fewer pixels in an image and are easily overlooked or misidentified. By adding a small target-detection layer P2, small targets can be detected on feature maps at different levels, thereby increasing the accuracy and reliability of detection, and reducing missed and false detections.
For small-target detection, an additional 160 × 160 small-target detection layer P2 was added to deepen the feature information extraction of small targets, enabling the model to better learn and capture the detailed features of small targets, thereby improving the detection performance and accuracy of small targets. In complex urban traffic scenes, small traffic signs or pedestrians at a distance can be detected more accurately, providing a more reliable decision-making basis for the auto-drive system.
However, adding the P2 detection layer will inevitably increase the computational complexity of the model, which can be measured by the number of floating-point operations per second (FLOPs). More FLOPs mean a higher demand for computing resources, which may pose challenges during the deployment process, especially on resource-constrained devices such as the in-vehicle computers of autonomous vehicles. The addition of the P2 layer significantly improves the accuracy of the model in detecting small and long-distance targets. This improvement in accuracy is crucial for the safe and reliable operation of the autonomous driving system. With the continuous development of in-vehicle chips, the computing devices used in autonomous vehicles are also constantly being upgraded. The additional load brought by the increase in FLOPs is worthwhile when it can significantly enhance the safety and performance of the autonomous driving system.
Model adaptability and improvement of target image details
To further improve the recognition accuracy of car-mounted cameras for close and long-distance targets, the following improvement methods are proposed:
1) Model adaptability improvement: Owing to the complexity of vehicle image information, the receptive field of the traditional SPPF modules in YOLOv8 is limited and cannot fully utilize global information. In the improved model, the original module (as shown in Fig. 6(a)) is replaced with spatial pyramid pooling with enhanced local attention network(SPPELAN) (as shown in Fig. 6(b)) module to enhance the model’s ability to extract multiscale features and improve its robustness and accuracy. It is mainly composed of GELAN-integrated CSPNet18 and ELAN19 mechanisms, which utilize RepConv’s dedicated single-branch structure for inference while obtaining more effective features, so as not to affect the inference speed. The optional modules and partitions shown in the figure further increase the adaptability and customizability of the network. The structure of GELAN allows it to support multiple types of computing blocks, which enables it to better adapt to various computing requirements and hardware constraints. By combining pooling and convolution operations at multiple different scales, the SPPELAN module can more effectively extract multi-scale features of the input image, thereby better-capturing target information in the image, especially target objects of different sizes, which helps improve the accuracy of object detection.

The SPPF (a) and SPPELAN(b) structure diagram.
2) Improvement of details in the detected image: As an innovative dynamic upsampler, DySample adopts a point sampling method compared with traditional kernel-based dynamic upsamplers. By avoiding time-consuming dynamic convolutions and additional subnetworks to generate dynamic kernels, DySample has fewer parameters, floating-point operations, GPU memory, and latency. This not only improves resource efficiency but also simplifies implementation in PyTorch. Specifically, the right-hand side of Fig. 7 illustrates how to create a sampling set (S) from input features (X) using a sampling point generator and then resample the input features using the grid sample function to obtain upsampled features (X ‘). The left part of the figure depicts in detail two methods for generating sampling points: static range factor (SSF) and dynamic range factor (DSF). Static range factor: by combining linear layers and pixel shuffle techniques with a fixed range factor, an offset (O) is generated, which is then added to the original grid position (G) to obtain a sampling set (S); dynamic range factor: in addition to linear layers and pixel shuffling, a dynamic range factor is introduced that first generates a range factor and then uses it to adjust the offset (O). Here, σ represents the sigmoid function used to generate the range factors.

The SPPF (left) and SPPELAN(right) structure diagram.
3) Improvement of loss function: The original loss function CIoU of the model measures the difference between the predicted and true boxes by considering the center distance and aspect ratio between the two. During the training process, it simultaneously optimizes the position and shape of the box; therefore, when the predicted box converges to the real box, it not only considers the proximity of the center position but also the matching of the aspect ratio. The EIoU is more direct in adjusting the shape of the box, and its measurement of the difference in width and height allows the model to adjust the width and height of the box more accurately during training. Compared with the CIoU, the EIoU is more sensitive to changes in the shape of the box and can quickly correct unreasonable aspects of the predicted box in terms of width and height. When dealing with targets with irregular shapes and large-scale changes, EIoU has a faster convergence speed and can reduce the difference between the predicted and real boxes more quickly. EIoU can also effectively adjust the prediction box when facing noise interference and occlusion situations. To address the issue of false positives caused by overlapping road targets in real-life situations, the loss function was improved to EIOU to enhance the degree of matching between the predicted and real boxes. The formula is:
Where \(\:{\rho\:}^{2}\left(b,{b}^{gt}\right)\) is the square of the distance between the predicted box and the center point of the real box, \(\:{w}^{gt}\) and \(\:{h}^{gt}\) are the width and height of the real box, respectively, and \(\:w\) and \(\:h\) are the width and height of the predicted box, respectively.
Experiment
Experimental environment and equipment, dataset description
The experimental environment of this study is shown in Table 1, and the experimental parameter configuration is shown in Table 2. One of the datasets used is the KITTI20 public dataset, which includes road targets such as cars, pedestrians, and bicycles, with a total of 7481 images. Before experimenting, merge Car, Truck, and Vram in the dataset into Car labels, and Pedestrian and Pedestrian settings into Pedestrian labels, retain the Cyclinst label, and remove other labels. The experiment was conducted at a ratio of 8:1:1 between the training, validation, and test sets, with 6058 images as the training set, 674 images as the validation set, and 749 images as the test set.
The other dataset is the TT100K21 public dataset, jointly released by Tsinghua University and Tencent Co., Ltd. This dataset is used to collect road traffic signs in China. The total category of traffic signs used in this study was reduced to 45, with 9738 images used, including 6793 training sets, 1949 validation sets, and 996 test sets, in a ratio of 7:2:1. The usage process of the two datasets is shown in Fig. 8.

Schematic diagram of YOLOv8-RTDAV training, validation, and testing process.
Valuation indicators
To verify the effectiveness of the improved algorithm, precision (P), recall (R), and mean average precision (mAP) are used as the primary evaluation metrics. The calculation formulas for the precision and recall are as follows:
TP represents the number of correct targets in the object detection results, FP represents the number of incorrect targets in the object detection results, and FN represents the number of missing targets in the object detection results. The formula for calculating the average precision mAP is as follows:
Where \(\:C\) is the total number of categories in the image, \(\:i\:\)is the number of detections, and AP is the average recognition accuracy of a single category.
Comparative experimental results
The comparative experimental results for the KITTI and TT100K datasets are shown in Tables 3 and 4, and the changes in the experimental indicators are shown in Figs. 9 and 10. Compared with the original model, the improved KITTI algorithm outperforms the original model in terms of P-value, R-value, and mAP@50 These indicators perform better. These values increased by 1.3%, 4.2%, and 2.7% respectively, demonstrating the effectiveness of improving detection accuracy. The parameter count and model size were reduced by 6.5% and 3.1% respectively, indicating a certain degree of lightweight. On TT100K, compared with the original model, these indicators increased by 4.2%, 7.8%, and 6.6% respectively, while the number of parameters slightly decreased and the model size remained unchanged. Overall, compared to algorithms such as YOLOv5, all metrics have shown varying degrees of improvement.
From Figs. 11 and 12, it can be seen that the situation of missed detection at close range improved, and the detection and recognition of distant targets have also improved. In the results of the KITTI dataset, due to the overlap between vehicles, the original model did not detect the three vehicles on the left side of the road in Fig. 11(a), while the improved model was able to correctly identify and detect vehicles as well as missed pedestrians. Figure 11(b) shows that vehicles parked on the left side of the road and pedestrians next to trucks on the right side were not detected by the original model. Compared with the original model, the improved model has a higher recognition rate.

Experimental results of YOLOv8-RTDAV on the KITTI dataset with changes in indicators.

Experimental results of YOLOv8-RTDAV on the TT100K dataset with changes in indicators.

Comparison of KITTI experimental results.
The results for the TT100K dataset are shown in Fig. 12, the original model has a lower recognition rate for road traffic signs. As shown in Fig. 12(a), compared with the improved model, the original model did not recognize the left side sign of long-distance parallel traffic signs. In addition, in Fig. 12(b), the long-distance traffic signs are small targets, and the original model did not fully recognize the long-distance signs on the right side, while the improved algorithm correctly detects and recognizes them.
By comparing the heatmaps in Figs. 13 and 14, it is verified that the improved model has higher accuracy in road target recognition than the original model.

Comparison of TT100K experimental results.

Comparison of heat maps between YOLOv8n (up) and YOLOv8-RTDAV (down) on the KITTI dataset.

Comparison of heat maps between YOLOv8n (left) and YOLOv8-RTDAV (right) on the TT100K dataset.
Ablation experiment
To verify the effectiveness of each module in improving the overall algorithm, ablation experiments were conducted using the KITTI dataset. Table 5 shows the specific experimental results, where experiment 1 is the YOLOv8n basic model with a loss function of CIoU, and the loss functions in the remaining experiments are all EIoU. After separately adding the C2f-EFB and P2 small object detection layer, the P-value, R-value, and mAP@50 have different increases, and the number of parameters has decreased to a certain extent, about 9.5% and 2.8% respectively. The feature information of road targets is retained as much as possible in the channel, which improves the recognition ability of close and long-distance targets. After both are added together, the number of parameters further decreases, but the detection accuracy increases slightly. After adding DySample and SPPELAN, the performance of the model reached its optimal level. However, in terms of FPS values, there is an overall downward trend, dropping from 148 to 102. Compared with experiment 1 and experiment 8, YOLOv8-RTDAV increased by approximately 1.3%, 4.2%, and 2.7% in P-value, R-value, and mAP@50 respectively, the number of parameters decreased by approximately 6.5%, and the model size also decreased.
Conclusion
This paper proposes an improved road target detection algorithm YOLOv8-RTDAV, which is based on YOLOv8n, to improve the problem of missed detection and false detection of long-distance and short-range targets in the road by the on-board camera in autonomous vehicles:
-
1)
Design a new C2f structure C2f-EFB to improve the recognition accuracy of the model for close-range overlapping targets.
-
2)
Introduce a small object detection layer P2 to improve the recognition accuracy of the model for distant small objects.
-
3)
By introducing the SPPELAN module and DySample dynamic upsampling module to improve the model’s ability to detect and recognize targets, and replacing the original loss function with EIOU to further improve the model’s detection accuracy.
The improved model was validated on the KITTI and TT100K datasets, with P-values, R-values, and mAP@50 They increased by about 1.3%, 4.2%, 2.7%, and 4.2%, 7.8%, 6.6% respectively, demonstrating the effectiveness of the improvement. In terms of real-time performance, although the frames per second (FPS) dropped from 148 to 102, an FPS of 102 can still meet the real-time processing requirements of the autonomous driving system. Due to the impact of adding a small object detection layer on computational speed and the increase in parameter count, future research will focus on further lightweight, improvement, and parameter reduction of the model to further improve its computational efficiency. Moreover, to account for the model’s performance in different scenarios, especially its detection ability when vehicles encounter targets with extreme occlusions, improvements need to be made in more aspects to enhance its adaptability.
Data availability
The datasets used in this study include the KITTI dataset and the TT100K dataset. The KITTI dataset can be downloaded from its official website: https://www.cvlibs.net/datasets/kitti, while the TT100K dataset can be downloaded from the official website: https://cg.cs.tsinghua.edu.cn/traffic-sign.
References
Redmon, J. & Farhadi, A. YOLOv3: an incremental improvement. arXiv preprint arXiv:180402767. https://arxiv.org/abs/1804.02767 (2018).
Xiaolan, W., Shuo, W. & Jiaqi, C. Data-Driven based Tiny-YOLOv3 method for front vehicle detection inducing SPP-Net. IEEE Access. 8, 110227–110236 (2020).
Huixuan, F. & Guoqing, S. Improved YOLOv4 marine target detection combined with CBAM. Symmetry, 13(4), 623 (2021).
Hao, C. & Zhan, C. Enhanced YOLOv5: an efficient road object detection method. Sensors, 23(20), 8355 (2023).
Hadia, K. S., Muhammad, K. S., Kapil, R. & Puneet, G. Robust page object detection network for heterogeneous document images. International Journal on Document Analysis and Recognition (IJDAR).
Gomaa, A. & Saad, O. M. Residual Channel-attention (RCA) network for remote sensing image scene classification. Multimedia Tools Applications. https://doi.org/10.1007/s11042-024-20546-8 (2025).
Gomaa, A. Advanced Domain Adaptation Technique for Object Detection Leveraging Semi-Automated Dataset Construction and Enhanced YOLOv8. 6th Novel Intelligent and Leading Emerging Sciences Conference (NILES), pp. 211–214. (2024).
Gomaa, A. & Abdalrazik, A. Novel deep learning domain adaptation approach for object detection using Semi-Self Building dataset and modified YOLOv4. World Electr. Veh. J. 15 (6), 255 (2024).
Gomaa, A., Abdelwahab, M. M. & Abo-Zahhad, M. Efficient vehicle detection and tracking strategy in aerial videos by employing morphological operations and feature points motion analysis. Multimedia Tools Appl. 79, 26023–26043 (2020).
Xiuyuan, C., He, H., Junxing, Y., Junxian, Z. & Xin, Z. Dataset and Improved Yolov7 for Text-Based Traffic Sign Detection. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences XLVIII-1/W2-2023, pp. 881–888.
Fatin, Z. M. N. et al. Enhanced small drone detection using optimized YOLOv8 with attention mechanisms. IEEE Access. 12, 90629–90643 (2024).
Salem, M., Gomaa, A. & Tsurusaki, N. Detection of Earthquake-induced Building Damages Using Remote Sensing Data and Deep Learning: A Case Study of Mashiki Town, Japan. IEEE International Geoscience and Remote Sensing Symposium (IGARSS), pp, 2350–2353. (2023).
Long, W. Q. et al. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. in Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 11531–11539., 2020, pp. 11531–11539. (2020).
Ze, L. W., Hao, L., Tao, F. H. & Guo, C. Z. Learning to Upsample by Learning to Sample. in Proc. 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 6004–6014. (2023).
Wang, C.et al. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv preprint arXiv:240213616. https://arxiv.org/abs/2402.13616 (2024).
Fan, Z. Y. et al. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 506, 146–157 (2022).
Run, C. J., Hong, K. S. & Hao, H. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. in Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 12021–12031., 2023, pp. 12021–12031. (2023).
Yao, W. C. et al. CSPNet: A New Backbone that Can Enhance Learning Capability of CNN. in Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW 2020), 2020, pp. 1571–1580., 2020, pp. 1571–1580. (2020).
Dong, Z. X., Hui, Z., Shi, G. & Lei, Z. Efficient Long-Range Attention Network for Image Super-Resolution. in Computer Vision – ECCV 2022, Pt XVII, pp. 649–667 (2022).
Andreas, G., Philip, L. & Raquel, U. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012, pp. 3354–3361 (2012).
Zhe, Z. et al. Traffic-Sign Detection and Classification in the Wild. in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2110–2118 (2016).
Acknowledgements
This research was funded by the National Natural Science Foundation of China (grant number U22A2069) and the Key R&D Special Project of Henan Province (Grant No. 241111242400-03).
Author information
Authors and Affiliations
Contributions
Conceptualization, H.L., and J.G.; methodology, H.L. and J.G.; software, H.L., and Z.L.; validation, H.L., X.J., C.X., and Z.L.; formal analysis, H.L., and J.G.; investigation, X.J., and C.X.; resources, H.L.; data curation, X.J.; writing—original draft preparation, H.L.; writing—review and editing, H.L. and Z.L.; visualization, H.L.; supervision, Y.Z. and C.X.; project administration, H.L.; funding acquisition, Z.L.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Gao, J., Li, H., Li, Z. et al. An algorithm for road target detection of autonomous vehicles based on improved YOLOv8. Sci Rep 15, 21061 (2025). https://doi.org/10.1038/s41598-025-06831-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-06831-y
