
Abstract
In recent years, UAV-based multispectral object detection has demonstrated tremendous potential in smart city traffic management and disaster response capabilities. However, most existing methods focus on better aligning or fusing the two images, while neglecting the blurring of object edges in infrared images under adverse conditions, making it more challenging to distinguish between the foreground and background, thus increasing the difficulty of object detection.To address this issue, we propose a novel cross-modal edge-enhanced detector for UAV-based multispectral object detection.First, we design an Edge Feature Enhancement Module that uses differential convolution to compute the difference between the weighted fusion pooling layer and the input feature map, thereby enhancing edge features in the images.Next, we design a Multi-Scale Feature Fusion Module that employs dilated convolution to expand the receptive field by inserting gaps between kernel elements without increasing the kernel size.This enables the model to detect objects of varying sizes and adapt to resolution changes caused by UAV flight dynamics. Finally, we introduce a Cross-Modal Feature Fusion Module that leverages a self-attention mechanism to learn, adjust, and fuse complementary information from both modalities, enhancing the model, s robustness and improving feature representation across the two spectra.CMEE-Det outperforms existing methods on the DroneVehicle dataset and two other multimodal object detection datasets.
Similar content being viewed by others


Introduction
In recent years, object detection in aerial imagery has attracted widespread attention due to its broad applications in urban traffic management1, environmental monitoring2, and disaster management3, particularly in UAV-based object detection4,5. The complexity of UAV-based object detection lies not only in the dynamic nature of the aerial environment but also in the challenges posed by variations in object scale, resolution, and environmental conditions (e.g., low-light and nighttime scenarios). To improve detection performance in these challenging environments, multispectral imaging (integrating visible and infrared (IR) images) has become a powerful tool that provides complementary information to enhance detection accuracy and robustness.

Example of the edge blurring problem in RGB-IR object detection. The first row shows infrared images, and the second row shows visible light images. In low-light environments, the object edges in infrared images become blurred, making it difficult to distinguish the foreground from the background. In visible light images, target detection is impossible due to insufficient lighting.
The fusion of visible and infrared images presents some challenges. Misalignment between the two modalities due to variations in flight dynamics, sensor characteristics, and environmental factors can significantly hinder effective feature extraction6,7,8. However, DroneVehicle contains misaligned RGB–IR pairs due to UAV motion and sensor differences. To comprehensively evaluate both misalignment robustness and generalization ability, we further test CMEE-Det on two well-aligned multispectral datasets, DVTOD and LLVIP. Furthermore, object representations differ across modalities, such as the lack of color and texture information in infrared images, requiring complex methods to extract and combine complementary features9. Multi-scale object detection is also a challenge10, especially in UAV-based imagery, where varying flight altitudes of the UAV cause objects to appear in different sizes, complicating the detection process. In addition, in harsh environments such as low-light or adverse weather conditions, as shown in Fig. 1, object edges in infrared images may become blurred11, making it difficult to distinguish the foreground from the background. The quality of visible light images sharply decreases at night due to insufficient lighting, further complicating object detection.
Traditional mainstream methods for multispectral object detection can be divided into two categories: pixel-level fusion14,16,17 and feature-level fusion19,20,21,22.These fusion strategies combine multimodal information at different levels, significantly improving object detection accuracy compared to single-modality methods.However, these methods often overlook explicit cross-modal guidance, which allows one modality to extract richer cues, helping the other modality generate more valuable feature representations for multimodal fusion.
Recently, many multimodal remote sensing object detection methods have been proposed12,13. Most efforts have focused on designing complex network architectures to improve detection performance. Ouyang et al.14 proposed a new multimodal feature-guided mask reconstruction pretraining method, M2FP, aimed at addressing the challenges of large-scale multi-scale object detection for multispectral scene perception from a UAV perspective. To enhance UAV object detection under extreme conditions such as low illumination and strong occlusion, Wang et al.12 proposed the Cross-modal Remote Sensing Image Object Detection (CRSIOD) network, which effectively integrates features from different sensors. Their design, including illumination-aware, uncertainty-aware modules, and a three-branch feature enhancement network, significantly improves detection performance in complex environments. Yuan et al. proposed a universal and efficient UniRGB-IR framework, which effectively integrates features from RGB and infrared images by introducing a multimodal feature pool (MFP) and a supplementary feature injector (SFI) module, significantly improving performance in RGB-IR semantic tasks. These methods are often computationally expensive, making them difficult to deploy on resource-limited UAV platforms. To address the issue of computational complexity, other studies focus on designing lightweight networks. Zhang et al.14 proposed a remote sensing image (RSI) object detection method called SuperYOLO, which effectively improves detection accuracy for multi-scale small objects by fusing multimodal data and incorporating auxiliary super-resolution learning. It also optimizes computational cost during the inference phase, achieving an excellent balance between accuracy and speed. However, this fusion method lacks cross-modal interaction and fails to fully leverage the advantages of multimodal features, making it susceptible to modality attacks.
To address these challenges, we propose a novel cross-modal edge-enhanced detector for multispectral object detection in UAVs. To handle variations in object scale and resolution, we first introduce the Multi-Scale Feature Fusion Module (MSFFM), which captures fine-grained details at different levels of the feature hierarchy. This enables the model to detect objects of varying sizes and adapt to changes in object resolution caused by UAV flight dynamics. Specifically, we use dilated convolutions to expand the receptive field by inserting “gaps” between kernel elements, without increasing the kernel size. This approach allows the model to capture features at multiple scales, improving its ability to detect objects of various sizes and providing a more comprehensive scene representation. By incorporating dilated convolutions, the model can effectively perform multi-scale detection, ensuring stable performance in complex and dynamic environments. In multispectral object detection, object boundary information is crucial for distinguishing objects from the background. To this end, we introduce the Edge Feature Enhancement Module (EFEM) in both visible and infrared images, designed to accentuate object contours, particularly in low-contrast or complex background settings, enhancing object distinguishability. Specifically, the core idea of the edge enhancement module is to apply differential convolutions to subtract the weighted fusion pooling layer from the input feature map, thereby enhancing the edge features in the image. Inspired by the success of transformer-based attention mechanisms, we design the Cross-Modal Feature Fusion Module (CMFFM) to facilitate effective interaction between visible and infrared features. By leveraging self-attention mechanisms, the module learns to adjust and fuse complementary information from both modalities, enhancing the model’s robustness and improving feature representations across both spectra. To ensure that both low-level edge details and high-level contextual information are preserved in the final detection representation, the enhanced edge features and global features from both modalities are combined. This enables the model to capture both local fine-grained features and global contextual dependencies, resulting in more accurate object detection performance.
The contributions of this paper are summarized as follows:
-
(1)
We address the issue of weak edge blurring in RGB-IR object detection for aerial images. To the best of our knowledge, this is the first time the problem of edge blurring in RGB-IR aerial image object detection has been proposed and analyzed.
-
(2)
We propose a cross-modal edge-enhanced detector to tackle challenges such as modality misalignment, scale variation, and edge blurring in UAV-based multispectral object detection.
-
(3)
We conducted extensive experiments on UAV-based multispectral datasets, including DroneVehicle, DVTOD, and LLVIP, demonstrating the effectiveness of our method and showing significant improvements in detection performance compared to existing methods.
Related work
Oriented object detection
Due to significant variations in flight altitude, angle, and scene coverage, orientation-based object detection methods are more suitable for UAV-based object detection. Dai et al.15 proposed a new detector, TARDet, a two-stage anchor-free rotated object detector, which generates coarse localization boxes using feature refinement and directed generation modules, and extracts rotation-invariant features through an alignment convolution module. Ding et al.23 proposed a lightweight module, RoI Transformer, which addresses the mismatch between RoIs and objects in aerial images through spatial transformations, significantly improving classification and localization accuracy. Recent work by Taghipour & Ghassemian focused on spatial-spectral fusion for hyperspectral anomaly detection by analyzing spatial patterns, improving feature extraction reliability60. In 2021, they introduced a visual attention-driven framework for hyperspectral anomaly detection, enhancing performance by incorporating spatial-spectral features through attention mechanisms61. Xie et al.24 proposed an efficient and simple orientation-based object detection framework, R-CNN, which resolves the speed bottleneck in existing two-stage detectors. The method generates high-quality oriented proposals in the first stage using an oriented RPN, and refines and recognizes them in the second stage using an oriented R-CNN head. Google25 introduced a novel deep convolutional neural network architecture, Xception, inspired by Inception, which replaces traditional Inception modules with depthwise separable convolutions. In recent years, deep learning-based object detection methods have achieved state-of-the-art performance26,27,28,29. To further advance aerial object detection, Feng et al. introduced the HazyDet dataset. The aforementioned methods have achieved promising results in RGB-based object detection. Although these methods have advanced object detection, they mainly focus on a single modality. Under low-light conditions, RGB-based object detection may struggle to achieve satisfactory results. As a result, researchers are exploring the use of multispectral data to enhance object detection accuracy and robustness30,31,32,33. To address this challenge and ensure high performance, we propose a single-stage two-stream object detector.
Object detection in UAV images
Target detection in UAV images faces unique challenges, primarily due to significant variations in flight altitude, angle, and scene coverage. An effective approach to addressing these complexities is multi-scale feature fusion, which is crucial for handling targets of varying sizes. CFANet, proposed by Zhang et al.34, effectively addresses the challenge of detecting dense small objects in UAV images by using the Cross-Layer Feature Aggregation (CFA) module, Layered Association Spatial Pyramid Pooling (LASPP) module, and Adaptive Overlapping Slice (AOS) method, showing significant performance improvements across multiple datasets. Zhang et al.35 proposed SODNet, which uses an adaptive spatial parallel convolution module to improve real-time detection of small objects through specialized feature extraction and information fusion techniques. Zhang et al.36 introduced FANet, an arbitrary orientation remote sensing target detection method based on feature fusion and angle classification. By adopting angle prediction branches and Circular Smoothing Label (CSL) methods, angle regression is transformed into a classification problem, resolving the issue of abrupt changes in rotated frame boundaries. To tackle the challenges of large scale variations and dense small objects, Zhang et al.37 proposed SGMFNet, a UAV image object detection network that combines self-attention guidance and multi-scale feature fusion. This method effectively combines multi-scale features and enhances small object feature extraction by designing the Global-Local Feature Guidance (GLFG) module and the improved Parallel Sampling Feature Fusion (PSFF) module, thereby improving detection accuracy. Li et al.38 introduced a novel Perceptual Generative Adversarial Network (Perceptual GAN) model to enhance small object detection. The model improves the detection of small objects by transforming their low-quality representations into super-resolution representations, narrowing the gap between small and large object representations. However, these methods are all single-modality detection approaches, overlooking the complementary information between different modalities. An et al.39 proposed ECISNet, which enhances the feature extraction ability of multimodal data through the Cross-Modal Information Sharing (CIS) module and Modal Effectiveness Guidance (MEG) module, ensuring accurate detection even when one modality fails. Sun et al.20 developed UA-CMDet, a UAV-based cross-modal vehicle detection framework, which introduces an uncertainty perception module to quantify the uncertainty of each object and improves detection performance in low-light and complex environments through cross-modal information fusion. However, traditional multimodal image fusion methods usually focus on pixel-level feature fusion, overlooking the precise handling of edge information. To address this issue, our approach not only fully utilizes the complementary information between modalities but also considers edge blurring and multi-scale feature fusion in multispectral data, effectively enhancing object detection performance.

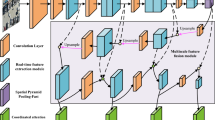
Cross-modal edge-enhanced detector. We propose a dual-stream feature extractor with cross-modal edge enhancement to extract modality-specific features. After obtaining modality-specific regional features, the MSFFM module captures multi-scale features, which are then merged by the CMFFM module to combine image feature pairs for class and bounding box prediction.
Method
Architecture
Based on a comprehensive analysis of the challenges and difficulties in UAV-based cross-modal object detection, we propose a cross-modal edge enhancement detector to address issues such as modality misalignment, scale variations, and edge blurring in multispectral object detection. The overall architecture, as shown in Fig. 2, consists of three main components: the Edge Feature Enhancement Module (EFEM), Multi-Scale Feature Fusion Module (MSFFM), and Cross-Modal Feature Fusion Module (CMFFM). First, the extracted features are fed into the EFEM, where a smoothing layer (DSConv3 × 3) is used to reduce noise and extract stable edge information. Next, average pooling, max pooling, differential convolution, and learned weight coefficients are combined to enhance the edge features. The edge-enhanced feature map is then passed to the MSFFM, which effectively captures information at different scales through adaptive pooling and dilated convolution. This is crucial for multimodal image fusion, especially when images have different resolutions or scales, as it ensures the model remains efficient and precise when handling objects of various sizes. The features are then sent to the CMFFM, where a cross-attention mechanism computes the correlation between queries and keys to effectively weight and fuse features from different modalities, ensuring that useful information from each modality is reinforced. Detailed information about each part will be presented in the following subsections.

The structure of the Edge Feature Enhancement Module.
Edge feature enhancement module
Edge blurring is a common issue in multimodal object detection, particularly when dealing with visible light and infrared images. Due to the low contrast of infrared images and the loss of details in visible light images, the edge regions often appear unclear, leading to blurred edge information of the objects. This edge blurring issue directly affects object localization and classification, particularly in complex backgrounds or low-light conditions, where edge clarity is crucial. To effectively address this problem, we propose an edge enhancement mechanism that enhances the edge features in the image to improve object recognizability. The details are illustrated in Fig. 3.
First, the input visible light image \({X_{RGB}}\) and infrared image \({X_{IR}}\) are processed through depthwise separable convolution to achieve feature smoothing. This operation effectively removes low-frequency noise while preserving the primary structural information of the image.
Here, \(DSConv3 \times 3\) represents a 3 × 3 depthwise separable convolution operation, which performs convolution on each channel for more efficient computation.
We then use average pooling and max pooling operations to extract features at different scales. To combine the advantages of these two pooling methods, we adopted the concept of hybrid pooling18 and proposed an adaptive weighted pooling mechanism. Specifically, we adaptively adjust the weight of average pooling and max pooling to more flexibly extract global and local features from the image.
In the formula, \({X^{\prime}_{RGB}}\) and \({X^{\prime}_{IR}}\) represent the processed feature maps of the visible light and infrared images,\({F^{\prime}_{RGB}},{F^{\prime}_{IR}} \in {R^{W \times H \times C}}\), respectively. \(\lambda {}_{{_{{rgb}}}}\) and \({\lambda _{ir}}\) represent the weights between 0 and 1, \({\lambda _{RGB}},{\lambda _{IR}} \in R\), which are learnable parameters. \(new\_rgb\) and \(new\_ir\) denote the visible-light and infrared feature maps obtained through hybrid pooling, respectively. Then, the fused features \(new\_rgb\) and \(new\_ir\) are processed by differential convolution to compute the difference between the hybrid pooling-weighted features and the initial input features, resulting in enhanced edge feature images:
\(Conv{}_{{diff}}\) is the differential convolution, The differential convolution is implemented using a 3 × 3 kernel, stride 1, and padding 1, with a dilation rate r = 1 (default non-dilated convolution) to extract localized edge details, and \(edg{e_{RGB}}\) and \(edg{e_{IR}}\) are the edge-enhanced feature maps of the visible light and infrared images, respectively.
\(Conv\) is the 1 × 1 convolution layer, \(BN\) represents BatchNorm, \(\sigma\) represents the Sigmoid function, and \(weigh{t_{RGB}}\) and \(weigh{t_{IR}}\) are the generated weights for the visible light and infrared images, respectively.
\(ou{t_{RGB}}\) and \(ou{t_{IR}}\) are the feature maps of the visible light and infrared images after edge enhancement through weighting.

The structure of the Multi-Scale Feature Fusion Module.
Multi-Scale feature fusion module
In multimodal fusion tasks, due to significant differences in resolution, scale, and feature distribution between visible light and infrared images, direct pixel-level or simple feature-level fusion often struggles to capture complementary information from both modalities, leading to degraded fusion performance.To address this issue, we propose a Multi-Scale Feature Fusion Module. The module utilizes techniques such as depthwise separable convolution, pooling, and dilated convolution to process and enhance the input multi-channel image data, extracting useful spatial and contextual information. For clarity, we only show the MSFFM module for the visible light image. The detailed structure is shown in Fig. 4.
First, the weighted edge-enhanced visible light feature map \(ou{t_{RGB}}\) is processed using adaptive average pooling, generating dynamic convolution kernel templates from each feature map for the subsequent multi-scale dynamic convolution operation, as shown in the following formula:
\(Pool\) is the adaptive average pooling layer, which resizes the input image to a fixed 5 × 5 output size to extract multi-scale global features. \(ou{t^{\prime}_{RGB}} \in {R^{B \times C \times 5 \times 5}}\) represents the convolutional kernel generated by the pooling operation with a fixed size. Then, for each batch of \(i \in \{ 1,2,...,B\}\), dynamic dilated convolution is applied to the corresponding feature map \(ou{t_{RGB}}\left[ i \right]\) using the generated dynamic convolution kernel \(ou{t^{\prime}_{RGB}}\left[ i \right] \in {R^{B \times C \times 5 \times 5}}\). The dynamic convolution operation formula is as follows:
\(Con{v_{dil=d}}()\) represents dilated convolution, we use fixed dilation rates \(r \in \left\{ {1,2,4} \right\}\) across the three parallel branches of the MSFFM to capture multi-scale context without increasing parameter count. By combining the results of different dilated convolutions, the module can capture contextual information at multiple scales, thus enhancing feature extraction capability.
\(out_{{RGB}}^{d}\) represents the output of the d-th dilated convolution, and D is the total number of dilation rates. The summation operation enhances the ability to capture target structures and contextual information by integrating feature information from different receptive fields. Then, a pointwise convolution is applied to the enhanced feature map \(out_{{RGB}}^{{new}}\), aiming to perform a linear combination and transformation of the channel dimension to enhance feature interaction between channels while compressing redundant information. Its mathematical expression is:
\({F_{RGB}}\) is the output feature map after the pointwise convolution, \({W^{1 \times 1}}\) is the 1 × 1 convolution kernel corresponding to the input feature map, and ∗ denotes the pointwise convolution operation. The pointwise convolution works by performing a weighted sum of all channels at each pixel using the 1 × 1 convolution kernel.
Then, the feature map \({F_{RGB}}\) is further processed through depthwise separable convolution to extract local spatial information, utilizing the decomposed convolution operation to achieve efficient computation and fine-grained feature extraction. The specific formula is:
Here, c denotes the channel index, and \({W^{3 \times 3}}[c]\) represents the 3 × 3 convolution kernel for the corresponding channel. Similarly, the infrared image’s feature map \(F_{{IR}}^{{depth}}\) can also be obtained. The final output feature maps, \(F_{{RGB}}^{{depth}}\) and \(F_{{IR}}^{{depth}}\), are the results of multi-scale feature fusion. They retain the original resolution and structure of the input feature maps while enhancing the correlation between features at different resolutions.
Cross-modal feature fusion module
In multimodal fusion tasks, semantic inconsistencies may exist between features from different modalities. Direct stacking or simple fusion often leads to interference between modalities, thereby impairing the representational capacity of the fused features. To address this issue, we propose a Cross-Modal Feature Fusion Module, as shown in Fig. 5, which enhances the synergy between features of different modalities through cross-modal feature interaction and channel embedding operations, generating more expressive fused features.
First, the channels of \(F_{{RGB}}^{{depth}}\) and \(F_{{IR}}^{{depth}}\) are reduced through linear mapping to generate intermediate representations:
Here, \({W_{RGB}} \in {R^{C \times (C/r \times 2)}}\) and \({W_{IR}} \in {R^{C \times (C/r \times 2)}}\) represent the dimensionality reduction weight matrices, \({b_{RGB}}\) and \({b_{IR}}\) are the biases, r denotes the reduction rate, \(\sigma\) represents the ReLU activation function, \(Chunk\) splits the tensor into two parts along the last dimension: X7 and X8. Then, a multi-head cross-attention mechanism is used to enhance the complementarity of the two modality features:
Here, \({{\rm T}_{RGB}}\) and \({{\rm T}_{IR}}\) represent the features after cross-modal interaction. The calculation process is as follows: we first generate query, key, and value descriptors from the input features. Specifically, we use convolutional layers for each modality to generate the descriptors and reshape them into 2D tensors. The generation process is defined as follows:
Where \({W^Q},{W^K} \in {R^{N \times {D_K}}}\) and \({W^V} \in {R^{N \times {D_V}}}\) are the convolution with kernel size 1 × 1 associated with query, key and value, respectively. We use \({H_{heads}}=8\) attention heads for parallel computation. \(Q \in {R^{HW \times C}},K \in {R^{HW \times C}}\) and \(V \in {R^{HW \times C}}\) are the final feature descriptors after a reshape operation \(\Gamma ( \cdot )\). Then, the cross-modal attention weights are calculated:
Here, \({{\rm T}_{RGB}}\) and \({{\rm T}_{IR}}\) represent the features of the visible light and infrared images after cross-modal interaction. The attention mechanism uses temperature scaling \(\sqrt[{}]{{{D_k}}}\) in the softmax operation. Then, the results of the cross-attention computation are concatenated with the initial features \(Y{}_{{RGB}}\) and \({Y_{IR}}\), followed by dimensionality reduction and linear reconstruction to generate new features.
Here, \(W \in {R^{(C/r \times 2) \times C}}\). Then, the final interaction features are generated through residual connections.
Then, the features of the two modalities are concatenated along the channel dimension.
Then, the channel embedding module enhances the feature interaction between channels and spatial dimensions through a series of convolution operations.
Here, \({X_{res}}=Conv2D({\hat {{\rm T}}_{RGB}})\) represents the residual branch, \(DWConv\) is a 3 × 3 depthwise separable convolution, \(\sigma\) represents the ReLU activation function, and \({\hat {{\rm T}}_{out}}\) is the final output feature.

The structure of the Cross-Modal Feature Fusion Module.
Loss function
This study employs a multi-task joint loss function consistent with the original YOLOv5 and FCOS frameworks, directly inheriting their effectiveness in single-modality object detection tasks.The overall loss function is formulated as follows:
The classification loss (\({L_{cls}}\)) combines Binary Cross-Entropy (BCE) Loss and Focal Loss, serving distinct objectives: BCE Loss for object existence prediction and Focal Loss for category classification, thereby effectively addressing class imbalance issues.The regression loss (\({L_{reg}}\)) employs CIoU Loss for optimizing boundary box coordinate regression, enhancing dense small-object localization accuracy.Where \({\lambda _1}\)= 0.05 is determined through validation set tuning.
Experiments
Experimental settings
Datasets
Our experiments were conducted on the DroneVehicle RGB-IR vehicle detection dataset20. DroneVehicle is a large-scale drone-based dataset with well-aligned visible/infrared pairs from day to night.Next, we will demonstrate the generalization capability of this network architecture on the multispectral datasets DVTOD6 and LLVIP59.
-
(1)
DroneVehicle: The DroneVehicle dataset is a large-scale paired dataset of infrared and visible images captured from drones, containing 953,087 vehicle instances across 56,878 images. This dataset covers a variety of scenes, including urban roads, residential areas, parking lots, and scenes ranging from daytime to nighttime. Additionally, the authors have provided rich annotations with oriented bounding boxes for five categories: sedan, bus, truck, van, and freight vehicle. The dataset is divided into a training set and a test set, and our experimental results are inferred from the test set.
-
(2)
DVTOD: The DVTOD dataset is a large-scale paired dataset of infrared and visible images collected from drones, containing 16 challenging attributes and 54 captured scenes. It includes 1,606 pairs for training and 573 pairs for testing. To ensure uniformity in scene, category, and attribute distributions, the training and test sets are divided based on scenes, while maintaining uniform category and attribute distributions.
-
(3)
LLVIP: The LLVIP dataset is a low-light image collection dataset, containing a total of 15,488 pairs of images, with 12,025 pairs used for training and the remaining 3,463 pairs used for testing. These images were collected by a monitoring system at 26 different locations and aligned through manual filtering. Unlike the DroneVehicle dataset, it is a well-aligned dataset.
Evaluation indicators
-
(4)
For these three public datasets, we evaluated them using the most common evaluation metric in object detection, mean Average Precision (mAP@[0.5:0.95]), which is further divided into mAP@50, mAP@75, and mAP@[0.5:0.95]. The mAP@50 metric represents the average of all AP values for all categories at IoU = 0.50. Similarly, the mAP@75 metric represents the average of all AP values for all categories at IoU = 0.75. The mAP@[0.5:0.95] metric represents the average AP across the range of IoU from 0.50 to 0.95, with a step size of 0.05. The higher the value of this metric, the better the performance of our method on the corresponding dataset.
Realization details
Our method is implemented using PyTorch 1.10.1 framework on a Linux server with seven NVIDIA GeForce GTX 1080 Ti GPUs. The training phase takes 300 epochs with the batch size of 49. The SGD optimizer is used with the initial learning rate of 1.0 × 10 − 2.The loss function is utilized following the detectors of YOLOv5 and FCOS in the orignal paper. In the ablation studies, We use the extended YOLOv5 framework as the default baseline for comparison. The DroneVehicle dataset provides annotations in the form of Horizontal Bounding Boxes (HBB). The RGB and IR image pairs in the dataset are inherently co-registered (aligned). Before being input to the network, both the visible-light and infrared streams are resized to a fixed input resolution of 640 × 640 using standard bilinear interpolation, maintaining the original aspect ratio by padding where necessary.
Comparisons
To ensure fair comparisons, all comparison methods in this study—including models originally designed for oriented object bounding box (OBB) detection, such as RoI Transformer and Oriented R-CNN—were uniformly trained and evaluated using the standard horizontal bounding box (HBB) annotations provided by the DroneVehicle dataset. We compared our method with competitive methods on the DroneVehicle test set (as shown in Table 1). Due to the lack of cross-modal oriented detection methods for aerial scenes in existing studies, we evaluated our method and eight other state-of-the-art methods, five of which are single-modal methods and three are multi-modal methods. Among the multi-modal methods, CALNet achieves the highest detection accuracy (75.39% mAP@0.5). In contrast, our proposed detector achieved 77.63% mAP@0.5, outperforming other methods and improving 2.24% mAP@0.5 compared to the state-of-the-art methods. Furthermore, our method outperforms existing methods across most categories in the UAV dataset. Specifically, our method improves the accuracy of detecting cars, trucks, buses, and vans by 6.61%, 3.34%, 7.08%, and 7.97% mAP@0.5, respectively, further demonstrating its effectiveness in alleviating edge blurring issues.
As shown in Table 2, we evaluated our method against 11 other advanced methods, including 6 multi-modal methods. The performance of the method using both RGB and infrared images outperforms single-modal methods. Among the multi-modal methods, CALNet has a higher detection accuracy (76.41% mAP@0.5). In contrast, our method performs better, achieving 77.65% mAP@0.5, outperforming other methods and improving 1.24% mAP@0.5 compared to the state-of-the-art methods.
For the DVTOD dataset, we compared CMEE-Det with 8 methods: 5 single-modal algorithms (YOLOv3, YOLOv5, YOLOv6, YOLOv7, YOLOv8) and 3 multi-modal algorithms (YOLOv5 + Add, CMX, CFT). The results are shown in Table 3. Existing advanced fusion detection methods are 5.2%, 2.8%, and 1.7% lower than CMEE-Det, respectively. The edge blur of multi-modal images leads to reduced detection accuracy and difficulty in convergence for multi-modal detectors. In terms of detection accuracy for visible light images, the detection accuracy for the visible modality is low due to lighting conditions, complex backgrounds, and occlusions. Moreover, the dataset contains a large number of low-light image pairs, which also leads to lower detection accuracy for visible images. These results also demonstrate the effectiveness of our detection method.
LLVIP is an aligned dataset collected under low-light conditions. We compared our proposed CMEE-Det with five multi-spectral object detection methods and five single-modal object detection methods (as shown in Table 4). Our CMEE-Det achieved good detection performance on this dataset, obtaining the best results among all the compared methods. These results demonstrate that CMEE-Det not only handles misaligned UAV data, but also maintains strong performance on well-aligned multispectral datasets, confirming the generalizability and robustness of the proposed framework.
Qualitative analysis

The first column shows the daytime scene, and the fourth column shows the nighttime scene. The first and third rows represent visible light images, and the second and fourth rows represent infrared images. The second and fifth columns show the baseline method visualization, while the third and sixth columns show the visualization of our method.
The improved attention responses observed in Fig. 6 can be attributed to the complementary roles of EFEM and CMFFM. EFEM enhances the separation between foreground object boundaries and the surrounding background by sharpening cross-modal edge cues, which reduces ambiguity in regions where IR edges are typically blurred. This clearer structural guidance allows the CMFFM cross-attention mechanism to assign higher attention weights to true object regions instead of noise or blurred contours. As a result, the fused feature maps display more coherent activation patterns and stronger focus on semantically meaningful areas, explaining the more comprehensive region coverage shown in our qualitative examples. As shown in the second and fifth columns of the figure, the baseline method has limited coverage of different regions in the input image. In contrast, the third and sixth columns show that our method can leverage global spatial location information and the correlations between different objects to more comprehensively capture all object features. CMEE-Det effectively fuses cross-modal features, not only accelerating the integration of background information but also significantly enhancing the saliency of object features at multiple levels.
Figure 7 shows the visualization of CMEE-Det on drones in the DroneVehicle dataset, accurately classifying and locating objects under dense small objects and low-light conditions. The experimental results at Figure (a) mAP@0.5 and Figure (b) mAP@[0.5:0.95] rates for different data sets are shown in Fig. 8.

Visualization results of CMEE-Det on UAVs in the DroneVehicle dataset, with different colored boxes for different categories. It performs excellently in tasks such as small object localization, dense object localization, and fine-grained classification under various lighting conditions.

Training process of mAP@50 and mAP@[0.5:0.95] different dataset.
Figure 9 shows the Figure (a) mAP@50 and Figure (b) mAP@[0.5:0.95] results for our detector and baseline detector for specific categories in the DroneVehicle dataset. In contrast, our CMEE-Det employs a more effective fusion strategy that greatly improves accuracy, especially in detecting trucks and vans.

Different categories of mAP@50 and mAP@[0.5:0.95] results for our detector with baseline on the DroneVehicle dataset.
Ablation study
Ablation on each component
We adopt the extended YOLOv5 as our primary baseline because it is a strong and widely recognized single-stage detector, whose stable architecture and mature training pipeline make it easier to isolate and quantify the incremental effects of our proposed modules (EFEM, MSFFM, CMFFM). Although our loss design is compatible with both YOLOv5 and FCOS, YOLOv5 provides a cleaner and more consistent foundation for controlled ablation, enabling more reliable analysis of component-wise contributions.
Effect of EFEM Module.We extended Yolov5 as our baseline. First, we performed an ablation study on the EFEM module while keeping the rest of the network structure unchanged. Compared to the data in row 2 of Table 5, mAP@50 increased by 2.02% in row 5. The experimental results indicate that the module effectively enhanced the edge information representation of visible and infrared images during the feature extraction phase, while also precisely capturing the edge differences between cross-modal features through differential convolution and edge enhancement operations. This not only improved the accuracy of cross-modal feature alignment but also further optimized the robustness and consistency of modal fusion.
Effect of MSFFM Module. In row 3 of Table 5, we performed an ablation of the MSFFM module, keeping the rest of the network unchanged. The mAP@[0.5:0.95] increased by 2.17% in row 5 compared to row 3. Experimental results show that the module effectively extracts details and semantic features of visible light and infrared images at different scales. The module extracts rich contextual information at different receptive fields through adaptive pooling and dilated convolution, while accurately capturing spatial details through feature reconstruction. This method effectively enhances the complementarity of cross-modal features and improves the ability to capture target features in complex scenes, thereby significantly improving the expressive power of fused features and the robustness of detection performance.
Effect of CMFFM Module. As shown in row 4 of Table 5, we performed an ablation of the CMFFM module, while keeping the rest of the network unchanged during both training and testing. Comparing row 5 with row 4 in Table 5, we observe that the addition of CMFFM increased mAP@50 by 2.34%. Experimental results show that the module effectively captures the correlation between different modalities and promotes efficient cross-modal feature interaction. Moreover, the channel embedding operation further optimizes the expression of fused features and enhances the modeling of spatial consistency in the input features. Overall, this module significantly enhances the compatibility and information representation ability of cross-modal features, providing high-quality fused feature support for downstream detection tasks.
The experimental results in Table 5 show that any combination of two modules significantly improves detection performance, with a clear improvement over the baseline results. This indicates that the modules complement each other in capturing multimodal features, enhancing feature representation, and integrating contextual information, positively impacting the final detection task. Furthermore, when EFEM, MSFFM, and CMFFM modules are combined, detection performance is further improved. This result validates the advantage of the three modules working together, as their fusion through multiple mechanisms not only enhances feature distinguishability but also better adapts to the target detection needs in complex scenarios.
Analysis of the effectiveness of improvement methods
Table 6 provides a detailed comparison of performance indicators for different object detection model configurations. The analysis results show that the CMEE-Det model proposed in this paper achieves the best comprehensive performance, especially when using CSPDarknet53 as the backbone network. This configuration achieves the highest accuracy of 84.4% mAP@50 and inference speed of 70 FPS with a parameter count of 115.5 M and a computational load of 205.08 GFLOPs. This is not only significantly better than the baseline method YOLOv5 + Add (5.2% accuracy improvement), but also better than other high-performance models such as CFT and YOLOv5 + CMX. At the same time, compared with the performance of CMEE-Det using different backbone networks, CSPDarknet53 version demonstrates better balance in speed, accuracy, and resource consumption, which strongly proves the efficiency and superiority of CMEE-Det architecture design.
Hyperparameter sensitivity analysis
The initial learning rate (LR) is a critical hyperparameter governing the convergence of the model. We evaluated the sensitivity of CMEE-Det by testing four different initial LRs on theDVTOD dataset, and the mAP@50 results are illustrated in Table 7. The default LR of 1.0 × 10− 2 yields the optimal result, providing the best balance between convergence speed and final detection accuracy.
We evaluated the effectiveness of the Adaptive Weighting Mechanism in the EFEM framework, as detailed in Table 8. The baseline model (without EFEM) achieved a mAP@50 of 82.6%, while the EFEM with fixed average fusion improved the result to 83.2%. By introducing learnable parameters for \(\lambda {}_{{_{{rgb}}}}\) and \(\lambda {}_{{ir}}\), the adaptive weighting mechanism further boosted the performance to 84.4%, confirming its ability to optimally fuse multi-modal features.
Conclusions
In this paper, we analyze the impact of edge blurring on multimodal object detection and then propose CMEE-Det, a novel cross-modal edge enhancement detector for multispectral object detection in UAVs. UAV detection tasks, several limitations remain. First, the model is optimized for visible–infrared fusion in aerial scenarios, and its performance under extreme environments (e.g., heavy fog, nighttime glare, severe sensor noise) may still degrade, as such cases are underrepresented in existing datasets. The adaptive pooling and cross-modal enhancement modules introduce additional computational overhead compared to single-modality detectors, which may limit deployment on extremely resource-constrained onboard processors. CMEE-Det is currently evaluated mainly on vehicle and person detection tasks; its generalization to other multispectral tasks (e.g., semantic segmentation, medical imaging, agriculture monitoring) remains a promising direction for future research. To address these limitations, future work will explore lightweight modules for real-time onboard inference, investigate robust training strategies for extreme illumination and weather conditions, and extend CMEE-Det to broader multimodal perception tasks. Beyond UAV-based multispectral detection, the principles behind CMEE-Det—namely edge-aware representation enhancement and robust cross-modal feature interaction—hold strong potential for broader multimodal perception tasks, such as autonomous driving, robotics, and remote sensing, where reliable fusion of heterogeneous sensors is essential.
Data availability
The datasets used during this study are publicly available in the [DroneVehicle], [DVTOD], and [LLVIP] repositories at [https://github.com/VisDrone/DroneVehicle], [https://github.com/VDT-2048/DVTOD], and [https://bupt-ai-cz.github.io/LLVIP/].
References
de Carvalho, O. L. F. et al. Bounding box-free instance segmentation using semi-supervised iterative learning for vehicle detection[J]. IEEE J. Sel. Top. Appl. Earth Observations Remote Sens. 15, 3403–3420 (2022).
Xie, X., Li, B. & Wei, X. Ship detection in multispectral satellite images under complex environment[J]. Remote Sens. 12 (5), 792 (2020).
Wang, Y. et al. Real-time damaged Building region detection based on improved YOLOv5s and embedded system from UAV images[J]. IEEE J. Sel. Top. Appl. Earth Observations Remote Sens. 16, 4205–4217 (2023).
Wang, S. et al. Mask-Guided Mamba Fusion for Drone-based Visible-Infrared Vehicle Detection[J] (IEEE Transactions on Geoscience and Remote Sensing, 2024).
Liu, Y. & Jiang, W. Frequency Mining and Complementary Fusion Network for RGB-Infrared Object Detection[J] (IEEE Geoscience and Remote Sensing Letters, 2024).
Song, K. et al. Misaligned Visible-Thermal Object Detection: A Drone-based Benchmark and Baseline[J] (IEEE Transactions on Intelligent Vehicles, 2024).
Yuan, M., Wang, Y. & Wei, X. Translation, scale and rotation: cross-modal alignment meets RGB-infrared vehicle detection[C]//European Conference on Computer Vision. Cham: Springer Nature Switzerland, : 509–525. (2022).
Yuan, M. & Wei, X. C 2 Former: Calibrated and Complementary Transformer for RGB-Infrared Object Detection[J] (IEEE Transactions on Geoscience and Remote Sensing, 2024).
Shen, J. et al. ICAFusion: iterative cross-attention guided feature fusion for multispectral object detection[J]. Pattern Recogn. 145, 109913 (2024).
Ma, W. et al. Mdfn: Multi-scale deep feature learning network for object detection[J]. Pattern Recogn. 100, 107149 (2020).
Jiang, K. et al. Edge-enhanced GAN for remote sensing image superresolution[J]. IEEE Trans. Geosci. Remote Sens. 57 (8), 5799–5812 (2019).
Wang, H. et al. Cross-Modal oriented object detection of UAV aerial images based on image Feature[J]. IEEE Trans. Geosci. Remote Sens. 62, 1–21 (2024).
Sun, X., Yu, Y. & Cheng, Q. Low-rank Multimodal Remote Sensing Object Detection with Frequency Filtering Experts[J] (IEEE Transactions on Geoscience and Remote Sensing, 2024).
Zhang, J. et al. SuperYOLO: super resolution assisted object detection in multimodal remote sensing imagery[J]. IEEE Trans. Geosci. Remote Sens. 61, 1–15 (2023).
Dai, L. et al. TARDet: two-stage anchor-free rotating object detector in aerial images[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. : 4267–4275. (2022).
Sun, Y. et al. Detfusion: A detection-driven infrared and visible image fusion network[C]//Proceedings of the 30th ACM international conference on multimedia. : 4003–4011. (2022).
Cao, B. et al. Multi-modal gated mixture of local-to-global experts for dynamic image fusion[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. : 23555–23564. (2023).
Qingyun, F., Dapeng, H. & Zhaokui, W. Cross-modality fusion transformer for multispectral object detection[J]. (2021). arXiv preprint arXiv:2111.00273.
Wu, X. et al. Multimodal Collaboration Networks for Geospatial Vehicle Detection in Dense, Occluded, and Large-Scale Events[J] (IEEE Transactions on Geoscience and Remote Sensing, 2024).
Sun, Y. et al. Drone-based RGB-infrared cross-modality vehicle detection via uncertainty-aware learning[J]. IEEE Trans. Circuits Syst. Video Technol. 32 (10), 6700–6713 (2022).
Kang, X., Yin, H. & Duan, P. Global–Local feature fusion network for Visible–Infrared vehicle Detection[J]. IEEE Geosci. Remote Sens. Lett. 21, 1–5 (2024).
Chen, Y. T. et al. Multimodal object detection via probabilistic ensembling[C]//European Conference on Computer Vision. Cham: Springer Nature Switzerland, : 139–158. (2022).
Ding, J. et al. Learning RoI transformer for oriented object detection in aerial images[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. : 2849–2858. (2019).
Xie, X. et al. Oriented R-CNN for object detection[C]//Proceedings of the IEEE/CVF international conference on computer vision. : 3520–3529. (2021).
Chollet, F. & Xception Deep learning with depthwise separable convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. : 1251–1258. (2017).
Cheng, G. et al. Anchor-free oriented proposal generator for object detection[J]. IEEE Trans. Geosci. Remote Sens. 60, 1–11 (2022).
Doloriel, C. T. C. & Cajote, R. D. Improving the detection of small oriented objects in aerial images[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. : 176–185. (2023).
Han, J. et al. Align deep features for oriented object detection[J]. IEEE Trans. Geosci. Remote Sens. 60, 1–11 (2021).
Zhang, C. et al. Task-collaborated detector for oriented objects in remote sensing images[J]. IEEE Trans. Geosci. Remote Sens. 61, 1–14 (2023).
Liu, Z. et al. SwinNet: Swin transformer drives edge-aware RGB-D and RGB-T salient object detection[J]. IEEE Trans. Circuits Syst. Video Technol. 32 (7), 4486–4497 (2021).
Zhang, Q. et al. RGB-T salient object detection via fusing multi-level CNN features[J]. IEEE Trans. Image Process. 29, 3321–3335 (2019).
Zhang, Q. et al. Revisiting feature fusion for RGB-T salient object detection[J]. IEEE Trans. Circuits Syst. Video Technol. 31 (5), 1804–1818 (2020).
Zhou, T. et al. RGB-D salient object detection: A survey[J]. Comput. Visual Media. 7, 37–69 (2021).
Zhang, Y. et al. CFANet: efficient detection of UAV image based on cross-layer feature aggregation[J]. IEEE Trans. Geosci. Remote Sens. 61, 1–11 (2023).
Zhang, X. et al. SODNet: small object detection using deconvolutional neural network[J]. IET Image Proc. 14 (8), 1662–1669 (2020).
Zhang, Y. et al. FANet: an arbitrary direction remote sensing object detection network based on feature fusion and angle classification[J]. IEEE Trans. Geosci. Remote Sens. 61, 1–11 (2023).
Zhang, Y. et al. Self-attention guidance and multiscale feature fusion-based UAV image object detection[J]. IEEE Geosci. Remote Sens. Lett. 20, 1–5 (2023).
Li, J. et al. Perceptual generative adversarial networks for small object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. : 1222–1230. (2017).
An, Z., Liu, C. & Han, Y. Effectiveness guided cross-modal information sharing for aligned RGB-T object detection[J]. IEEE. Signal. Process. Lett. 29, 2562–2566 (2022).
Lin, T. Focal Loss for Dense Object Detection[J]. arXiv preprint arXiv:1708.02002, (2017).
Ren, S. et al. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems (NIPS 2015), 28 (2015).
Han, J. et al. Redet: A rotation-equivariant detector for aerial object detection[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. : 2786–2795. (2021).
Xu, Y. et al. Gliding vertex on the horizontal bounding box for multi-oriented object detection[J]. IEEE Trans. Pattern Anal. Mach. Intell. 43 (4), 1452–1459 (2020).
He, X. et al. Multispectral Object Detection via Cross-Modal Conflict-Aware Learning[C]//Proceedings of the 31st ACM International Conference on Multimedia. : 1465–1474. (2023).
Liu, J. et al. Multispectral deep neural networks for pedestrian detection[J]. arXiv preprint arXiv:1611.02644 (2016).
Zhang, L. et al. Cross-modality interactive attention network for multispectral pedestrian detection[J]. Inform. Fusion. 50, 20–29 (2019).
Zhang, L. et al. Weakly Aligned Feature Fusion for Multimodal Object detection[J] (IEEE Transactions on Neural Networks and Learning Systems, 2021).
Redmon, J. Yolov3: An incremental improvement[J]. arXiv preprint arXiv:1804.02767, (2018).
Jocher, G. et al. ultralytics/yolov5: v3. 1-bug fixes and performance improvements[J]. Zenodo, (2020).
Li, C. et al. YOLOv6: A single-stage object detection framework for industrial applications[J]. (2022). arXiv preprint arXiv:2209.02976.
Wang, C. Y., Bochkovskiy, A. & Liao, H. Y. M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. : 7464–7475. (2023).
Zhang, J. et al. CMX: Cross-modal Fusion for RGB-X Semantic Segmentation with transformers[J] (IEEE Transactions on intelligent transportation systems, 2023).
Liu, W. et al. Ssd: Single shot multibox detector[C]//Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14. Springer International Publishing, : 21–37. (2016).
Cai, Z., Vasconcelos, N. & Cascade, R-C-N-N. High quality object detection and instance segmentation[J]. IEEE Trans. Pattern Anal. Mach. Intell. 43 (5), 1483–1498 (2019).
Zhang, S. et al. Dense distinct query for end-to-end object detection[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. : 7329–7338. (2023).
Zhang, H. et al. Guided attentive feature fusion for multispectral pedestrian detection[C]//Proceedings of the IEEE/CVF winter conference on applications of computer vision. : 72–80. (2021).
Cao, Y. et al. Multimodal object detection by channel switching and spatial attention[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. : 403–411. (2023).
Zhao, T., Yuan, M. & Wei, X. Removal and selection: improving rgb-infrared object detection via coarse-to-fine fusion[J]. (2024). arXiv preprint arXiv:2401.10731.
Jia, X. et al. LLVIP: A visible-infrared paired dataset for low-light vision[C]//Proceedings of the IEEE/CVF international conference on computer vision. : 3496–3504. (2021).
Taghipour, A. & Ghassemian, H. Hyperspectral anomaly detection based on frequency analysis of repeated spatial patterns[C]//2020 International Conference on Machine Vision and Image Processing (MVIP). IEEE, : 1–6. (2020).
Taghipour, A. & Ghassemian, H. Visual attention-driven framework to incorporate spatial-spectral features for hyperspectral anomaly detection[J]. Int. J. Remote Sens. 42 (19), 7454–7488 (2021).
Acknowledgements
This research was supported by the following projects: (1) Inner Mongolia Science and Technology Department, Inner Mongolia Natural Science Foundation Program, 2024QN06012. (2) Inner Mongolia Autonomous Region Department of Education, First-class Discipline Research Special Project, YLXKZX-NKD-014. (3) Inner Mongolia Autonomous Region Department of Education, Scientific Research Project of Higher Education Institutions in Inner Mongolia Autonomous Region, NJZY23081. (4) Inner Mongolia Science and Technology Department, 2022 Third Batch of Regional Key R&D and Achievement Transformation Program Projects (Social Public Welfare), 2022YFSH0044. (5) Project of Basic Research Funds for Colleges and Universities directly under Inner Mongolia,2023QNJS198.
Author information
Authors and Affiliations
Contributions
Conceptualization, G.R. and G.L.; methodology, G.L.; software, G.R.; validation, G.L., G.R. and J.W.; formal analysis, J.W.; investigation, M.Z.; resources, Z.Y.; data curation, B.J.; writing—original draft preparation, H.G.; writing—review and editing, Q.G.; visualization, G.L.; supervision, G.L.; project administration, G.R.; funding acquisition, G.R. All authors have read and agreed to the published version of the manuscript.”
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, G., Ren, G., Wang, J. et al. Cross-modal edge-enhanced detector for UAV-based multispectral object detection. Sci Rep 16, 1252 (2026). https://doi.org/10.1038/s41598-025-30786-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-30786-9
