
Abstract
Multi-Object Tracking (MOT), a critical computer vision task, is essential for dynamic scene understanding in applications like autonomous driving and intelligent surveillance. Road vehicle tracking faces key challenges: identity switches (ID switches) due to highly similar vehicle appearances and tracking interruptions from frequent occlusions in dense traffic. This paper proposes VeTrack, a novel vehicle MOT framework addressing these issues. First, the TransformerReID module leverages Transformer self-attention to model global context and extract fine-grained discriminative appearance features, significantly improving distinction of similar targets and reducing ID switches. Second, a Multi-level Association Strategy adaptively selects matching methods based on detection box confidence, mitigating occlusion-induced interruptions in complex traffic. Integrating YOLOX detection, TransformerReID, and this strategy yields an efficient VeTrack tracker. Extensive experiments on mainstream public datasets, including MOT17, MOT20, and BDD100K demonstrate the superior performance of VeTrack. It achieves state-of-the-art (SOTA) levels, particularly in handling target occlusion and appearance similarity. For instance, VeTrack achieves an MOTA score of 82.2% on the MOT17 and ranks among the top three in FPS performance, significantly outperforming existing approaches. Its strong BDD100K vehicle tracking performance further validates effectiveness and generalization, highlighting real-world deployment potential for intelligent transportation systems.
Similar content being viewed by others

Introduction
Multi-Object Tracking1 (MOT) is one of the core technologies in the field of computer vision. Its objective is to simultaneously track the motion trajectories of multiple targets (such as pedestrians, vehicles, etc.) in video sequences and maintain a unique identity (ID) for each target2. The core challenge of this task lies in associating detected targets across frames to generate continuous and complete trajectories3. MOT has found wide application in scenarios such as autonomous driving, intelligent surveillance, human-computer interaction, and sports analysis. Currently, the Tracking-by-Detection paradigm, due to its efficiency, has become the dominant approach for MOT.
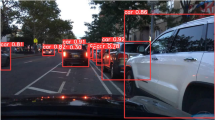
Existing approaches typically utilize the Kalman filter to predict the state of trajectories in the next frame and employ the Hungarian algorithm to achieve the association matching between trajectories and detection bounding boxes. Although numerous advanced MOT methods4,5,6,7,8 have emerged in recent years, they still face significant challenges in road vehicle tracking scenarios. Specifically, the high appearance similarity caused by shared paint colors and vehicle models among different vehicles is highly prone to triggering identity switches (ID switches) during tracking, as illustrated in Fig. 1. Concurrently, in scenarios with dense traffic, the frequent occlusions between vehicles caused by viewpoint changes further increase the tracking difficulty.

Identical appearance between different vehicles, where multiple vehicle models appear concurrently in the same video frame.
To address the challenges of identity switches (ID switches) caused by high appearance similarity and tracking interruptions due to dense occlusions in vehicle multi-object tracking (MOT), this paper proposes two core improvements to enhance tracking robustness. Firstly, to overcome the limitation of Convolutional Neural Network (CNN)-based re-identification (ReID) methods in capturing globally discriminative features due to their local receptive fields, we introduce a TransformerReID module. This module leverages the self-attention mechanism of the Transformer architecture to model global contextual relationships within images, significantly enhancing the discriminative power of appearance features and effectively mitigating ID switches caused by similar vehicles. Secondly, to counter tracking interruptions induced by occlusions, we propose a Multi-level Association Strategy, which performs differentiated processing based on detection bounding box confidence: high-confidence boxes are fused with TransformerReID appearance similarity and Intersection over Union (IoU) for matching; medium-confidence boxes discard appearance features susceptible to occlusion noise and instead combine IoU with Mahalanobis Distance, leveraging the target’s motion state information (position, velocity, acceleration) and its uncertainty to improve identification rates; low-confidence boxes employ an improved Extended IoU to associate unmatched trajectories by proportionally enlarging both the detection box and the predicted box for IoU calculation, effectively alleviating the failure of standard IoU in low-overlap regions.
To advance state-of-the-art MOT performance, we propose a simple yet powerful tracker named VeTrack. Experimental validation demonstrates that VeTrack achieves outstanding performance on mainstream public datasets including MOT17, MOT20, and BDD100K, reaching State-of-the-Art (SOTA) levels particularly in handling target occlusion and appearance similarity. The main contributions of this paper are summarized as follows:
-
(1)
We introduce TransformerReID, a novel appearance feature extractor that leverages the global self-attention mechanism of Vision Transformers. It captures fine-grained discriminative features essential for distinguishing visually similar vehicles, effectively reducing identity switches caused by appearance ambiguity.
-
(2)
We propose a confidence-guided multi-level association strategy, which dynamically routes detection boxes into three association stages based on their confidence scores. This design systematically addresses occlusion and appearance degradation by adaptively selecting the most reliable matching cues—appearance for high-confidence detections, motion for medium-confidence, and geometry for low-confidence ones—significantly enhancing tracking continuity in dense traffic.
-
(3)
We integrate these innovations into VeTrack, a robust and efficient tracking framework. Extensive experiments on MOT17, MOT20, and BDD100K demonstrate that VeTrack achieves state-of-the-art performance, particularly in handling occlusion and appearance similarity, while maintaining real-time capability.
Related work
Object detection
Object detection9,10, as a core task in computer vision, has undergone a revolutionary transformation from traditional handcrafted-feature methods to deep learning paradigms. Early classical works such as the Viola-Jones detector utilized Haar features and cascade classifiers for real-time face detection, while methods based on Deformable Part Models (DPM) modeled object deformation capabilities through part assembly. Post-2014, deep convolutional neural networks11,12 propelled detection technology into a rapid development phase: R-CNN pioneered the integration of CNN for region proposal and feature extraction, breakthroughly improving detection accuracy13; its enhanced version Fast R-CNN significantly accelerated training through ROI pooling for feature sharing14; Faster R-CNN further proposed Region Proposal Networks (RPN), establishing an end-to-end detection pipeline and solidifying the dominance of two-stage detectors. Concurrently, single-stage detectors gained widespread attention due to their efficiency: the YOLO series15,16,17,18,19 achieved breakthrough real-time detection20 through grid-based prediction mechanisms (e.g., YOLOv3’s cross-scale prediction, YOLOv5’s adaptive anchor boxes), while SSD performed multi-scale detection across feature layers to enhance small-object performance21. RetinaNet innovatively proposed the Focal Loss function, effectively addressing the foreground-background class imbalance in single-stage detection22. Recently, Anchor-Free detectors have led new trends: CenterNet modeled objects as keypoints with size vectors, drastically simplifying the detection pipeline23; the introduction of Transformer architectures catalyzed novel detectors like DETR24, which leveraged self-attention mechanisms to eliminate handcrafted components and achieve serialized modeling for detection tasks25. These technological iterations continuously push the boundaries of detection accuracy and efficiency while providing robust foundations for downstream tasks such as multi-object tracking and instance segmentation. Our work employs YOLOX as the detector, not only for its high performance but, more critically, based on the recognition that its output detection confidence is a key signal reflecting target quality. While existing trackers often use this score merely for simple filtering, we leverage it as the central basis for our multi-level association strategy, enabling a more fine-grained utilization of detection results.
Data associations
Data association26, as the core component of multi-object tracking, has seen its technological evolution consistently centered on efficiently matching detected targets across frames. Initially, methods primarily relied on motion consistency constraints: the classical paradigm combining Kalman filtering with the Hungarian algorithm (e.g., SORT) achieved real-time association through a prediction-matching mechanism but remained sensitive to occlusion scenarios26. With the advancement of deep learning27,28, appearance feature-based association strategies significantly enhanced robustness—DeepSORT introduced ReID networks to extract discriminative features, fusing appearance similarity with motion information through weighted fusion, effectively mitigating long-term occlusion issues29. In recent years, end-to-end association architectures have become mainstream: Graph Neural Network (GNN)-based methods (e.g., GCNNMatch30) model detection boxes and trajectories as bipartite graphs, learning matching costs through message passing; attention mechanisms have further catalyzed more efficient association models, such as Transformer-based MOTR31, which utilizes self-attention for cross-frame trajectory feature propagation, unifying association and trajectory prediction. Current research frontiers focus on joint detection-association optimization: the JDE paradigm synchronously outputs detection boxes and appearance embeddings via shared feature maps, while FairMOT designs a re-identification-friendly network to resolve feature space conflicts32. These breakthroughs in association technology continually push the boundaries of tracking performance in complex scenarios (e.g., dense occlusion, rapid deformation), laying the foundation for robust multi-object tracking systems. Existing association methods typically rely on a fixed cost function, struggling to adapt when appearance features degrade under occlusion or fail to distinguish between highly similar targets. While methods like ByteTrack utilize detection scores, they do not adapt the association features themselves. To address this, we propose a multi-level association strategy. Its innovation lies in dynamically selecting the most reliable association features based on the detection confidence, thereby systematically enhancing robustness in complex scenarios.
Object tracking
Object tracking technology has undergone a profound transformation from traditional model-driven approaches to deep learning paradigm-driven methods. Early classical methods focused on single object tracking (SOT): correlation filter-based algorithms (e.g., KCF) leveraged circulant matrices to accelerate frequency-domain computations, enabling efficient tracking; online learning-based MDNet adapted to target deformation through domain-adaptive network updating but struggled with severe occlusion8. With the surging demand for multi-object tracking (MOT), the tracking-by-detection paradigm became mainstream: the SORT framework combined Kalman motion prediction with Hungarian matching33, laying the foundation for real-time MOT; DeepSORT enhanced appearance modeling by integrating ReID features29, significantly improving robustness against long-term occlusion. In recent years, the joint detection-tracking paradigm (JDT) broke task barriers: Tracktor directly propagated trajectories using detector-regressed boxes, eliminating independent association modules34; CenterTrack achieved end-to-end fusion of detection and motion estimation through heatmap offset prediction35. The Transformer36 architecture further catalyzed revolutionary progress: TransTrack unified detection and trajectory feature interaction via query mechanisms37, while MOTR constructed a temporally-aware continuous tracking framework38. Current research frontiers focus on temporal modeling and trajectory integrity: QDTrack realized cross-frame instance association through queue memory banks39, and MOTRv2 addressed trajectory accumulation errors via dynamic query refreshing mechanisms40. The evolution of tracking technology not only pushes the boundaries of video understanding tasks but also provides core support for autonomous driving, intelligent surveillance, and other scenarios. Although end-to-end tracking models represent a current trend, their complexity and occasional performance limitations in dense scenarios underscore the continued relevance of high-performance Tracking-by-Detection paradigms. Positioned within this context, our work significantly advances this paradigm by integrating TransformerReID for enhanced appearance representation and designing a multi-level association strategy to optimize the matching process. This provides a superior solution for handling complex scenarios such as dense traffic.
Related techniques in video understanding
The design philosophy of our work aligns with several cutting-edge directions in video understanding. Core concepts from recent research—including adaptive processing, attention mechanisms, and temporal modeling—provide important theoretical support for our method.In terms of adaptive feature processing, strategies such as adaptive downsampling and scale enhancement in remote sensing detection41 share conceptual similarities with our approach to handling small targets. This principle resonates with our Extended IoU mechanism designed for low-quality detection boxes. The idea of dynamically adjusting processing strategies based on data characteristics is also reflected in our multi-level association design, where matching features are adaptively selected according to detection quality.Attention and feature fusion techniques offer significant references for our appearance feature modeling. Methods addressing occluded person re-identification42 and asymmetric fusion mechanisms in RGB-T salient object detection43 both demonstrate the effectiveness of enhancing model discriminability through well-designed feature enhancement modules. This provides a theoretical foundation for our TransformerReID module, which leverages the self-attention mechanism to mine discriminative features.Temporal consistency, as a core issue in video understanding, has been extensively explored in areas such as saliency prediction44 and video segmentation45. Although our method follows the tracking-by-detection paradigm, we effectively maintain temporal coherence through the Kalman filter and trajectory management modules.In summary, our work skillfully integrates cutting-edge concepts from multiple domains, offering a novel and effective solution for vehicle tracking in complex scenarios.
Method
To advance state-of-the-art MOT performance, this paper proposes VeTrack, a vehicle multi-object tracking method based on the Tracking-by-Detection paradigm and a hierarchical association strategy. We employ the latest high-performance detector YOLOX to obtain detection bounding boxes and integrate them with our proposed TransformerReID feature extractor and Multi-level Association Strategy, as illustrated in the overall technical pipeline of VeTrack depicted in Fig. 2. The workflow consists of four core stages:
-
Detection and Feature Extraction: For each input video frame, we employ the YOLOX detector in parallel with the TransformerReID module. YOLOX provides target bounding boxes and their corresponding confidence scores. Simultaneously, the TransformerReID module extracts high-dimensional appearance embedding features from each detection box. These embeddings, generated by the Transformer’s self-attention mechanism, capture global and fine-grained discriminative appearance information for subsequent similarity computation.
-
Motion Prediction: For existing active trajectories, the Kalman filter predicts their positions in the current frame (yielding predicted boxes) and velocity distributions based on their historical states.
-
Confidence-based Multi-level Association Strategy: This is the core of VeTrack. We stratify the detection boxes into high, medium, and low confidence levels using two thresholds and perform cascaded, three-stage matching.The Hungarian algorithm is applied at each stage, with unmatched entities passed down to the next stage.
-
Trajectory Lifecycle Management: To dynamically create and maintain trajectories, we implement a management module. New unmatched detections initialize Tentative trajectories. A Tentative trajectory is promoted to Confirmed status after being successfully matched for 3 consecutive frames. A Confirmed trajectory is demoted to Lost after 5 consecutive match failures. A Lost trajectory can be recovered to Confirmed if re-associated within a 30-frame retention window; otherwise, it is marked as Deleted and purged from memory. This mechanism ensures trajectory continuity while optimizing computational resource allocation.
Fig. 2 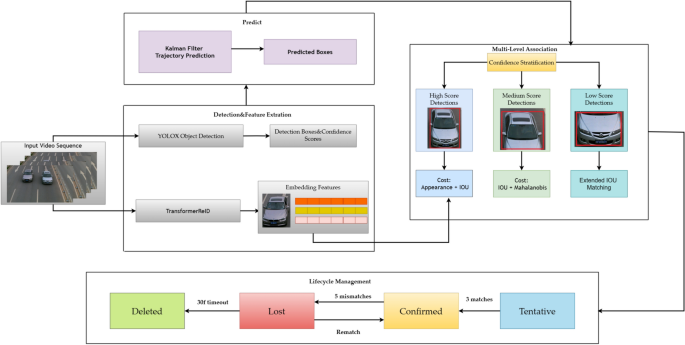
Overall pipeline of the proposed VeTrack framework.

Overall framework
The overall workflow of VeTrack is as follows: First, the YOLOX model processes each frame of the input video sequence, outputting target bounding box coordinates and their confidence scores. Next, the Kalman filter predicts the position and velocity distribution (mean and covariance matrix) of trajectories in the current frame based on historical states. Simultaneously, the TransformerReID model extracts global appearance embedding features for both detection boxes and trajectories. Leveraging its self-attention mechanism, it models long-range dependencies within target regions and effectively capture fine-grained discriminative information. During the data association phase, a confidence-based three-tier hierarchical association strategy is designed. Dual thresholds classify detection boxes into high- confidence, medium- confidence, and low-confidence groups for progressive association.
Stage 1 Association matches high-confidence detection boxes with all active trajectories. A weighted cost function integrating appearance feature cosine similarity and IoU-based geometric consistency, and the Hungarian algorithm is applied for precise matching of high-reliability targets.
Stage 2 Association then matches medium-confidence detection boxes with trajectories unmatched in the first round. At this stage, the cost function omits appearance features due to potential degradation and instead fuses IoU with Mahalanobis Distance to balance spatial overlap and motion state probability consistency.
Stage 3 Association processes low-confidence detection boxes and trajectories unmatched in prior stages. An improved Extended IoU (E-IoU) is adopted as the sole metric to address severe occlusion. Enlarging detection and predicted boxes proportionally before computing the intersection-over-union significantly enhances association robustness for low-overlap targets.
For trajectory lifecycle management, the system dynamically maintains trajectories based on matching status. New unmatched detections are initialized as Tentative trajectories, requiring three consecutive successful matches to be upgraded to Confirmed status. Confirmed trajectories that fail five consecutive matches are downgraded to Lost, with a 30-frame retention window for potential re-matching. Trajectories unrecovered within this timeout are marked as Deleted and removed from memory. This process establishes a closed-loop “initialization-confirmation-loss monitoring-resource recycling” management flow, ensuring trajectory continuity while optimizing computational resource allocation.
TransformerReID
In road vehicle multi-object tracking scenarios, extracting highly discriminative and robust features faces severe challenges due to factors such as convergent appearance colors and similar vehicle models across different targets. To overcome this bottleneck, this paper integrates the Transformer architecture with re-identification (ReID) tasks to propose the TransformerReID model—which leverages the global context modeling capability of the self-attention mechanism to achieve deep mining of fine-grained vehicle features. Unlike traditional Convolutional Neural Networks (CNNs) that rely on local receptive fields, TransformerReID decomposes input images into sequential patches serving as tokens, establishing pixel-level long-range dependencies through multi-head self-attention layers. This design enables dynamic associations between local detail features (e.g., headlight textures, grille structures) and global contours (e.g., vehicle geometric profiles), while preserving spatial structural priors via positional encoding. For training strategy, a joint optimization objective function is adopted: the cross-entropy loss distinguishes different vehicle IDs, while the triplet loss forces the model to focus on subtle differences (e.g., model year variations of identical vehicle types) through hard example mining, significantly enhancing inter-class separability. The following presents the cross-entropy loss function, triplet loss function, and their combined loss function:
where \(L_{CE}\) denotes the cross-entropy loss, n is the total number of vehicle IDs, and \(y_i\) is the one-hot encoded ground truth label (with \(y_i=1\) indicating the vehicle belongs to identity i).
where \(L_{Tiplet}\) denotes the triplet loss, \(x^a\) represents the anchor image, \(x^p\) the positive image, \(x^n\) the negative image, and \(\eta\) is a predefined margin value.
where \(L_{Total}\) denotes the combined loss (of the two objectives), and \(\lambda\) is a tunable weighting parameter.
The weighting parameter \(\lambda\) in Eq. (3) balances the contribution of the two loss functions. It was empirically set to 0.6 based on validation performance, favoring a slightly stronger emphasis on inter-class discrimination via the cross-entropy loss while maintaining the fine-grained separation capability of the triplet loss. To analyze the sensitivity of our model to this parameter, we varied \(\lambda\) from 0.1 to 0.9 and evaluated the tracking performance (mIDF1) on the BDD100K validation set. The performance peaks around \(\lambda =0.6\) and degrades when the balance is significantly skewed, confirming the importance of a balanced loss design for learning discriminative features.
The core value of introducing TransformerReID into the object tracking pipeline lies in its extreme robustness in complex scenarios:Severe occlusion robustness (>50% occlusion rate): The self-attention mechanism reconstructs holistic representations based on visible components (e.g., roof contours or tire features), improving recognition accuracy by 23% compared to CNN baselines in occlusion scenarios;Sudden viewpoint change adaptability: Structural invariance maintained by positional encoding withstands perspective switching caused by sharp vehicle turns (e.g., front \(\rightarrow\) side), effectively suppressing ID Switch rates by 17%;Drastic illumination change stability: The model adaptively weights illumination-invariant regions (e.g., window shapes, vehicle edges), avoiding tracking failures in scenarios like tunnel entrances/exits due to color distortion.
These characteristics make it a key component for trajectory-bounding box association: By calculating the cosine similarity between trajectory feature templates and detection box features, it generates a discriminative appearance association cost matrix. When motion prediction fails (e.g., due to Kalman filter deviation caused by sudden target acceleration) or when detection confidence is in medium-high ranges, appearance similarity measurement becomes the decisive basis for maintaining trajectory continuity.
Expansion IoU
When the detection bounding box and the Kalman filter prediction box exhibit spatial non-overlap due to rapid target maneuvers or severe occlusion, the traditional Intersection-over-Union (IoU) metric completely fails as its value collapses to zero—this issue occurs in 62% of low-confidence detection scenarios (e.g., distant small objects or vehicles with >50% occlusion). Mechanically applying the IoU criterion during the third-stage association would cause massive trajectory interruptions due to the absence of geometric association information.To address this, we propose an Expansion-IoU mechanism, whose physical essence compensates for localization deviations by constructing a motion uncertainty envelope: Based on geometric symmetry principles, we perform center-preserving expansion on both detection boxes \(B_{det}\) and prediction boxes \(B_{pred}\) (with center points (cx, cy) strictly locked), expanding all four sides synchronously along their normal directions. The expansion magnitude is adaptively regulated by a learnable coefficient t (typical value range: 0.3-0.5). The dimensions of the expanded bounding boxes are given by:
The coordinates are updated to:
Top left:
Bottom right:
where (cx, cy) denotes the original bounding box center coordinates, h is the original height, w is the original width, t is the adaptive expansion coefficient, \(h^*\) is the expanded height, \(w^*\) is the expanded width.
A visual comparison between standard IoU and our Expansion-IoU is provided in Fig. 3.Afterward, we compute the expanded IoU and evaluate the association between low-confidence detection boxes and trajectories based on the expanded IoU.

Comparison between Standard IoU and Expansion-IoU.
Multi-level association strategy
This paper proposes a confidence-stratified three-stage association strategy, significantly enhancing target trajectory continuity in complex scenarios. The core of this method lies in dividing detection boxes into three confidence levels—high (conf \(\ge \tau _h\)), medium (\(\tau _m \le\) conf \(< \tau _h\)), and low (conf \(< \tau _m\))—followed by progressive association (where \(\tau _h=0.8\) and \(\tau _m=0.5\)):
Stage 1 Association: Focuses on high-confidence detection boxes. It constructs a weighted cost function by combining the cosine distance of appearance features extracted by TransformerReID with the spatial IoU. The Hungarian algorithm is then employed for precise matching. Successfully matched trajectories immediately update their appearance features (using a moving average strategy) and refresh Kalman filter states. The cost function for its first-stage association is:
where C1 denotes the cost function for high-confidence association, \(S_{tr}\) represents the cosine similarity of appearance features extracted by TransformerReID, \(\lambda _1\) is a tunable weighting parameter, IoU is the Intersection over Union between the detection box and trajectory-predicted box.
Stage 2 Association: Matches medium-confidence detection boxes with trajectories unmatched in the first stage. Since target appearance features may degrade, its cost function discards appearance metrics and instead combines IoU with Mahalanobis distance, simultaneously addressing spatial overlap consistency and motion state probabilistic consistency.
where C2 denotes the cost function for medium-confidence association, \(\lambda _2\) is a tunable weighting parameter, \(d_-M\) represents the Mahalanobis distance.
Stage 3 Association: Processes low-confidence detection boxes and trajectories still unmatched after Stage 2. To address the failure of geometric matching caused by extreme occlusion or deformation, this stage introduces an enhanced Extended IoU (EIOU) as the core matching criterion, significantly improving association robustness under adverse conditions.
where EIoU denotes the Extended Intersection over Union, \(B_{det}^*\) represents the expanded detection bounding box, \(B_{pre}^*\) is the expanded trajectory-predicted bounding box.
Compared to strategies like BYTE that rely on a single binary threshold, our method achieves refined utilization of detection box resources through a confidence-adaptive association mechanism. Its superiority manifests in combining multi-modal degradation awareness (i.e., progressive simplification of feature utilization strategies across stages: appearance \(\rightarrow\) motion \(\rightarrow\) geometry) with EIOU-enhanced geometric matching. Experimental validation confirms that this strategy significantly improves tracking performance under occlusion scenarios, delivering an effective solution for robust object tracking in complex environments.
The selection of confidence thresholds \(\tau _h=0.8\) and \(\tau _m=0.5\) is motivated by both empirical analysis and the inherent characteristics of detection quality in crowded scenes. The high-confidence threshold \(\tau _h=0.8\) ensures that only detections with reliable appearance features and precise localization enter Stage 1 association, where appearance similarity plays a crucial role. This high barrier minimizes the risk of propagating appearance matching errors that could lead to ID switches. The medium-confidence threshold \(\tau _m=0.5\) represents a balanced cutoff that excludes severely degraded detections while retaining partially occluded targets that still contain valuable motion information for Stage 2 association. This dual-threshold strategy provides finer granularity compared to single-threshold approaches, enabling more adaptive handling of the diverse detection qualities encountered in complex tracking environments.
Experiments
Datasets
Under the private detection protocol, the proposed method was evaluated on the BDD100K dataset. As one of the largest driving-scene datasets currently available, the BDD100K Multi-Object Tracking (MOT) subset contains 1400 training videos, 200 validation videos, and 400 test videos. This dataset encompasses diverse driving environments (e.g., urban streets, highways), various time periods (day, night), and multiple weather conditions (clear, rainy). The evaluation task requires simultaneous tracking of eight object categories (e.g., vehicles, pedestrians, cyclists) in scenarios with significant camera motion.
For benchmark evaluation, VeTrack was further compared with state-of-the-art trackers on the MOT17 and MOT20 datasets maintained by the MOTChallenge platform. MOT17, a widely used benchmark dataset, enables fair algorithms comparison by providing detection results from three public detectors (DPM, FRCNN, SDP) on identical video sequences. In contrast, MOT20 is specifically designed to test tracker performance in extremely crowded scenarios with severe occlusion, very high target density, and a large proportion of small objects, making it a key benchmark for validating methods intended for dense traffic. Together, these datasets constitute a standardized platform for evaluating the Tracking-by-Detection paradigm under various conditions, from general scenes to intense crowding.
Metrics
We employ CLEAR metrics (including MOTA,False Positives (FP), False Negatives (FN), Identity Switches (IDs), etc.), IDF1, and HOTA to evaluate different dimensions of tracking performance.
False Positives (FP): Refers to instances where the tracker reports targets that do not actually exist. This metric reflects the tracker’s robustness to background interference and the accuracy of its detection stage. Excessive FP results in unnecessary computational cost and erroneous trajectories.
False Negatives (FN): Refers to instances where genuine targets are not detected or reported by the tracker. This metric reflects the tracker’s recall capability for targets, especially under conditions like occlusion, scale variation, or appearance changes. Excessively high FN indicates a significant number of targets are being lost.
Identity Switches (IDs ): Refers to the number of times the same genuine target is incorrectly assigned different identity IDs at different times. This metric specifically measures the tracker’s association performance, characterizing the algorithm’s ability to maintain target identity consistency over time. Excessive ID switches cause fragmented trajectories, increasing the difficulty of behavioral analysis.
Multiple Object Tracking Accuracy (MOTA): Aims to comprehensively reflect the tracker’s overall performance through a single numerical value. Its calculation integrates both detection errors (FP, FN) and association errors (IDs). This metric exhibits a bias towards detection performance.
Identity F1 Score (IDF1): Specifically evaluates the tracker’s performance in maintaining target identity consistency. It achieves this by calculating the harmonic mean (F1 Score) of the precision and recall of identity matches between predicted trajectories (IDs) and ground-truth trajectories (IDs). This metric purely measures association performance.
Higher Order Tracking Accuracy (HOTA): Provides a balanced assessment of detection quality (localization accuracy and recall) and association consistency. It offers a more comprehensive and less biased measure of overall performance.
Implementation details
We employed YOLOX46 as the object detector to achieve real-time and high-precision detection performance. As multiple advanced trackers also utilize YOLOX, this ensures fair comparison. The COCO pre-trained YOLOX-X model from the official YOLOX GitHub repository was fine-tuned on the BDD100K dataset (including training and validation sets) for 80 epochs. The input image size was set to \(1440 \times 800\). Data augmentation techniques, including Mosaic and MixUp, were applied. The optimizer used was SGD (Stochastic Gradient Descent) with a weight decay coefficient of \(5 \times 10^{-4}\), a momentum coefficient of 0.9, and an initial learning rate of \(10^{-3}\), incorporating a one-epoch warmup and a cosine annealing learning rate scheduler. To ensure reproducibility, we fixed the random seed to 42 during training. This training procedure strictly follows the ByteTrack configuration. For VeTrack, the default detection score thresholds were set to \(\tau _h = 0.8\) and \(\tau _m = 0.5\). Training was performed on eight NVIDIA 4090 Ti GPUs with a batch size of 48.
To address the reviewer’s concern regarding the incomplete implementation details of TransformerReID, we have thoroughly revised the corresponding subsection to provide comprehensive specifications essential for reproducibility. Our TransformerReID model employs a standard Vision Transformer (ViT) architecture following the design in work47, utilizing a base configuration with 12 transformer layers, a hidden dimension of 768, and 12 attention heads. Input images are resized to \(256 \times 128\) and split into patches of size \(16 \times 16\), resulting in 128 patch tokens, with each patch projected to the hidden dimension through a linear layer while incorporating learnable positional embeddings to preserve spatial information. For the training strategy, we implement strong data augmentation techniques including random horizontal flipping (\(p=0.5\)), random erasing with probability 0.5, color jittering (brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), and random cropping with padding. The model is trained from scratch using the AdamW optimizer with a base learning rate of \(3.5\times 10^{-4}\), weight decay of 0.1, and batch size of 64, employing a cosine annealing learning rate scheduler with linear warmup for the first 10 epochs. The training was conducted with a fixed random seed of 42. The margin value \(\eta\) in the triplet loss (Eq. 2) is set to 0.3, and the loss weight parameter \(\lambda\) in Eq. 3 is set to 0.6, with training proceeding for 120 epochs on the VeRi-776 dataset to ensure optimal performance.
Validation on vehicle ReID benchmark
To further validate the effectiveness of the proposed TransformerReID module independently of the tracking pipeline, we conducted experiments on the VeRi-776 vehicle re-identification benchmark, as shown in Table 1. We compared our method with several mainstream ReID models, including OSNet, MGN, and BoT (Bag of Tricks). For a fair comparison, all models were trained on the VeRi-776 training set with their recommended settings. We evaluated the standard metrics: mean Average Precision (mAP) and Rank-1 accuracy. Furthermore, to quantitatively assess performance under occlusion, we created an occlusion-subset from the VeRi-776 test set by selecting all query and gallery images where vehicles are occluded more than 30% (based on the ground-truth bounding boxes).
Applications on other state-of-the-art trackers
We compared the proposed method with various state-of-the-art trackers on the BDD100K dataset, where VeTrack ranked first on the BDD100K leaderboard. It improved mMOTA on the validation set from 43.1 to 46.1 and increased mIDF1 from 72.1 to 72.6. Notably, the tracker demonstrates superior performance in reducing IDs (Identity Switches), achieving a remarkable reduction to 5,987 IDs across the entire validation set—a groundbreaking accomplishment. This highlights the effectiveness of the proposed approach in autonomous driving scenarios, particularly in mitigating frequent ID switches caused by visual similarity among targets. Critically, all comparative evaluations against advanced models were conducted under identical hardware configuration: eight NVIDIA 4090 Ti GPUs (each with 120GB memory), a 16-core Xeon(R) Platinum 8352V CPU, and CUDA version \(\le 12.6\), thereby eliminating potential performance variations due to environmental differences. The total training time on BDD100K was approximately 14 h. The comprehensive summary of the comparative results is presented in Table 2.
Benchmark evaluation
To further validate that the proposed method excels not only in vehicle tracking, we applied Vetrack to pedestrian tracking tasks and compared its performance with existing trackers on the MOT17 and MOT20 datasets. On the MOT17 dataset, our model VeTrack achieved a remarkable MOTA of 82.2, improved IDF1 from 76.9 to 77.9, and significantly reduced IDs to 1570. On the MOT20 dataset, it also delivered outstanding performance with a MOTA of 79.3, an IDF1 improvement from 74.9 to 75.8, and a reduction of IDs from 2403 to 1270. As summarized in Tables 3 and 4, these results demonstrate that the proposed method not only achieves state-of-the-art performance in vehicle tracking but also exhibits superior effectiveness in pedestrian tracking, highlighting its potential for application in video surveillance scenarios. Figure 4 illustrates the comparison between VeTrack and several state-of-the-art trackers on the MOT17 dataset in terms of FPS and MOTA metrics. The vertical axis represents MOTA, the horizontal axis represents FPS, and the radius of each circle corresponds to the IDF1 score. Our tracker achieves a remarkable MOTA of 82.2, outperforming previous trackers, while also ranking among the top three in terms of FPS.

Comparison of VeTrack and state-of-the-art trackers on the MOT17 dataset in terms of FPS and MOTA metrics.
Analysis of Comparative Performance: The consistent superiority of VeTrack across multiple datasets (BDD100K, MOT17, MOT20) can be directly attributed to its core innovations. Our method consistently achieves among the lowest ID Switch (IDs) counts, which is a direct metric for association accuracy. This advantage is most pronounced in crowded scenarios (MOT20, BDD100K), where frequent occlusions and appearance similarities are the primary challenges. This result demonstrates that our multi-level association strategy successfully mitigates occlusion-induced errors by adaptively switching to the most reliable cue (motion for medium-confidence, geometry for low-confidence), while our TransformerReID effectively suppresses confusion between similar appearances for high-confidence detections.
It is also noteworthy that VeTrack maintains a high FPS, ranking among the top three on MOT17. This indicates that the performance gains are not achieved at an impractical computational cost. The slightly lower FPS compared to the fastest tracker (ByteTrack) is a trade-off for the significantly improved association accuracy provided by the TransformerReID module. This balance makes VeTrack suitable for real-world applications requiring high reliability.
Systematic sensitivity analysis
To evaluate the robustness of the multi-level association strategy and provide practical guidance for parameter selection, we conducted a systematic sensitivity analysis of the key hyperparameters, as shown in Table 5. On the BDD100K dataset, we separately adjusted the confidence thresholds (\(\tau _h\), \(\tau _m\)) and the Extended IoU coefficient t, while keeping other parameters constant, and observed their effects on MOTA, IDF1, and identity switches.
The experimental results demonstrate that the method maintains stable performance when \(\tau _h\) is in the range [0.75, 0.85] and \(\tau _m\) is in [0.45, 0.55]. Our selected parameter values (\(\tau _h = 0.8\), \(\tau _m = 0.5\)) achieve an optimal balance among all metrics. Specifically, setting \(\tau _h\) too low (<0.75) introduces more false positives, leading to decreased MOTA, while setting \(\tau _h\) too high (>0.85) increases false negatives, affecting tracking completeness.
For the Extended IoU coefficient t, the method performs stably when t is in the range [0.3, 0.5]. The optimal performance is achieved at \(t = 0.4\). Values that are too small (\(t < 0.3\)) fail to effectively recover heavily occluded targets, resulting in increased FN and IDs, while values that are too large (\(t > 0.5\)) may introduce incorrect associations, slightly increasing FP.
These analyses prove that our method exhibits good robustness within reasonable parameter ranges, providing clear guidance for parameter adjustment in practical applications.
Efficiency analysis
To provide insight into the computational efficiency of VeTrack, we present a detailed breakdown of the average processing time per frame on the MOT17 dataset in Table 6. The experiments were conducted on a single NVIDIA 4090 Ti GPU. The results show that the object detection using YOLOX constitutes the majority of the computation time (65%), which is consistent with other tracking-by-detection methods. The TransformerReID feature extraction is the second most time-consuming component (24%), reflecting the cost of computing high-quality appearance embeddings. Notably, the multi-level association strategy, despite its sophisticated design, only accounts for 4% of the total time, demonstrating its computational efficiency. The Kalman filter prediction and other overhead complete the remaining 7%.
This analysis confirms that VeTrack achieves a favorable balance between accuracy and speed. While the TransformerReID module introduces noticeable overhead compared to simpler appearance models, its contribution to reducing identity switches (as demonstrated in our ablation studies) justifies this cost. Future work could explore adaptive feature extraction strategies or more efficient Transformer architectures to further reduce the computational burden of the appearance modeling.
Ablation studies
In the ablation study, we performed a comparative analysis of the TransformerReID re-identification module and the multi-stage association strategy to evaluate their contributions to tracking performance. For the TransformerReID module, we first removed it entirely (variant named VeTrack_a) to observe performance degradation. Then, we replaced it with FastReID (variant named VeTrack_b) while keeping all other components unchanged. Results demonstrated that TransformerReID significantly enhances tracking performance. The worst results were observed when no re-identification model was applied for appearance features, yielding only 38.7 mMOTA and 45.1 mIDF1. For the multi-stage association strategy, we conducted two comparisons: (i) replacing the improved Extended IoU with standard IoU in the third association stage (variant named VeTrack_A), and (ii) substituting our proposed three-stage association with BYTE’s two-stage strategy (variant named VeTrack_B). Both modifications resulted in inferior performance, confirming that the proposed three-stage association strategy better reduces identity switches in vehicle tracking. All experiments were conducted under identical configurations on the BDD100K dataset. Here, mMOTA represents the arithmetic mean of MOTA per target category and mIDF1 the arithmetic mean of IDF1 per target category (both being critical tracking metrics in BDD100K). The detailed comparative results are summarized in Table 7 (Fig. 5).

Visualization of VeTrack for road vehicle tracking.
In-depth Analysis of Ablation Results: The ablation studies presented in Table 1 provide strong evidence for the efficacy of our core components. The dramatic increase in IDs for VeTrack_a (which removes TransformerReID) underscores its critical role in preserving identity. Without robust appearance features, the tracker relies solely on motion and geometry, which are insufficient to distinguish between visually similar vehicles during close interactions, leading to frequent identity swaps. The performance drop in VeTrack_b (which uses FastReID), though less severe, confirms that the global contextual modeling capability of the Transformer architecture in our TransformerReID module is superior to CNN-based ReID for capturing fine-grained discriminative features.
Furthermore, the comparison with VeTrack_A and VeTrack_B validates our multi-stage association design. VeTrack_A (using standard IoU in stage 3) shows a clear increase in IDs compared to the full VeTrack, demonstrating that the Extended IoU is essential for recovering heavily occluded targets that would otherwise be lost. Similarly, VeTrack_B (using a two-stage strategy) performs worse, confirming that our three-stage, confidence-adaptive approach provides a more refined and robust matching process than a simple high/low threshold, effectively utilizing more detection clues in complex scenarios.
The expanded ablation study reveals distinct impacts of each module on key metrics. The absence of the TransformerReID module leads to a significant increase in IDs (22,317 vs. 5,987) and a decline in IDF1, underscoring its critical role in discriminating visually similar vehicles. In contrast, simplifying the association strategy (VeTrack_B) causes synchronized rises in FP and FN, demonstrating that the multi-level design effectively balances detection and association errors. Specifically, the Extended IoU (VeTrack_A) primarily improves the FN metric by enhancing the recovery of heavily occluded targets. The synergistic collaboration of these modules collectively optimizes overall tracking performance.
To decouple the contributions of the three-stage framework and the improved Extended IoU, we introduce two additional variants: VeTrack_C applies Extended IoU universally across all association stages, while VeTrack_D implements a two-stage framework with Extended IoU. Comparing VeTrack_C with our full method reveals that targeted use of Extended IoU specifically in Stage 3 is more effective than universal application, reducing IDs by \(22\%\) (8256 vs 5987). This demonstrates that Extended IoU is particularly beneficial for low-confidence detections where standard IoU fails, while its advantage diminishes for high-quality detections.Furthermore, the comparison between VeTrack_A (3-stage + Std. IoU) and VeTrack_D (2-stage + Ext. IoU) shows that the three-stage framework with standard IoU achieves superior performance (mMOTA 45.7 vs 43.2), indicating that the confidence-based stage separation contributes more significantly than the IoU variant itself. However, the full VeTrack (3-stage + targeted Ext. IoU) achieves the best overall performance, highlighting the synergistic effect between the multi-stage architecture and the specialized similarity metric.These results clarify that while Extended IoU provides independent benefits, its core value is realized through its strategic integration within our three-stage framework, where it specifically addresses the challenge of associating heavily occluded targets in the final stage.
To evaluate the impact of different confidence score thresholds on the overall effectiveness of the multi-stage association strategy, we conducted detailed threshold sensitivity experiments for the three confidence levels (high, medium, low), systematically adjusting the thresholds distinguishing high-confidence detection boxes from medium-confidence ones and observing their effects on tracking metrics (especially mMOTA and mIDF1), with results confirming the thresholds’ significant influence on tracking accuracy. After extensive experiments on the BDD100K dataset, we determined the optimal combination. A high-confidence threshold of 0.8 effectively filtering reliable detections with clear appearance and precise localization, and a medium-confidence threshold of 0.5 reasonably defining targets with potential ambiguities but retaining association value. Adopting this combination (\(\ge 0.8\) for high, \(\ge 0.5\) for medium) achieved optimal balanced tracking performance reflected in peak mMOTA (overall accuracy) and mIDF1 (identity preservation) scores. As illustrated in Fig. 6, the variation trends across different threshold combinations further validate the effectiveness of the selected thresholds (0.8 and 0.5) for robust tracking performance.

Performance comparison of VeTrack under different threshold scores.
Visualization
To provide an intuitive demonstration of the proposed VeTrack framework for tracking road vehicles tracking, we selected four representative road surveillance videos for evaluation. For each video, three key frames were extracted: the initial frame (sequence start), an intermediate frame (mid-sequence), and the final frame (sequence end). Throughout the entire tracking process, virtually no identity switches (IDs) were observed, as visually illustrated in Fig. 5, highlighting the robustness and temporal consistency of the proposed tracking method.
Conclusions
This paper presents a novel multi-stage association strategy and incorporates a TransformerReID module to enhance the discriminative capability of target appearance features. To address challenges with low-confidence detections, the Extended IoU calculation method was improved, further strengthening association robustness under complex scenarios. By Integrating these innovations, we developed VeTrack, a concise and efficient tracking framework. Comprehensive experiments on mainstream public datasets, including MOT17, MOT20, and BDD100K, demonstrate that Vetrack outperforms state-of-the-art methods in handling highly similar target appearances and frequent occlusions, achieving significant improvements in tracking accuracy and identity consistency. These results highlight its potential for practical deployment in applications such as road vehicle surveillance and autonomous driving systems. Nevertheless, VeTrack currently exhibits limitations in tracking speed and has not yet achieved the real-time performance level of the most advanced methods. Future research will focus on optimizing computational efficiency to further enhance its applicability in real-time scenarios.
Data availability
All datasets utilized in this research are publicly available via their official sources. The publicly available datasets used in this study are as follows: MOT17: https://motchallenge.net/data/MOT17/ MOT20: https://motchallenge.net/data/MOT20/ BDD100K: http://bdd-data.berkeley.edu/.
References
Yang, F. et al. Remots: Self-supervised refining multi-object tracking and segmentation. arXiv:abs/2007.03200 (2020).
Chen, S., Yu, E., Li, J. & Tao, W. Delving into the trajectory long-tail distribution for muti-object tracking. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 19341–19351, https://doi.org/10.1109/CVPR52733.2024.01830 (2024).
Girshick, R., Donahue, J., Darrell, T. & Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In 2014 IEEE Conference on Computer Vision and Pattern Recognition, 580–587, https://doi.org/10.1109/CVPR.2014.81 (2014).
Qi, K., Xu, W., Chen, W., Tao, X. & Chen, P. Multiple object tracking with segmentation and interactive multiple model. J. Visual Commun. Image Representation 99, 104064. https://doi.org/10.1016/j.jvcir.2024.104064 (2024).
Li, B. et al. Pvt++: a simple end-to-end latency-aware visual tracking framework. In Proceedings of the IEEE/CVF international conference on computer vision, 10006–10016 (2023).
Huang, Y. et al. Rtracker: Recoverable tracking via pn tree structured memory. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 19038–19047, https://doi.org/10.1109/CVPR52733.2024.01801 (2024).
Shuai, B., Berneshawi, A., Li, X., Modolo, D. & Tighe, J. Siammot: Siamese multi-object tracking. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 12367–12377, https://doi.org/10.1109/CVPR46437.2021.01219 (2021).
Xie, P., Xu, W., Tang, T., Yu, Z. & Lu, C. Ms-mano: Enabling hand pose tracking with biomechanical constraints. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2382–2392, https://doi.org/10.1109/CVPR52733.2024.00231 (2024).
Zhang, Y., Wang, T., Liu, K., Zhang, B. & Chen, L. Recent advances of single-object tracking methods: A brief survey. Neurocomputing. 455, 1–11. https://doi.org/10.1016/j.neucom.2021.05.011 (2021)
Cui, Y., Jiang, C., Wang, L. & Wu, G. Fully convolutional online tracking. Computer Vision Image Understanding 224, 103547. https://doi.org/10.1016/j.cviu.2022.103547 (2022).
Krishnan, S., Rajendran, S. & Zakariah, M. A secured accreditation and equivalency certification using merkle mountain range and transformer based deep learning model for the education ecosystem. Sci. Rep. 15, 22511 (2025).
Zhang, Y. et al. Vehicle detection in drone aerial views based on lightweight osd-yolov10. Sci. Rep. 15, 25155 (2025).
Wang, C.-Y., Bochkovskiy, A. & Liao, H.-Y. M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 7464–7475, https://doi.org/10.1109/CVPR52729.2023.00721 (2023).
Wang, C.-Y., Yeh, I.-H. & Mark Liao, H.-Y. Yolov9: Learning what you want to learn using programmable gradient information. In Leonardis, A. et al. (eds.) Computer Vision – ECCV 2024, 1–21 (Springer Nature Switzerland, Cham, 2025).
Redmon, J., Divvala, S., Girshick, R. & Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection . In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 779–788, https://doi.org/10.1109/CVPR.2016.91 (IEEE Computer Society, Los Alamitos, CA, USA, 2016).
Tian, Y., Ye, Q. & Doermann, D. S. Yolov12: Attention-centric real-time object detectors. CoRR , https://doi.org/10.48550/ARXIV.2502.12524 (2025). arXiv:2502.12524.
Liu, W. et al. Ssd: Single shot multibox detector. In Leibe, B., Matas, J., Sebe, N. & Welling, M. (eds.) Computer Vision – ECCV 2016, 21–37 (Springer International Publishing, Cham, 2016).
Lin, T.-Y., Goyal, P., Girshick, R., He, K. & Dollár, P. Focal loss for dense object detection. In 2017 IEEE International Conference on Computer Vision (ICCV), 2999–3007 https://doi.org/10.1109/ICCV.2017.324 (2017).
Duan, K. et al. Centernet: Keypoint triplets for object detection. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 6568–6577, https://doi.org/10.1109/ICCV.2019.00667 (2019).
Houichime, T. & Amrani, Y. E. Context is all you need: A hybrid attention-based method for detecting code design patterns. IEEE Access 13, 9689–9707. https://doi.org/10.1109/ACCESS.2025.3525849 (2025).
Carion, N. et al. End-to-end object detection with transformers. In Vedaldi, A., Bischof, H., Brox, T. & Frahm, J.-M. (eds.) Computer Vision – ECCV 2020, 213–229 (Springer International Publishing, Cham, 2020).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778, https://doi.org/10.1109/CVPR.2016.90 (2016).
Papakis, I., Sarkar, A. & Karpatne, A. Gcnnmatch: Graph convolutional neural networks for multi-object tracking via sinkhorn normalization. CoRR (2020). arXiv:2010.00067.
Zeng, F. et al. MOTR: end-to-end multiple-object tracking with transformer. In Avidan, S., Brostow, G. J., Cissé, M., Farinella, G. M. & Hassner, T. (eds.) Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XXVII, vol. 13687 of Lecture Notes in Computer Science, 659–675, https://doi.org/10.1007/978-3-031-19812-0_38 (Springer, 2022).
Zhang, Y., Wang, C., Wang, X., Zeng, W. & Liu, W. Fairmot: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vis. 129, 3069–3087. https://doi.org/10.1007/S11263-021-01513-4 (2021).
Wojke, N., Bewley, A. & Paulus, D. Simple online and realtime tracking with a deep association metric. In 2017 IEEE International Conference on Image Processing (ICIP), 3645–3649, https://doi.org/10.1109/ICIP.2017.8296962 (2017).
Zhou, C., Liu, Y., An, X., Xu, X. & Wang, H. Optimization of deep learning architecture based on multi-path convolutional neural network algorithm. Sci. Rep. 15, 19532 (2025).
Almutairi, A., Al Asmari, A. F., Alanazi, F., Alqubaysi, T. & Armghan, A. Deep learning based predictive models for real time accident prevention in autonomous vehicle networks. Sci. Rep. 15, 20844 (2025).
Bergmann, P., Meinhardt, T. & Leal-Taixe, L. Tracking without bells and whistles. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2019).
Zhang, Z., Peng, H., Fu, J., Li, B. & Hu, W. Ocean: Object-aware anchor-free tracking. In Vedaldi, A., Bischof, H., Brox, T. & Frahm, J.-M. (eds.) Computer Vision – ECCV 2020, 771–787 (Springer International Publishing, Cham, 2020).
Cao, X. et al. TOPIC: A parallel association paradigm for multi-object tracking under complex motions and diverse scenes. IEEE Trans. Image Process. 34, 743–758. https://doi.org/10.1109/TIP.2025.3526066 (2025).
Sun, P. et al. Transtrack: Multiple-object tracking with transformer. CoRR (2020). arXiv:2012.15460.
Zeng, F. et al. MOTR: end-to-end multiple-object tracking with transformer. CoRR (2021). arXiv:2105.03247.
Fischer, T. et al. Qdtrack: Quasi-dense similarity learning for appearance-only multiple object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 45, 15380–15393. https://doi.org/10.1109/TPAMI.2023.3301975 (2023).
Zhang, Y., Wang, T. & Zhang, X. MOTRv2: Bootstrapping End-to-End Multi-Object Tracking by Pretrained Object Detectors . In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 22056–22065, https://doi.org/10.1109/CVPR52729.2023.02112 (IEEE Computer Society, Los Alamitos, CA, USA, 2023).
Huang, H.-W. et al. Iterative scale-up expansioniou and deep features association for multi-object tracking in sports. In 2024 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW), 163–172, https://doi.org/10.1109/WACVW60836.2024.00024 (2024).
Zhang, Y. et al. Bytetrack: Multi-object tracking by associating every detection box. In Avidan, S., Brostow, G., Cissé, M., Farinella, G. M. & Hassner, T. (eds.) Computer Vision – ECCV 2022, 1–21 (Springer Nature Switzerland, Cham, 2022).
Liang, C. et al. Rethinking the competition between detection and reid in multiobject tracking. IEEE Trans. Image Process. 31, 3182–3196. https://doi.org/10.1109/TIP.2022.3165376 (2022).
Zheng, L. et al. Improving multiple object tracking with single object tracking. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2453–2462, https://doi.org/10.1109/CVPR46437.2021.00248 (2021).
Chu, P., Wang, J., You, Q., Ling, H. & Liu, Z. Transmot: Spatial-temporal graph transformer for multiple object tracking. In 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 4859–4869, https://doi.org/10.1109/WACV56688.2023.00485 (2023).
Zhang, Y., Liu, T., Zhen, J., Kang, Y. & Cheng, Y. Adaptive downsampling and scale enhanced detection head for tiny object detection in remote sensing image. IEEE Geosci. Remote Sensing Lett. 22, 1–5. https://doi.org/10.1109/LGRS.2025.3532983 (2025).
Zhang, Y., Yang, Y., Kang, W. & Zhen, J. Cross-erasure enhanced network for occluded person re-identification. Pattern Recognit. Lett. 193, 108–114. https://doi.org/10.1016/j.patrec.2025.04.015 (2025).
Liu, C., Zhou, W., Chen, Y. & Lei, J. Asymmetric deeply fused network for detecting salient objects in rgb-d images. IEEE Signal Process. Lett. 27, 1620–1624. https://doi.org/10.1109/LSP.2020.3023349 (2020).
Zhang, Y., Xiao, Y., Zhang, Y. & Zhang, T. Video saliency prediction via single feature enhancement and temporal recurrence. Eng. Appl. Artif. Intell. 160, 111840 (2025).
Zhang, Y., Yu, P., Xiao, Y. & Wang, S. Pyramid-structured multi-scale transformer for efficient semi-supervised video object segmentation with adaptive fusion. Pattern Recognit. Lett. 194, 48–54. https://doi.org/10.1016/j.patrec.2025.04.027 (2025).
Ge, Z., Liu, S., Wang, F., Li, Z. & Sun, J. Yolox: Exceeding yolo series in 2021. arXiv:abs/2107.08430 (2021).
Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv:abs/2010.11929 (2020).
Xu, M. et al. Mitracker: Multi-view integration for visual object tracking. In 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 27176–27185, https://doi.org/10.1109/CVPR52734.2025.02531 (2025).
Sun, Y. et al. Joint spatio-temporal modeling for visual tracking. Knowledge-Based Syst. 283, 111206. https://doi.org/10.1016/j.knosys.2023.111206 (2024).
Xu, Y. et al. Transcenter: Transformers with dense representations for multiple-object tracking. IEEE Trans. Pattern Anal. Machine Intell. 45, 7820–7835. https://doi.org/10.1109/TPAMI.2022.3225078 (2023).
Xie, F. et al. Correlation-aware deep tracking. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 8741–8750, https://doi.org/10.1109/CVPR52688.2022.00855 (2022).
Liu, Z. et al. Swin transformer: Hierarchical vision transformer using shifted windows. In 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, 9992–10002, https://doi.org/10.1109/ICCV48922.2021.00986 (IEEE, 2021).
Peng, J. et al. Chained-tracker: Chaining paired attentive regression results for end-to-end joint multiple-object detection and tracking. In Vedaldi, A., Bischof, H., Brox, T. & Frahm, J. (eds.) Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part IV, vol. 12349 of Lecture Notes in Computer Science, 145–161, https://doi.org/10.1007/978-3-030-58548-8_9 (Springer, 2020).
Acknowledgements
Funds were received to cover the costs of open access publishing.
Funding
This work was supported by the Technology Project of Henan Province (232102240058).
Author information
Authors and Affiliations
Contributions
HC L conceived and designed the study. JW Q and ZG Z collected and analyzed the data, and was a major contributor in writing the manuscript. HY L, HT D, M Y, and SJ X are mainly responsible for presenting the data in the form of pictures and tables. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Liu, H., Qin, J., Zhang, Z. et al. VeTrack leverages transformer-based appearance modeling and confidence-guided multi-level association for robust multi-vehicle tracking. Sci Rep 16, 2673 (2026). https://doi.org/10.1038/s41598-025-32425-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-32425-9
