
Abstract
Loss of the Y chromosome (LOY) in peripheral blood mononuclear cells (PBMCs) is the most common somatic alteration in men and is associated with higher mortality from epithelial cancers1,2,3. In tumours, epithelial LOY is also associated with poor survival4,5,6,7. This raises several fundamental questions, such as why LOY in PBMCs drives cancer mortality and whether there is a relationship between LOY in PBMCs, PBMC-derived immune cells and cancer cells (and, if so, what its consequences are). We sought to answer these questions through a comprehensive pan-cancer analysis of bulk and single-cell RNA sequencing data from 29 human tumour types, along with autochthonous and syngeneic mouse models. In human and mouse tumours, malignant epithelial cells had the highest LOY prevalence, yet LOY was also present in tumour stromal and immune cells, with LOY in malignant epithelial cells predicting LOY in benign cells. LOY also correlated between paired tumour and PBMC samples from patients. Among benign cells, LOY induced the strongest shift in CD4+ and CD8+ T cells, with both showing transcriptomic signatures of immunosuppression. Furthermore, the magnitude of LOY in epithelial cells, CD4+ T cells and CD8+ T cells independently predicts survival, with tumours exhibiting concurrent epithelial and T cell LOY having the worst outcomes. Here we establish a model that links LOY in immune cells to LOY in malignant cells, which may explain in part why LOY in PBMCs is associated with increased cancer mortality.
Similar content being viewed by others

Main
LOY in tumour cells is associated with poor prognosis4,5,6. This was found to be partially due to immune evasion from T cell exhaustion in some tumour types7. LOY in PBMCs is the most common somatic alteration in healthy men and has been associated with increased risk8,9 and mortality from cancer1,2,3. As PBMCs consist of immune cells including lymphocytes (T cells, B cells and natural killer (NK) cells), monocytes and dendritic cells10, these data raise the question of whether LOY in PBMCs, PBMC-derived tumour immune cells and malignant cells are related, and whether this relationship drives increased cancer mortality.
Here we address this question through a comprehensive pan-cancer analysis of the genomic, histopathological, biological and clinical consequences of LOY in benign and malignant cells, using bulk and single-cell RNA sequencing (scRNA-seq) from human tumour types. Further, to gain additional insights that are difficult to obtain from human data and to generalize our findings, we also examine numerous data types from autochthonous, syngeneic and human xenograft models of cancer in mice.
Our data show that a substantial proportion of non-malignant cells, including both immune and non-immune cell subtypes in the tumour microenvironment (TME), have LOY. The presence of LOY in non-malignant cells is associated strongly with malignant epithelial cell LOY in human data and in mouse models. Furthermore, the proportion of LOY in PBMCs is correlated with that in immune cells and malignant cells in the TME. When present in benign cells, LOY induces the strongest phenotypic shift in CD4+ T and CD8+ T cells, with both cell types showing signs of immunosuppression. Clinically, the prognosis of patients with LOY epithelial tumours deteriorated further when LOY CD4+ T and CD8+ T cells were present in the TME, with tumour cells and T cells independently affecting prognosis.
Together, these findings document a relationship between LOY in PBMCs and in non-malignant and malignant cells in the TME. We also show that LOY in T cells in the TME can affect cancer mortality in patients. Given the prevalence of LOY in healthy older men, these findings may also have implications for tumour-infiltrating T cell (TIL) and chimeric antigen receptor (CAR) T cell therapies. More broadly, they lay the conceptual foundation for an experimentally tractable model that may explain in part why men with LOY in PBMCs are at higher risk for cancer death.
Tumour LOY and cohort characteristics
To investigate the impact of LOY at a pan-cancer level, we developed a ‘Y chromosome transcriptional signature’ (YchrS) that predicts DNA-based LOY classification (LOY/Y− (LOYDNA) versus wild type/Y+ (WTYDNA))5. Differential analysis of Y chromosome genes between LOYDNA and WTYDNA tumours from the Cancer Genome Atlas (TCGA) with available exome capture data identified 26 genes with lower expression in LOYDNA tumours, which we then filtered further using the Human Protein Atlas to focus on nine genes (DDX3Y, UTY, KDM5D, USP9Y, ZFY, RPS4Y1, TMSB4Y, EIF1AY and NLGN4Y) that are expressed stably at both the RNA and protein levels across several male tissues11 (Fig. 1a and Extended Data Fig. 1a).

a, Expression levels of 284 Y chromosome genes and clinical parameters in 4,127 tumours across 29 types, grouped by LOY status confirmed by DNA analysis5. Genes used to develop YchrS are indicated. b, YchrS score distribution across 29 cancer types (top) and corresponding proportions of LOYDNA and WTYDNA tumours (bottom). Box limits, quartiles; whiskers, data range within 1.5× interquartile range (dots, outliers); centre lines, median. Sample sizes: KIRP (kidney renal papillary cell carcinoma, n = 203), ESCA (oesophageal carcinoma, 115), KICH (37), LUSC (lung squamous cell carcinoma, 284), STAD (212), ACC (adrenocortical carcinoma, 28), PAAD (pancreatic adenocarcinoma, 92), HNSC (272), UVM (uveal melanoma, 44), CHOL (16), KIRC (kidney renal clear cell carcinoma, 316), DLBC (lymphoid neoplasm diffuse large B-cell lymphoma, 20), LUAD (lung adenocarcinoma, 183), READ (rectum adenocarcinoma, 63), COAD (colon adenocarcinoma, 155), BLCA (221), SKCM (skin cutaneous melanoma, 249), MESO (mesothelioma, 61), SARC (sarcoma, 85), LIHC (214), TGCT (testicular germ cell tumours, 120), LGG (brain lower grade glioma, 262), LAML (acute myeloid leukemia, 63), THCA (thyroid carcinoma, 127), PRAD (prostate adenocarcinoma, 457), GBM (glioblastoma multiforme, 89), THYM (thymoma, 58), PCPG (pheochromocytoma and paraganglioma, 73), BRCA (breast invasive carcinoma, 8). c, Area under the receiver operating characteristic curves comparison of YchrS and YwholeS in predicting LOYDNA and WTYDNA (AUC differences tested by two-sided roc.test in the pROC R package). d, YchrS score distribution by patient age group (years) (20–39, n = 423; 40–59, n = 1,475; 60–79, n = 1,994; older than 79, n = 194). Data are mean ± s.e.m.; two-sided Wilcoxon rank sum test. e, YchrS scores by ethnicity (white, n = 2,973; Asian, n = 289; Black or African American (Bl/AA), n = 236). Dots, individual patients; box presentation as in b. Two-sided Wilcoxon rank sum test. f, YchrS scores in HPV-negative (n = 168) versus HPV-positive (n = 27) patients with HNSC. Data presentation as in e. Two-sided Wilcoxon rank sum test. g, PCC of YchrS with CTA expression across 26 cancers. Bars and colours represent PCC in each cancer type; sizes represent −log10 adjusted P value, with darker edges denoting significance (P < 0.05). Pearson correlation test; Benjamini–Hochberg correction. h, Kaplan–Meier survival curves for OS and DSS, stratified by YchrS (LOYBR versus WTYBR). Statistics calculated using a univariate Cox proportional hazard model. CI, confidence interval. HPV, human papilloma virus; LOYBR/WTYBR, LOY/WTY sample by bulk RNA-seq; PCC, Pearson correlation coefficient.
Mean YchrS scores are anticorrelated with LOYDNA frequency across cancer types, and, compared with a signature including all Y chromosome genes (YwholeS), YchrS was more predictive of LOYDNA (area under the curve (AUC)) 0.98 versus 0.90; P < 0.01; Fig. 1b,c and Extended Data Fig. 1b). We further validated the YchrS signature using data from 778 male cell lines in the Cancer Cell Line Encyclopedia (CCLE), integrating YchrS with copy number alteration (CNA) data from whole-exome sequencing (WES). Cell lines were classified into LOYBR (LOY identified using bulk RNA-seq evaluation) and WTYBR (WTY chromosome identified using bulk RNA-seq evaluation) groups based on the mean YchrS value. Examining CNAs, we found LOYBR cell lines have extremely low average Y chromosome-specific CNAs compared with WTYBR lines, indicating there was prominent LOY in the former group (Extended Data Fig. 1c–e).
Next, we used TCGA data to examine whether YchrS was associated with any specific clinical characteristics (Supplementary Table 1). Patient age is correlated inversely with YchrS (Fig. 1d), and we also found significant racial differences in the degree of tumour LOY, with Black/African American patients having the lowest YchrS (Fig. 1e). There is also an inverse association between YchrS and smoking: in head and neck squamous cell carcinoma (HNSC) and kidney chromophobe renal cell carcinoma (KICH), patients who have never smoked exhibit significantly higher YchrS scores than current or former smokers (Extended Data Fig. 2a). Human papilloma virus (HPV)-positive patients with HNSC have higher YchrS scores than HPV-negative patients (Fig. 1f), but no association is observed between YchrS and hepatitis B virus (HBV) or hepatitis C virus (HCV) in liver hepatocellular carcinoma (LIHC), or between YchrS and Epstein–Barr virus (EBV) in stomach adenocarcinoma (STAD; Extended Data Fig. 2b). We found a strong negative correlation between the YchrS and cancer-testis antigen (CTA) signatures (Fig. 1g)—proteins that are normally restricted to germ cells but often overexpressed in cancers and linked to worse survival12.
We noted that the YchrS distribution appeared to be bimodal and that the mean served as a better separator of the two peaks while also performing better than the median in a receiver operating characteristic (ROC) analysis, with the mean falling closer to the top-left corner (Extended Data Fig. 2c,d). Given this, we next investigated whether mean YchrS could stratify patient outcomes. Indeed, patients with LOYBR have worse outcomes, including poorer overall survival (OS) and disease-specific survival (DSS; Fig. 1h and Supplementary Table 2). When analysing TCGA data, we found that the YchrS signature effectively stratifies pan-cancer survival outcomes in white and Asian patients (Extended Data Fig. 2e). However, this stratification was not significant in Black patients (Extended Data Fig. 2e). Similarly, at the genetic ancestry13,14 level, the YchrS signature stratifies pan-cancer survival in European, African-admixed and East Asian patients, but not in African patients (Extended Data Fig. 2f). Moreover, a multivariate Cox proportional hazards analysis found that the WTYBR/LOYBR classification is independent from genetic ancestry, self-reported race and tumour type in predicting OS, suggesting that it has a foundational role in cancer outcomes (Extended Data Table 1). Finally, we also found that higher expression of each of the nine YchrS genes predicted better OS and DSS in TCGA data (Extended Data Fig. 2g,h).
Cancer cell LOY drives tumour aggression
To investigate why men with tumour LOY have worse survival1,4,5,7, we examined genomic and transcriptional signatures in TCGA tumours based on their LOYBR classification (Supplementary Table 3). Tumour mutation burden (TMB) and tumour neoantigen burden (TNB) are associated with worse survival without immunotherapy but better immune checkpoint blockade (ICB) response15,16,17,18. We found that LOYBR tumours have elevated TMB and TNB at both the small insertion/deletion mutation (Indel) and single nucleotide variant (SNV) levels, as well as higher mutation rates (both non-silent and silent mutations; Extended Data Fig. 3a). YchrS scores are also correlated inversely with aneuploidy and ‘fraction altered’ across several cancers (Extended Data Fig. 3b). Moreover, homologous recombination defects (HRD, including in HRD score19, loss of heterozygosity (LOH)20, large-scale state transitions21 and telomeric allelic imbalance (TAI)22) are higher in LOYBR tumours (Extended Data Fig. 3c). LOYBR tumours also have higher signature scores for homologous recombination, mismatch repair, DNA damage response and DNA repair.
In terms of phenotype, LOYBR tumours have higher stemness signature scores, encompassing DNA methylation-based stemness, epigenetically regulated DNA methylation-based stemness, differentially methylated probe-based stemness and enhancer element methylation-based stemness23 (Extended Data Fig. 3d). LOYBR tumours also have higher signature scores for proliferation and activation of proliferation-related pathways, including DNA replication, cell cycle regulation, mitotic spindle, KRAS signalling, G2M checkpoint, E2F targets and apoptosis. They also have higher scores for oncogenesis-related pathways such as MYC, MTORC1 and epithelial-mesenchymal transition (EMT; Extended Data Fig. 3d). However, on the basis of gene expression, they demonstrate decreased activity of the Hedgehog signalling pathway.
Beyond the pathways listed above, LOYBR tumours have elevated angiogenesis, glycolysis and hypoxia pathway scores, suggesting a distinct TME (Extended Data Fig. 3e,f). Furthermore, they display diminished androgen response and elevated oestrogen response scores (Extended Data Fig. 3g). Finally, LOYBR tumours have increased expression of immune checkpoints and co-inhibitory genes such as CTLA4, PDCD1, TIGIT, LAG3, CD27, IL2RA, HAVCR2, CD40, CD274 and PDCD1LG2 (Extended Data Fig. 3h), indicating they have an immunosuppressive TME.
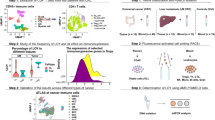
To study the implications of LOY at the cell-type level, we consolidated scRNA-seq data from 17 epithelial cancer types (Fig. 2a, Extended Data Fig. 4a–d and Supplementary Table 4). Because we found that YchrS often misclassified low-RNA-count cells as having LOY, we developed a machine-learning model to predict single-cell-level LOY or WT status in scRNA-seq data (LOYSCR and WTYSCR), by training a Random Forest model to predict male versus female cells from adjacent normal scRNA-seq samples using expression levels of the nine YchrS genes (Fig. 2b and Extended Data Fig. 5a–c). When the model was used to classify male tumour cells, those predicted to have LOY had minimal expression of Y chromosome genes, but had normal overall sequencing counts, and had normal expression of genes not known to be affected by LOY such as GAPDH, Y gene paralogues on the X chromosome and genes located on other chromosomes (Fig. 2c and Extended Data Fig. 5d–f). To further validate model accuracy, we analysed a colorectal cancer (CRC) dataset24 comprised of 23 tumours with paired WES, bulk RNA-seq and scRNA-seq data. Here we found a strong positive correlation between average Y chromosome CNA (WES) and YchrS scores (bulk RNA), and negative correlations between LOYSCR cell proportions and the former two measures (Extended Data Fig. 5g).

a, scRNA-seq database constituted by 497,055 cells from 105 male tumour samples, coloured by six principal cell types (left) and 12 cancer types (right). b, LOYSCR predictions for cells in a. c, Mean expression (colour) and percentage of expressing cells (size) for the nine Y chromosome genes used in the Random Forest model, their X chromosome paralogues and GAPDH across different cell types and LOYSCR status. Paralogue gene pairs share colours. d, Database of 157,029 male epithelial cells, coloured by cancer type. e, Normalized enrichment scores (NES) for the top five upregulated and 15 downregulated pathways in LOYSCR versus WTYSCR epithelial cells, categorized into four functional groups. Bar colour denotes −log10-adjusted P value, calculated by gseGO in the clusterProfiler package. f, Glycolysis (left) and hypoxia (right) signatures in LOYSCR (n = 73,576) versus WTYSCR (n = 83,453) epithelial cells. Data are mean ± s.e.m.; two-sided Wilcoxon rank sum tests. g, MHC class I gene expression in LOYSCR versus WTYSCR epithelial cells. Dot plot (bottom) presentation as in c. Bars (top) show log2FC, with colours indicating −log10-adjusted P value, calculated with sc.tl.rank_genes_group in the scanpy package using two‐sided Wilcoxon rank‐sum test with Benjamini–Hochberg correction. h,i, Scores for proliferation-related (h) and genomic instability-related (i) pathways in LOYSCR versus WTYSCR epithelial cells. Dot colour represents mean scaled pathway score; dot size represents −log10 P value (two-sided Wilcoxon rank sum tests, Benjamini–Hochberg correction). j, GSEA pathway enrichment analysis of CRISPR Y-KO and CRISPR Y-Scr MB49 cells. NES > 0 indicates pathway enrichment in Y-KO cells. Statistics calculated as in e. k, Expression of genes related to genomic instability, cell cycle and antigen presentation in CRISPR Y-Scr (n = 3) and CRISPR Y-KO (n = 3) cells. Dots, replicates (mean ± s.e.m.); Student’s t-tests. BER, base excision repair; HDR, homology-directed repair; NER, nucleotide excision repair; NHEJ, non-homologous DNA end joining.
Gene set enrichment analysis (GSEA) revealed that epithelial cells (Fig. 2d) with LOYSCR downregulate pathways associated with immune recognition (major histocompatibility complex (MHC)), aerobic energy metabolism (regulation of aerobic respiration, aerobic electron transport chain, mitochondrial ATP synthesis coupled electron transport, ATP synthesis coupled electron transport) and pathways related to protein synthesis (ribosomal large subunit biogenesis, cytoplasmic translation; Fig. 2e and Supplementary Table 5). LOYSCR epithelial cells also upregulate pathways associated with glycolysis (glycolytic process through fructose-6-phosphate and glucose catabolic process) and hypoxia, altogether indicating a metabolic shift consistent with tumorigenesis and progression25,26 (Fig. 2f). Finally, LOYSCR epithelial cells also have lowered expression of specific MHC class I and MHC class II genes (Fig. 2g and Extended Data Fig. 6a), indicating that these cells may have immune evasion capabilities27,28.
In terms of oncogenic pathway signature expression, LOYSCR epithelial cells have elevated KRAS, MYC, RAS, TGFβ and oestrogen response activity (Extended Data Fig. 6b). They also display upregulation of proliferation-related pathways, such as the cell cycle, DNA replication, mitotic spindle formation and the G2M checkpoint (Fig. 2h). As for genomic instability, LOYSCR epithelial cells express high levels of signatures corresponding to repair of double-strand breaks (DSB) through homologous recombination, non-homologous end joining and the p53 pathway (Fig. 2i). A signature of repair of single-strand breaks (SSB) via mismatch repair was also increased, while base excision repair and nucleotide excision repair pathways show less pronounced changes. Inferred copy number variation (inferCNV) analysis also indicated elevated CNAs in LOYSCR epithelial cells, particularly those from bladder cancers (BLCA) and cholangiocarcinoma (CHOL) (Extended Data Fig. 6c,d).
To develop a mouse model to study LOY mechanistically, we performed RNA-seq on fluorescence-activated cell sorting (FACS)-isolated CD45− cells from tumours generated by subcutaneous injection of CRISPR induced Y-KO (confirmed by WES to have lost the Y chromosome) (Extended Data Fig. 7a) or control cells that were infected with a scrambled CRISPR guide (Y-Scr). Excluding Y-linked genes to prevent bias, we identified LOY-associated changes through differential expression analysis (Supplementary Table 6). A LOY phenotype score, calculated by comparing scaled signature scores of genes that were upregulated or downregulated between Y-KO and Y-Scr CD45− tumour fractions, was higher in LOYBR BLCA samples than in WTYBR BLCA samples in the TCGA (Extended Data Fig. 7b), confirming the relevance of our mouse model findings. The LOY signature was also higher in LOYBR tumours from other cancer types (Extended Data Fig. 7c).
To study the genes altered in LOY cancer cells, we used in vitro7 RNA-seq data on MB49 cells with CRISPR–Cas9-mediated selective elimination of the Y chromosome (Y-KO). GSEA pathway enrichment analysis of the Y-KO and Y-Scr in vitro RNA-seq data indicated that the former cells have increased genomic instability (DSB repair) and cell cycle regulation and reduced antigen presentation (Fig. 2j and Extended Data Fig. 7d,e) compared with Y-Scr cells. Specifically, key DNA repair genes are overexpressed in Y-KO cells (Fig. 2k), including Brca1 (homologous recombination for DSB repair), Atm (DSB repair), Msh2 (mismatch repair) and Tert (DNA repair and telomere maintenance). Genes that regulate chromosome segregation, such as Bub1b, Aurkb, Ccnb1 and Plk1, are also upregulated in Y-KO cells. Furthermore, cell cycle regulation-related genes (Cdk2, Ccna2, Ccnb1, Ccnd1, Mki67) show upregulation, whereas antigen-presentation genes (H2-D1, B2m) show downregulation (Fig. 2k). Finally, WES revealed higher numbers of large-scale chromosomal alterations in Y-KO cells. These include unique single-nucleotide polymorphisms (SNPs) and indels, which appear preferentially enriched in intronic and intergenic regions, suggesting that LOY may predispose cells to widespread genomic alterations rather than targeting specific genomic loci (Extended Data Fig. 7f–h).
LOY in cancer and benign cells correlate
In studying LOYSCR cell percentages in human scRNA-seq data, we noticed that, whereas LOYSCR frequency is the highest in epithelial cells, other cell types also show significant LOYSCR (Fig. 3a; top). This finding was supported when we examined a signature (YchrSmus) representing Y mouse chromosome genes (Ddx3y, Uty, Kdm5d and Usp9y) in scRNA-seq data from autochthonous mouse bladder tumours generated with the N-butyl-N-(4-hydroxybutyl)-nitrosamine (BBN) carcinogen protocol29,30 (Fig.3a (bottom) and Extended Data Fig. 8a–d). To determine whether there was a relationship between epithelial LOY and the prevalence of LOY in non-epithelial cells in the same tumour, we measured correlations of LOYSCR cell proportions between different cell types. Including all tumour types in our human scRNA-seq dataset, we found that the rates of LOYSCR in any one cell type are highly predictive of LOYSCR rates in other cells (Fig. 3b).

a, LOYSCR and WTYSCR cell proportions across principal cell populations in human tumours (top) and mouse bladder tumours induced by BBN (bottom). b, Correlation of cell group proportions across human tumours, defined by cell type and LOYSCR status. Cell type proportions across samples are shown in yellow (x axis, left; y axis, top), while LOYSCR cell proportions are in blue (x axis, right; y axis, bottom). Within groups, cell types are ordered alphabetically. c, Proportion of Y chromosome signal-positive nuclei per tissue core (FISH experiment), categorized by CD45 status. Data are presented as mean ± s.e.m., normalized to the normal male Y chromosome signal. Values <0 or >1 arise from normalization and do not reflect absolute signal levels. d, Y chromosome gene (Kdm5d, Uty, Eif2s3y, Ddx3y) DNA levels in each cell line before injection, confirming LOY status. Data are mean ± s.e.m.; dots, biological and technical replicates. e, DNA qPCR analysis of Y chromosome genes in immune cells (CD45+) across MB49 WTY (Y+), MB49 LOY (Y−) and MB49 clone 5 (C.5) groups. Y+, n = 8; Y−, n = 15 for Kdm5d and n = 12 for other genes; MB49 C.5, n = 10. Data are mean ± s.e.m. Two-sided Wilcoxon rank sum tests. n = total number of all the technical duplicates obtained from all the samples used for the assay. f, DNA qPCR analysis of Y chromosome genes in epithelial (CD45−, TdTomato+, left) and immune cells (CD45+, right) from CRISPR Y-Scr and CRISPR Y-KO groups. For CD45− Y‐Scr, n = 3; Y‐KO, n = 6. For CD45+ Y‐Scr, n = 7; Y‐KO, n = 27 (Kdm5d) and n = 24 (other genes). Data are mean ± s.e.m. Two-sided Wilcoxon rank sum tests. n = total number of all the technical triplicates obtained from all the samples used for the assay. g, Genomic DNA qPCR was performed to assess Y chromosome genes (Kdm5d, Uty, Ssty1, Ssty2) in CD3+ T cells from PBMCs of mice bearing CRISPR Y-Scr or CRISPR Y-KO tumours. Fold change (FC) was calculated relative to the average in vivo values and normalized to both endogenous controls separately. Purple dots, normalization to Gapdh; yellow dots, normalization to Actb. Each dot denotes pooled samples from six independent tumours. Data are mean ± s.e.m. Two-sided Wilcoxon rank sum tests.
We also used the inferCNV algorithm on the human scRNA-seq data to assess whether non-malignant cells in the TME, particularly macrophages, display tumour-like copy number variation (CNV) signatures, which could indicate the presence of ambient or phagocytosed nucleic acids from malignant cells. Epithelial cells displayed elevated CNV scores, confirming their distinct genomic profiles, whereas all examined immune cell types, including macrophages, CD8+ T cells and CD4+ T cells, showed minimal CNV signals (Extended Data Fig. 8e,f). These findings suggest that the LOY signals of benign cells are unlikely to be the result of debris from malignant cells. This also indicates that the YchrS scores used in the survival curves above (Fig. 1h) and DNA-based LOY evaluations5 used to assess malignant cell LOY may reflect the overall LOY levels from a variety of cell types within the TME and not just cancer cells.
Next, we analysed orthogonal datasets to test for evidence of LOY in benign cells. scRNA-seq data on mouse BLCA (MB49) LOY tumours and normal bladder samples from male and female C57BL/6N mice as controls31 revealed that benign cell types within LOY tumours display higher LOY levels compared with normal bladders (Extended Data Fig. 9a). Furthermore, scRNA-seq or single-nucleus RNA sequencing of CD45+ and CD45− sorted mouse hepatocellular carcinoma (HCC) tumour populations indicate that LOY is present in both malignant cells and immune cells whose sequencing libraries were prepared separately from the malignant cell fraction (Extended Data Fig. 9b,c). We also analysed available human scRNA-seq data from CD45-based FACS-sorted HNSC32, CHOL33 and BLCA34 samples (Supplementary Table 7), which revealed that the CD45+ (immune) populations exhibit LOY (Extended Data Fig. 9d). Notably, we also observed a positive correlation between LOY proportions in CD45− and CD45+ cells from the same patients in these data (Extended Data Fig. 9e). scRNA-seq data from a CRC xenograft model35, in which human LOY CRC cells were subcutaneously injected into immunocompromised mice, also displayed higher LOY levels in benign mouse cells in the TME compared with corresponding cells from normal male mouse tissues (Extended Data Fig. 9f). Further, on intact tissue sections, we combined a clinical grade fluorescence in situ hybridization (FISH) assay used for prenatal sex determination with CD45 immunohistochemistry (IHC) to examine LOY in 33 BLCA specimens and found that both CD45− and CD45+ cells in cancer samples exhibit LOY (Fig. 3c and Extended Data Fig. 9g).
As a final validation that stromal and immune cells in the TME display LOY, and to better investigate whether malignant cell LOY promotes LOY in benign populations, we injected lineage-related Y+ and LOY MB49 mouse BLCA cells subcutaneously into C57Bl/6N mice. We used three models for this experiment: (1) naturally occurring Y+ and LOY cells7; (2) a LOY clonal line; and (3) CRISPR Y-KO and CRISPR Y-Scr cells7. For each model, the DNA levels of four Y chromosome genes (Kdm5d, Uty, Eif2s3y and Ddx3y) were assessed, before subcutaneous injection of the cells into immune-competent mice (Fig. 3d). After formation, tumours were then disrupted mechanically, and cells separated on the basis of surface CD45 expression using double selection by magnetic beads and FACS (Supplementary Fig. 1). As the genetically engineered Y-KO and Y-Scr lines co-express a TdTomato fluorescent marker and the Cas9 gene, we also sorted these cells by TdTomato expression to minimize epithelial cell contamination in the immune cell fractions. We then used DNA qPCR to detect the Cas9 gene in each sorted population, confirming the purity of the different compartments (Extended Data Fig. 10a,b). As expected, only the TdTomato+ epithelial cells showed a high copy number of Cas9, whereas the immune compartments exhibited negligible Cas9 levels, indicating successful separation (Extended Data Fig. 10a,b). Next, the four Y chromosome genes used to validate LOY above were analysed via DNA qPCR to assess their presence in CD45+ immune and CD45− non-immune cell populations. There were lower DNA levels of Y chromosome genes in the CD45+ cells from tumours generated by LOY MB49 cells compared with those generated with Y+ lines (Fig. 3e,f). Furthermore, when this experiment was repeated with a sorting strategy that allowed T cell LOY to be examined specifically (CD45+CD11b−B220−CD3+TCRb+), we found that infiltrating CD3+TCRb+ T cells in Y-KO tumours had increased LOY compared with those from Y-Scr tumours (Extended Data Fig. 10c). However, no evidence of LOY was found in PBMCs from mice bearing Y+ or LOY tumours (Fig. 3g).
Cancer cell LOY correlates with PBMC LOY
Given the incidence of LOY in PBMCs and its relationship to increased cancer mortality1, other key questions remain, such as how LOY levels in human PBMCs compare with those in tumour-infiltrating immune cells. If the latter exhibit higher LOY levels than PBMCs, that would suggest either preferential accumulation of PBMCs with LOY into tumours or tumour-induced LOY in Y+ PBMCs that have infiltrated the tumour. To begin answering this question, we examined a dataset from patients with renal cell carcinoma (RCC)36 that included tumour and PBMC samples from the same patients. Our analysis indicated that T cells and myeloid cells in tumours exhibit significantly higher LOY proportions than their matched PBMC counterparts (Fig. 4a). In both the above and one additional HNSC dataset37,38 on CD45-sorted tumour cells and matched PBMCs, we confirmed that LOY proportions were correlated in the tumour and blood (Fig. 4b–d). We also analysed specific immune cell subtypes and found that tumour immune cells, especially T and B cells, had significantly higher LOY proportions than PBMCs (Fig. 4e). To put the mouse data in context, PBMCs from mice treated with the BBN protocol showed no evidence of LOY (Extended Data Fig. 10d).

a, LOYSCR cell proportions across different immune cell types in paired tumour and blood samples from seven patients with RCC. Each dot represents one patient. Paired Wilcoxon rank sum test was used for comparing the LOY proportions of specific cell types from tumour and blood samples, with sample pairs shown at the bottom right of each plot. b, Database of 79,858 cells from 19 patients with HNSC, coloured by five principal cell types. No cluster of epithelial cells was observed. c, LOYSCR and WTYSCR cell proportions of paired TIL and PBMC samples from patients in b. d, LOYSCR cell proportions in matched TIL and PBMC samples from patients in b; each dot represents an individual patient. e, LOYSCR cell proportions in different immune cell types in paired TIL and PBMC samples from 19 patients in b; each dot represents one patient. Paired Wilcoxon rank sum test was used to compare the LOY proportions of specific cell types from TIL and PBMC samples, with sample pairs shown at the bottom right of each plot. B, blood sample; T, tumour sample.
Cancer cell LOY affects benign TME cells
To examine the molecular profiles associated with LOY in non-epithelial cell populations in the TME, we conducted a cell-type-specific differential expression and pathway analysis (Fig. 5a–e and Supplementary Table 8). GSEA using the Gene Ontology database (https://www.geneontology.org/) found that LOY has the greatest impact on CD8+ and CD4+ T cells (Fig. 5a). LOYSCR CD4+ T cells have elevated expression of several immune checkpoint and co-stimulatory molecules (for example, IL2RA, HAVCR2, ICOS, TNFRSF9, TNFRSF4, CTLA4 and TIGIT (Fig. 5b)) as well as increased expression of signatures of exhaustion and the T regulatory (Treg) cell phenotype (Fig. 5c), while displaying lower expression of CD4+ T cell specific signatures of naive and T cell receptor (TCR) signalling. Conversely, LOYSCR CD8+ T cells show reduced expression of HAVCR2, BTLA, TNFRSF9, LAG3, CTLA4, PDCD1, TIGIT, ITGB2 and TOX, as well as signatures of cytotoxicity, TCR signalling and exhaustion (Fig. 5d,e). LOYSCR CD8+ T cells also increase expression of a naive CD8+ T cell signature, indicating these cells are not contributing to an active anti-tumour immune reaction.

a, Summary of GSEA analysis between LOYSCR and WTYSCR cells across cell types. Colours represent NES of differentially expressed pathways (adjusted P < 0.05 in any one cell type), calculated by gseGO in the clusterProfiler package. b, Immune checkpoint gene expression in LOYSCR and WTYSCR CD4+ T cells. Dot colour represents mean scaled gene expression; dot size indicates the fraction of expressing cells. Bars above plots show log2FC, coloured by −log10 P value, calculated with sc.tl.rank_genes_group in the scanpy package using two‐sided Wilcoxon rank‐sum test with Benjamini–Hochberg correction. c, Scaled signatures scores of functional pathways in LOYSCR (n = 12,802) and WTYSCR (n = 49,206) CD4+ T cells. Data are mean ± s.e.m.; significance determined via two-sided Wilcoxon rank sum tests. d, Immune checkpoint gene expression in LOYSCR and WTYSCR CD8+ T cells. Data presentation as in b. e, Scaled signatures scores of functional pathways in LOYSCR (n = 19,159) and WTYSCR (n = 69,767) CD8+ T cells. Data presentation as in c. f, Kaplan–Meier survival curves for 4,127 TCGA male samples, stratified by LOYSCR and WTYSCR signature scores from CD4+ T cells, CD8+ T cells and epithelial cells. Statistics (P values, hazard ratio, CI) were calculated using a univariate Cox proportional hazards model. g, Kaplan–Meier survival curves for TCGA male samples based on combinatorial scores of LOYSCR epithelial and CD4+ or CD8+ T cell signatures. P values for pairwise comparisons through log-rank tests are shown at the bottom. h, Nomogram predicting less than 2-year, less than 5-year and less than 8-year OS probabilities based on LOYSCR CD8+ T cell, CD4+ T cell, epithelial signature score levels and age. Bottom, cumulative scores and survival estimates. Example: TCGA-02-2483 (43-year-old, high LOYSCR epithelial/CD8+ score, low CD4+ score) with a total score of 223, predicting 15% (less than 2 years), 28.6% (less than 5 years) and 39.1% (less than 8 years) mortality risk.
To further explore the relationship between T cell LOY and T cell exhaustion, we conducted in vitro experiments in which mouse primary T cells were subjected to prolonged activation with anti-CD3 and anti-CD28 coated plates over a 3-week period. Although LOY was not observed in T cells after extended culture and stimulation, markers of exhaustion such as Pdcd1, Tim3 and Ctla4 were induced, whereas the naive T cell marker Tcf7 was reduced as expected (Extended Data Fig. 10e–g). This indicates that chronic activation in vitro alone does not drive LOY in T cells. In addition, we also analysed publicly available transcriptomic datasets from Giles et al.39, in which gp33-specific CD8+ T cells from TCR-transgenic mice were subjected to acute (LCMV Armstrong) and chronic (LCMV Clone 13) LCMV infections. Over the course of the infection, T cells in the chronic model exhibited upregulation of canonical exhaustion markers such as Tox, Pdcd1 and Ctla4 and downregulation of Tcf7 (Extended Data Fig. 10h). As in the previous experiment, expression levels of Y-linked genes (Uty, Kdm5d, Ddx3y, Usp9y) remained unchanged in exhausted T cells compared with their non-exhausted counterparts, indicating that chronic activation alone does not drive LOY in T cells (Extended Data Fig. 10i).
LOY in tumour and T cells worsens survival
Given that CD4+ T cells and CD8+ T cells are the benign TME cells most affected by LOY (Fig. 5a), we further examined their role in patient prognosis and whether combined loss of the Y chromosome in epithelial cells and in these immune cell types may have clinical implications. To this end, we developed cell-type-specific LOYSCR and WTYSCR gene signatures and conducted Kaplan–Meier survival analysis using TCGA data (Supplementary Table 9). This analysis suggests that LOYSCR CD4+ T cells, CD8+ T cells and epithelial cells are associated with patient survival outcomes, including OS and DSS (Fig. 5f and Extended Data Fig. 11a). Specifically, LOYSCR epithelial cell, CD4+ T cell and CD8+ T cell signature expression levels emerged as risk factors, whereas WTYSCR epithelial cell, CD4+ T cell and CD8+ T cell signature expression levels were identified as protective. Moreover, patients with high predicted levels of LOY epithelial cells in conjunction with elevated predicted levels of LOY CD4+ T or CD8+ T cells have the poorest survival outcomes, whereas those with low predicted levels of LOY epithelial and T cells show the most favourable survival (Fig. 5g).
To validate the findings above, we analysed a publicly available liver cancer scRNA-seq dataset that includes 94 male patients with matched survival data40. By calculating the proportions of LOYSCR epithelial, CD4+ and CD8+ T cells in each sample and correlating these proportions with long-term outcomes, we find patients with co-existent high proportions of LOYSCR in epithelial cells and in CD8+ or CD4+ T cells have the worst survival outcomes compared with patients with co-existent low proportions of LOYSCR in all cell types (Extended Data Fig. 11b,c). Patients with co-existent high epithelial and CD8+ T cell LOYSCR show worse outcomes than patients with high epithelial cell LOYSCR alone. This pattern was consistent with our bulk pan-cancer RNA-seq findings, reinforcing the link between LOYSCR epithelial and T cells and poor patient prognosis in cancer (Extended Data Fig. 11b,c).
We next conducted a multivariate Cox analysis to determine whether the LOYSCR epithelial, LOYSCR CD8+ T cell, and LOYSCR CD4+ T cell signatures independently contribute to patient outcomes. Owing to the unavailability of tumour stage, smoking and race-related data for certain cancer types, and recognizing the previously published correlation between age and LOY, only age was included in our analysis. As the LOYSCR epithelial signature shows non-linearity, we categorized patients into low or high LOYSCR epithelial, CD8+ T cell or CD4+ T cell signature groups, based on corresponding cut-offs determined from the Kaplan–Meier plot analysis above (Fig. 5f), where we observed that all variables are independent risk factors for poor OS (Extended Data Table 2).
Finally, we constructed a nomogram that incorporates age, as well as LOYSCR signature scores for epithelial, CD4+ and CD8+ T cells to provide ‘proof of principle’ for a potentially clinically beneficial tool that could forecast survival rates among patients with cancer (Fig. 5h). Each patient is assigned a score corresponding to each prognostic parameter, wherein a higher total score indicated a poorer prognosis for the patient. The nomogram offers three distinct probability scales for predicting mortality, in less than 2 years, 5 years or 8 years. Additionally, calibration plots demonstrated that the performance of the nomogram closely resembles that of an ideal model (Extended Data Fig. 11d).
Discussion
LOY in a portion of PBMCs is associated with increased risk of death from many cancer types1,2,3. This is particularly interesting because PBMCs comprise key immune cells such as T cells and B cells, monocytes/macrophages, NK cells and others that form part of the TME10. Several possible models could explain how this happens. For example, LOY in PBMCs may be a marker of genome damage due to environment (smoking, carcinogens and so on) or aging41, with such damage driving both LOY and tumour progression in the malignant cells. This latter notion is supported by the finding that LOY in tumours is associated with poor prognosis4,5,6,7. It is also possible that LOY in PBMCs, and thus in key immune cells, may cause these cells to be less competent in restricting tumour growth. There is a paucity of evidence to support any of these models. Our study extends previous findings that LOY contributes to immune evasion, tumour growth and poorer survival in BLCA1,5,7 to a pan-cancer context. Our WES findings revealed that LOY cells harbour a higher burden of large-scale chromosomal alterations compared with WTY cells. This observation supports a model in which LOY could impair genomic maintenance systems, leading to a ‘vicious cycle’ of escalating chromosomal aberrations.
Our work found significant LOY in benign cells in the TME and that the prevalence of LOY in malignant epithelial cells is predictive of LOY in other cell types within the same tumour. Speculatively, if LOY tumour cells express specific chemokines, cytokines or adhesion molecules that preferentially attract LOY immune cells, this would explain how a relatively small percentage of PBMCs with LOY can have an impact on cancer death1,2,3. We also show evidence for another possible mechanism to explain this correlation, namely the ability of LOY epithelial cells to induce LOY in benign cells, including T cells. One mechanism underlying such a phenomenon could involve tumour-derived extracellular vehicles42 containing pro-inflammatory or genome-altering cargo transferred from LOY cancer cells that stimulate molecular changes leading to LOY in neighbouring benign cells. Notably, the ‘preferential attraction’ and ‘induction’ models are not mutually exclusive and could be operating in the same tumour.
One consequence of LOY in T cells is a prominent increase in the Treg signature in CD4+ T cells. Treg cells are characterized by their immunosuppressive properties43. Our analysis also revealed that LOY CD8+ T cells exhibit decreased activation, TCR-signalling and cytotoxicity signatures, indicating reduced contribution to an immune response. These findings allow us to posit a speculative model in whichk tumours with high LOY are more aggressive owing to increased levels of dysfunctional LOY T cells and enrichment of LOY Treg cells. Finding LOY in T cells has also potentially important implications for TIL and CAR-T cell therapy in patients with cancer44,45. Given the features of LOY CD8+ T cells compared with those without this change, enrichment or selection of cells for such engineering without knowing their Y chromosome status may lead to variable clinical efficacy and confound clinical trial outcomes. This caveat would be particularly relevant in tumours with high levels of epithelial LOY, which have a proportionately high T cell LOY. This possible dual role of LOY, driving both genomic instability in tumour cells and functional exhaustion in immune cells, provides a plausible explanation for its association with shortened survival.
Our study has several limitations. There is an absence of relevant scRNA-seq data for certain tumour types, primarily because of incomplete gender information or quality control issues. Related to this, we were able to identify only one scRNA-seq dataset in which there were enough male patients with long-term follow up to allow analysis of the consequences of combinatorial LOY in epithelial and T cell compartments. Thus, we had to use bulk RNA-seq deconvolution based on cell-type-specific signatures of LOY to perform this analysis in a pan-cancer manner. Also, the nomogram that was developed here needs thorough validation on additional datasets and in specific tumour types. Although our RNA-seq analyses reveal significant changes in gene expression and pathway enrichment, it is important to recognize that these findings are correlative. Functional assays are essential to establish causative relationships between LOY and the observed biological processes. Laboratory experiments are also needed to substantiate the observed associations, particularly concerning the mechanisms by which interactions between epithelial cancer cells with LOY and benign cells in the TME lead to LOY in the latter.
In summary, our research lays a new conceptual framework that will serve to accelerate the nascent field of Y chromosome-focused cancer research. These results provide new insights such as showing the profound impact of epithelial LOY on reshaping the TME, the prevalence of LOY in various benign cell types in a tumour, the ability of LOY epithelial cells to promote LOY in benign cells (including T cells) and the consequences of LOY in benign cells. Finally, our study provides evidence that LOY in both epithelial and non-epithelial cells are independent prognostic markers of outcomes, demonstrating the impact of multicellular LOY in cancer.
Methods
TCGA data acquisition and processing
In this study, we used bulk RNA-seq, WES somatic mutation data, and clinical data (Supplementary Table 1) sourced from TCGA project (https://portal.gdc.cancer.gov/). The data matrices obtained from UCSC Xena (https://xena.ucsc.edu/) have been standardized, normalized and corrected for batch effects and platform differences. Additionally, mutation data generated by the PanCancer Atlas consortium (https://gdc.cancer.gov/about-data/publications/pancanatlas) were incorporated. A total of 29 tumour types and 4,127 male participants were included in our analysis. Survival outcome metrics, including OS, OS time, DSS and DSS time were calculated as in Liu et al.46 (Supplementary Table 2).
Classification of LOY based on transcriptome data
We used the DESeq2 R package (v.1.42.1) to uncover Y chromosome gene expression differences between LOYDNA and WTYDNA47. Differentially expressed genes were called on the basis of a log2FC cut-off of −1 and a −log10-adjusted P value cut-off of 200. This gene set resulted in the LOY prediction signature. Subsequently, we conducted a gene set intersection analysis with a gene set in the male-specific region of the Y chromosome seen expressed across 24 human tissues. This analysis required that genes exceeded 0.1 reads per kilobase of transcript per million reads mapped per tissue or that they had presence in IHC data from the Human Protein Atlas RNA-seq11. This approach identified nine signature genes making up our Y chromosome signature (YchrS): DDX3Y, UTY, KDM5D, USP9Y, ZFY, RPS4Y1, TMSB4Y, EIF1AY and NLGN4Y. Based on single-sample GSEA (ssGSEA)48 conducted with the GSVA49 R package (v.1.44.5), we observed that patients with low levels of YchrS exhibited characteristics similar to those of people with LOYDNA, whereas those with high YchrS levels resembled people with an intact Y chromosome (WTYDNA). We partitioned all patients into low YchrS group (LOYBR) and high YchrS group (WTYBR) with a mean value cut-off. Additionally, a similar approach was applied to analyse the Ywhole signature (YwholeS), using a signature comprising all Y chromosome genes.
YchrS validation by using CCLE data
To validate the nine-gene Ychr Signature (YchrS), we downloaded the batch-corrected transcriptomic data and corresponding CNA data for 778 male cancer cell lines from the CCLE project (https://depmap.org/portal/ccle/). YchrS was calculated by the same method as for TCGA data. Cell lines with a YchrS lower than the mean value were categorized as LOYBR, otherwise they were called WTYBR. Average CNA for chromosome i in each cell line was calculated using the following formula to evaluate its integrity:
n is the total number of segments in chromosome i.
Genetic ancestry
Consensus ancestry for TCGA cases was obtained from ref. 14, determined by combining ancestry inference from five independent classification methods using SNP array and/or WES data. Only ancestries with more than 50 patients were included in the survival analysis, which spanned 3,893 patients: European (n = 3,319), East Asian (n = 286), African (n = 190) and African-admixed (n = 98).
Genomic instability and stemness features
Aneuploidy scores for TCGA cases were obtained from ref. 50. Arm-level statistics were calculated using the GISTIC (v.2.0)51 copy number significance software. These scores were derived by tallying the total number of amplified or deleted arms, collectively termed ‘altered’. Samples were initially categorized by tumour type, alteration type (amplification or deletion) and chromosome arm. Subsequently, samples were clustered on the basis of specific arm attributes, and arms were classified as altered if part of a cluster had a mean fraction altered of at least 80%. Intratumour heterogeneity used to generate DNA damage scores was determined by ABSOLUTE52. ABSOLUTE analysed segmentation data from Affymetrix SNP6.0 arrays and variant calls from the MC3 variant file.
We used two measures to assess HRD. The first was derived by Knijnenburg et al.53 and quantifies HRD by aggregating separate metrics of genomic scarring: large (more than 15 Mb) non-arm-level regions with LOH20, large-scale state transitions (breaks between adjacent segments of greater than 10 Mb, LST21 and subtelomeric regions with allelic imbalance. The second measure, introduced by Telli et al.19, incorporates LOH and TAI22. The HRD score for samples analysed via custom hybridization sequencing assay were computed using reads covering SNP positions54. The HRD score was determined as the unweighted sum of LOH, TAI and LST, represented as: HRD score = LOH + TAI + LST.
We screened samples using mRNA and DNA methylation profiles to compute four stemness scores: DNA methylation-based stemness score, epigenetically regulated DNA methylation-based stemness score, differentially methylated probe-based stemness score and enhancer elements/DNA methylation-based stemness score as outlined in previous studies23.
Quantification of TNB and mutation data
Two methodologies were used to identify potential neoantigens arising from SNVs and Indels. For SNVs, somatic nonsynonymous coding SNVs were identified and minimal peptides encompassing mutation sites were extracted, followed by prediction of binding to autologous MHC using NetMHCpan v.3.0 (ref. 55). On the other hand, Indel variants meeting specific criteria were extracted, and downstream protein sequences obtained to generate nine-mer peptides. These peptides were then evaluated for their ability to bind MHC molecules using the pVAC-Seq v.4.0.8 pipeline56, also using NetMHCpan v.3.0. The mutation data, specifically encompassing missense mutations and nonsense mutations, were obtained from the PanCancer Atlas consortium and used in this analysis. The dataset (https://gdc.cancer.gov/about-data/publications/pancanatlas) underwent filtering, requiring mutation calls to be generated by two or more mutation callers (NCALLERS > 1).
Signature calculation for bulk-seq data
To study the consequences of LOY, a literature review was performed, and a variety of tumour-associated signatures gathered (Supplementary Table 3)57,58,59,60,61,62. Each signature was assessed using ssGSEA implemented through the GSVA R package49 (v.1.44.5). Scoring methods are in the figure legends. Where information is not provided in the figure legends, the methodologies were documented in the respective citations.
To validate the CRISPR–Cas9-mediated Y-KO MB49 (Y-KO)-derived gene expression signature in human BLCA data, we first performed a differential expression analysis between the Y-KO and Y-Scr groups, which identified a robust set of upregulated and downregulated genes. We then calculated a Y phenotype score by dividing the signature scores of upregulated genes by those of downregulated genes, with all values scaled to the [0,1] interval.
Pan-cancer scRNA-seq data collection
For pan-cancer scRNA-seq data, transcriptome data of 346 samples from 251 people across 20 scRNA-seq datasets were obtained from public studies63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82, from which tumour samples were selected for later analysis. Accession numbers for each scRNA-seq dataset and detailed clinical information for patients and samples are summarized in Supplementary Table 4. To avoid issues related to platform heterogeneity, only datasets generated from 10x Genomics droplet based scRNA-seq datasets were included.
Quality control and preprocessing of pan-cancer scRNA-seq data
We performed quality control filtering and integration using the Scanpy package (v.1.9.5). Filtering was performed based on (1) confirmation that information was available for all nine Y signature genes, (2) cells had greater than 200 detected genes and (3) the mitochondrial gene counts were below 20%. Additional quality filters were applied to the data to remove barcodes that fell into any of the following categories: possible debris with too few genes expressed (less than 400) and too few unique molecular identifiers (UMIs) (less than 500), possibility of duplicate cells based on genes expressed (more than 5,500) or UMIs (more than 30,000). Count matrices and AnnData objects were then combined using a concatenate function, normalized to log transcripts per million units using the ‘sc.pp.normalize_total’ function, and log-transformed using the ‘sc.pp.log1p’ function. The normalized HNSC dataset from GSE150430 was then combined. Subsequently, non-tumour samples were removed, and we retained 1,030,968 high-quality cells and 14,689 genes for downstream analysis.
Combining and batch effect correction of pan-cancer scRNA-seq data
We used the scVI Python package (scvi-tools; v.1.0.4)83 to integrate and batch correct scRNA-seq data. The scVI model was trained on the scRNA-seq data, considering samples as covariates. Following batch correction, the corrected data were integrated if multiple batches were present. The effectiveness of batch correction was evaluated by assessing the reduction in batch-specific variation while ensuring preservation of signal. Downstream analyses such as clustering, differential expression analysis or pathway enrichment analysis were performed on the batch-corrected data. Visualization of the results was achieved through two-dimensional UMAP plots, illustrating cell types, batches, datasets, gender, organs and cancer types.
Cell-type annotation of pan-cancer scRNA-seq data
To annotate cells, we used the scANVI algorithm from the scVI Python packages (scvi-tools; v.1.0.4) and the Luo et al.71 dataset, where cells were pre-labelled as epithelium, endothelium, fibroblast, lymphocyte, myeloid or plasma cell. Subsequently, we performed unsupervised clustering of the scANVI latent space, and then used Leiden clustering, followed by cluster assignment to specific cell types. The scANVI model was configured with max_epochs = 20 and cluster labels were transferred and predicted, guided by a sample size of n_samples_per_label = 100. The integrated latent embedding provided by scANVI served as the basis for downstream analysis, with the dataset segregated by cell type for further investigation. To delineate cell subtypes within myeloid cell, lymphocyte and plasma cell populations, we merged corresponding AnnData and mitigated batch effects and other sources of variation using scVI. Subsequently, we predicted subtypes using Celltypist84 (v.1.6.2), using ‘majority voting’ with default parameters and the pre-trained ‘Immune_All_Low.pkl’ model.
Annotating LOY cells in pan-cancer scRNA-seq data via Random Forest
We collected scRNA-seq pan-cancer data from paired tumour and adjacent normal samples and, following preprocessing, categorized cells from adjacent normal samples as: male cells as having wild-type Y (WTY) chromosomes and female cells as LOY cells. Employing the train_test_split function from sklearn.model_selection, we divided data from the normal samples into training and test sets, with a split ratio of 70% for training and 30% for testing. Next, we trained a Random Forest classifier model (RandomForestClassifier from the sklearn.ensemble Python package (v.1.3.2)) to differentiate LOY and WTY cells based on the expression levels of the nine Y chromosome genes used for the bulk RNA-seq classification of LOY samples. The performance of the model was assessed using the test set, achieving an accuracy score of 0.83.
To further validate LOY prediction by a Random Forest model, we obtained 23 samples from Liu et al.24, including sequencing data for single-cell RNA (GSE245552), bulk RNA (GSE255163) and WES (GSE255165). YchrS and average CNA of Y chromosome were calculated using the same method as CCLE data. LOY at the single-cell level were predicted by the same Random Forest model used for the pan-cancer single-cell datasets. Owing to absence of RPS4Y1 expression, it was set as 0 for all the cells when applying the Random Forest model.
Genomic DNA isolation and WES
Genomic DNA was isolated from CRISPR Y-KO cells and CRISPR–Cas9-mediated Scr MB49 Y+ control (CRISPR Y-Scr) cell lines using the Invitrogen kit (catalogue no. K1820) following the manufacturer’s instructions. DNA samples for WES were submitted to Novogene, where library preparation, sequencing and bioinformatics analysis were conducted. The genomic DNA was fragmented randomly into short pieces, end-repaired, A-tailed and ligated with Illumina adaptors. Following PCR amplification, size selection and purification, hybridization capture of libraries was performed. Captured libraries were further enriched by PCR amplification and assessed for quality using Qubit and bioanalyzer systems. The libraries were pooled and sequenced using Illumina platforms with the PE150 strategy. Sequencing data were processed using the GATK best practices workflow. Paired-end clean reads were aligned to the mouse reference genome (GRCm39/mm39) using the Burrows–Wheeler aligner. The resulting alignments were sorted with Sambamba and duplicate reads were marked using Picard. The coverage and sequencing depth were computed, and SNP and INDEL variants were identified.
scRNA-seq of mouse tumour tissues
A total of 1 × 105 LOY MB49 cells (a LOY clonal line, MB49 clone 5 (C5)) were injected subcutaneously into C57Bl/6N mice (n = 4). Once the tumours reached 500 mm3, they were removed and processed for scRNA-seq. The tumours were cut and transferred immediately to MACS C-tubes along with chilled DMEM and tumour dissociation enzymes for mouse (Miltenyi Biotech, catalogue no. 130-096-730). The dissociated tumours were then processed using ACK Lysis buffer (Gibco, catalogue no. 2537772), dead cell removal kit (Stem Cell Technologies, catalogue no. 17899) and EasySep Mouse CD45 Positive Selection Kit (Stem Cell Technologies, catalogue no. 18945). The CD45-enriched cells were next stained with Hashtag antibodies (TotalSeq-B0301 anti-mouse Hashtag 1 Antibody; TotalSeq-B0302 anti-mouse Hashtag 2 Antibody) and stained sequentially for CD45, CD3, CD4, CD8, CD11b, F4/80 and B220 along with 4′,6-diamidino-2-phenylindole (DAPI) and sorted for CD4+, CD8+ and CD11b+ and mixed into equal ratios. This mixture of highly enriched CD45+ cells was combined in a 1:1 ratio with live CD45− cells to make a final mixture that was sent for scRNA-seq.
The Cedars-Sinai Applied Genomics, Computation and Translational Core used 10x genomics 3′ scRNA-seq to sequence all samples to around 60% saturation. Samples were processed using Cell Ranger (10x genomics) based on a pre-mRNA GRCh38 reference. Since the samples were not hashed, potential doublet cells were identified using Scrublet applied to the filtered feature barcode matrices from Cell Ranger. Scrublet analysed the 10% most variable genes, identified by Scanpy package (v.1.9.5, scanpy.pp.highly_variable_genes function), predicting a 10% doublet rate, and then discarded doublet cells. Finally, nuclei with over 10% of their UMIs linked to mitochondrial genes or those in the top and bottom 5% based on the number of unique genes and UMI count were also removed.
One female and one male normal healthy C57BL/6N bladder sample from our previous study31 were also analysed. Filtering was performed based on: (1) cells had more than 200 detected genes and (2) the mitochondrial gene counts were below 20%. Additional quality filters were applied to the data to remove barcodes that fell into any of the following categories: possible debris with too few genes expressed (less than 400) and too few UMIs (less than 500), possibility of duplicate cells based on genes expressed (more than 30,000) or UMIs (more than 5,500). We normalized the data to 1 × 104 counts per cell and calculated the base-10 logarithm. We used sc.pp.combat to remove the batch effect and applied subsequent downstream analyses on the batch-corrected data. To annotate cells, we used the scVI and scANVI algorithm from the scVI Python packages (scvi-tools).
Analysis for xenograft scRNA-seq datasets
To further investigate the ability of LOY malignant cells to induce LOY in benign cells in the TME, we downloaded public scRNA-seq datasets of human xenografts in immunocompromised mice from GSE254890 (ref. 35) (SW480 cells from a male patient with CRC injected into male mice, 14 samples were incorporated as SW480 group), GSE110501 (ref. 85; only eight samples from normal tissues were incorporated as male control) and GSE144236 (ref. 86; A431, SCC and CAL27 injected into female mice, three samples incorporated as female control). Based on scRNA-seq and bulk RNA-seq data provided, SW480 cells used were LOY cells, which matched with the Y chromosome information obtained by our CCLE analysis on RNA-seq data. Mouse cells were selected either by tumour cell depletion using FITC conjugated antibodies, or by expression level of mouse genes compared with human genes. Potential debris (cells with fewer than 200 expressed genes or 400 UMIs) and possible doublets (cells with more than 8,500 expressed genes or 30,000 UMIs) were filtered out. After normalization, batch correction and cell type annotation were performed by scVI and scANVI. YchrS was calculated ‘scanpy.tl.score_genes’ using all Ychr gene expression.
Mouse HCC studies
Mice
MUP-uPA+ on C57BL/6 (ref. 87) background 1 were bred and housed under specific pathogen-free conditions in an American Association for Accreditation of Laboratory Animal Care-approved barrier facility at Cedars-Sinai Medical Center. MUP-uPA+ mice were fed a Western diet (Teklad, catalogue no. TD.88137) for 8 months beginning at 8 weeks after birth. HCC development was analysed at 10 months of age.
Tissue preparation for mouse scRNA-seq and single-nuclei RNA-seq
Mice were killed by CO2 inhalation and livers were perfused with PBS containing 2% of heparin (20 USP units ml−1) to remove traces of blood. For single-nucleus preparation, livers were isolated, tumour tissues were dissected and cut into 50 mg tumour tissue pieces for single-nucleus isolation and sequencing. Tissue was frozen in dry ice (solid CO2) and kept in liquid nitrogen for long-term storage. For single-cell preparation, livers were isolated, and tumour tissues were dissected and digested using a cocktail of digestion enzymes containing collagenase I (450 U ml−1) (Sigma-Aldrich, catalogue no. C0130) and DNase I (120 U m−1) (Sigma-Aldrich, catalogue no. D4263) in PBS (with Ca2+/Mg2+) for 30 min at 37°C with gentle shaking at 150 rpm for liver immune cell isolation. After incubation, cell suspensions were filtered through a 70 µm cell strainer. Immune cells were enriched by density-gradient centrifugation over Percoll (GE Healthcare, catalogue no. 17-0891-01) at 1,000g for 25 min without brake (40% Percoll in RPMI-1640 and 80% Percoll in 5% FBS/PBS). Leukocyte rings on a border of gradient were collected, washed and stained. Immune cell suspensions were stained with Zombie Aqua (BioLegend, catalogue no. 423101) on ice for 15 min to exclude dead cells, incubated with Fc Block TruStain FcX (Clone 93, BioLegend, catalogue no. 101320, RRID: AB_1574975) for 20 min in 2% FBS-PBS and then stained with fluorochrome labelled antibody for 30 min on ice (CD45-PerCP/Cyanine5.5 (QA17A26, BioLegend, catalogue no. 157612; RRID, catalogue no. AB_2832558, 1:100)). All the flow cytometry antibodies were validated by the manufacturer (BioLegend) and were validated in the laboratory in single channel controls. Live, CD45+ cells were sorted by BD sorter Aria III using a 100-µm nozzle.
Mouse scRNA-seq
The single-cell droplets were generated with a Chromium X controller using Chromium Next GEM Single Cell 3′ Reagent Kits v3.1 (Dual Index) (10X Genomics, catalogue no. 1000268). Approximately 8,000 to 10,000 cells were collected to make cDNA at the single-cell level. cDNA amplification and library construction were performed according to the manufacturer’s instructions. All cDNA and libraries were quantified via Agilent Technologies 2100 Bioanalyzer. Gene expression libraries were sequenced at a targeted depth of 50,000 reads per cell on the Illumina Novaseq X plus (Illumina) at Novogene. Fastq files were obtained and then processed with Cell Ranger v.8.0.1 aligning to the mouse (mm10) 2020-A reference genome on 10x Genomics Cloud Analysis.
Mouse single-nucleus RNA sequencing
Single nuclei were isolated from frozen tumour tissues using the Chromium Nuclei Isolation Kit (10x Genomics, catalogue no. 1000493) according to the manufacturer’s instructions. cDNA amplification, library construction, sequencing and genome mapping were performed in the same way as for mouse scRNA-seq.
Validation of LOY effect using independent scRNA-seq data
Processed scRNA-seq data and corresponding cell type information for 116 liver cancer samples from 94 male patients40 were analysed using our Random Forest model to predict LOY at the single-cell level. Only primary tumour or metastasis samples were included in the survival analysis.
InferCNV analysis
For the results presented in Extended Data Fig. 8e,f, CNVs in the scRNA-seq data were predicted using the InferCNV tool (https://github.com/broadinstitute/inferCNV; v.1.13.0), so that differences in the frequencies between the LOYSCR and WTYSCR epithelial cells of gains or deletions of entire chromosomes or large chromosomal segments could be identified. The algorithm was run with default parameters, using all WTYSCR stromal cells and immune cells as reference cells. For the results presented in Extended Data Fig. 6c,d, the analysis and figure were generated using Infercnvpy (https://github.com/icbi-lab/infercnvpy; v.0.4.5).
Functional signature calculation for scRNA-seq data
We used the ‘scanpy.tl.score_genes’ function from the Scanpy Python package (v.1.9.5) to compute gene set scores across cells. This function calculates gene scores for each gene listed62,88,89 in ‘gene_list’ across all cells stored within the dataset.
Sorting immune and epithelial cells from tumours and PBMCs
We used three distinct models to examine LOY in vivo: (1) naturally occurring Y+ and LOY (Y−) cells7, (2) an established LOY clonal line (C5) and (3) CRISPR-engineered Y-KO and Y-Scr cells7. For the tumour challenge, 1 × 105 cells from each line—MB49 clone 5 (C5), Y− (LOY), Y+ (WTY), CRISPR Y-KO and CRISPR Y-Scr—were injected subcutaneously into the flanks of C57Bl/6N mice (n = 7 per group) obtained from Taconic Biosciences7.The DNA levels of Y chromosome genes in each engineered cell type were checked for abundance before injection. Subcutaneous tumours from each group were disrupted mechanically, filtered through a 70 µm cell strainer (Corning, catalogue no. 352350) with RPMI-1640 cell culture grade media (Gibco, catalogue no. 11875093). ACK lysis buffer (Gibco, catalogue no. A1049201) was used to disrupt the infiltrating red blood cells. The single cells were then centrifuged and resuspended in 1× HBSS buffer (Gibco, catalogue no. 14025092) and counted in a cell counter machine. Tumours with viability of greater than 60% were used for subsequent procedures. EasySep Dead Cell Removal (Annexin V) Kit (Stem Cell Technologies, catalogue no. 17899) was used to increase the viability of each tumour and remove the dead cells. Viable cells were next processed with EasySep Mouse CD45 Positive Selection Kit (Stem Cell Technologies, catalogue no. 18945). The CD45 cells with the positive magnetic beads were purified and resuspended in EasySep Buffer (Stem Cell Technologies, catalogue no. 20144). These cells were next stained with CD45-Alexa Fluor 488 (BioLegend, catalogue no. 103122, 1:40) and Viability ghost dye Red 710 (Cytek, catalogue no. SKU 13-0871-T100) and sorted for only CD45+ cells in BD AriaIII machine. These highly purified CD45+ immune cells were next used for isolating high-quality genomic DNA with Monarch Nucleic Acid Purification Kits (NEB) and quantified. The flow through obtained after the CD45 positive selection, containing stromal, endothelial or other blood cells, was next processed with the EasySep Mouse Epithelial Cell Enrichment Kit II (Stem Cell Technologies, catalogue no. 19868), to isolate only the epithelial cells. The purity of pre- and post-isolation populations was assessed by antibody staining of random samples from each group, using the CD45 AF488 (BioLegend, catalogue no. 103122, 1:40) antibody and the BD Symphony A5, with results being analysed using Flow Jo software v.10.9.0.
For isolating T cells from these tumours (n = 6 each group) and their respective PBMCs, the following panel was used: CD45 (BioLegend, catalogue no. 103116; 1:40); CD3 (BD, catalogue no. 749276, 1:40); TCR β chain (TCRb, BioLegend, catalogue no. 109205, 1:40); CD11b (BD, catalogue no. 563553, 1:40); CD45R (BD, catalogue no. 612950, 1:40); Ghost dye Red 710 viability dye (Tonbo Biosciences, catalogue no. 13-0871-T100). Three compartments were sorted with BD FACSymphony S6 machine: epithelial (Ghost Red 710 dye−CD45− or CD45−TdTomato+); non-T immune cells (Ghost Red 710 dye−CD45+CD11b+B220+) and T cells (Ghost Red 710 dye−CD45+CD11b−B220−CD3+TCRb+). The sorting gates and FACS data are shown in Supplementary Fig. 1. Subsequently, the sorted cell compartments from tumours from the both groups were used for high-quality DNA extraction and subsequent qPCR. FC was calculated by comparing individual dCT values to respective average WTY(Y+) dCt or average Y SCR dCt values.
To get substantial amount of viable T cells for DNA isolation from subcutaneous tumours, the tumours of one group were mashed and pooled together and then proceeded for sorting. However, after sorting, the T cells were aliquoted randomly to four tubes and then processed for DNA isolation, to increase the efficacy of the result and decrease the chances of human error. Therefore, even if each group had six tumours pooled together, the graph in Extended Data Fig. 10c (right panel) shows four dots of one colour.
RNA-seq of CD45− cells from CRISPR Y-KO and Y-Scr tumours
Tumours derived from subcutaneous injection of CRISPR Y_KO and CRISPR Y-Scr cells into the flanks of C57BL/6N mice were removed and processed. Tumour-derived single-cell suspensions were subjected to FACS to isolate CD45− cells as described above. Total RNA was extracted from the isolated cells using the RNeasy Plus Mini Kit with gDNA Eliminator columns (Qiagen), following the manufacturer’s protocol. RNA sequencing library preparation and sequencing were performed by Novogene. Quality assessment of RNA-seq data, including sequence, alignment and quantification metrics, was conducted using FastQC v.0.12.1 and summarized with MultiQC v.1.13. Illumina Truseq adaptor, polyA and polyT sequences were trimmed using Trimmomatic v.0.39. The trimmed reads were aligned to the mouse genome (GRCm39/mm39) using STAR aligner v.2.5.2b, with parameters aligned to the ENCODE long RNA-seq pipeline recommendations (https://github.com/ENCODE-DCC/long-rna-seq-pipeline). Gene-level expression was quantified using featureCounts v.1.5.3, using Ensembl gene annotations (release v.113) for both alignment and quantification.
Genes with low expression were filtered out by applying a threshold of sum of estimated counts (from featureCounts) of at least ten. Differential gene expression analysis was performed on filtered estimated read counts using the R Bioconductor package DESeq2 v.1.42.1, using a generalized linear model with a negative binomial distribution. Differentially expressed genes were identified based on a Benjamini–Hochberg adjusted P value < 0.05 and FC cut-off (≥2 or ≤−2). To validate the Y-KO-derived gene phenotype signature in human cancer data, we first excluded all Y-linked genes to prevent bias in the differential expression results. We then calculated a LOY gene phenotype score by dividing the signature scores of up-regulated genes by those of down-regulated genes, with scores scaled to a [0,1] interval.
BBN treatment and PBMC isolation
For the BBN experiment, 8-week-old mice (n = 3–4 mice per timepoint) were administered with 0.5% BBN water for 12 weeks. After 12 weeks, BBN was replaced with standard tap water. Mice were killed at 2, 4, 12, 20 and 25 weeks using isoflurane. Subsequently, blood was drawn directly from the heart using an ethylenediaminetetraacetic acid (EDTA)-prewet insulin syringe and collected in an EDTA Microvette. From each mouse, a range of 700 to 1,000 µl of blood was collected. To enhance yield and DNA quality, mice were pooled in each group. Pooled samples were diluted 1:1 (v:v) with PBS-EDTA 0.1 M and then stratified on Histopaque-1077 Ficoll (Sigma, catalogue no. GE17-5446-02) at a ratio of 3:1 (v:v). Samples were centrifuged for 30 min at 400 rcf, with acceleration and break ramps set to 0 to allow gradual phase separation. The resulting PBMC ring was collected and washed once with PBS (1X). A subsequent centrifugation of 5 min at 400 rcf (with acceleration and break ramps set to maximum speed) resulted in a pellet that was processed for DNA extraction.
Tissue microarray
A human BLCA tissue microarray (TMA) with 33 unique cases comprised of triplicate cores from each patient tumour with an individual core size of 1 mm was used. The TMA was comprised of both male (n = 18) and female (n = 15) patients. Cores from female patients were used as controls for FISH.
XY FISH staining
The unstained TMA formalin-fixed paraffin-embedded sections (4 μm) were baked at 55–60 °C overnight before subjecting the slide to the following steps on the Abbott VP2000 FISH Instrument: (1) deparaffination of the slide using xylene, (2) pre-treatment of the slide using 0.2 N HCl and 1 M NaSCN, (3) protease treatment with pepsin, (4) fixation in 10% buffered formalin and, finally, (5) dehydration in series of increasing concentration (70%, 85% and 100%) ethanol. The slide was then subjected to a co-denaturation step using ThermoBrite (melting temperature 73 °C, 5 min; hybridization temperature 37 °C overnight). Post hybridization the slide was washed twice with SSC/0.3% NP-4 72 ± 1 °C for 2 min and twice with 2× SSC/0.3% NP-4 15–30 °C for 1 min. Finally, the slide was counterstained with nuclear DAPI before sealing with coverslip for visualization. The fluorescence tags were as follows: CEPX Xp11.1-q11.1—Spectrum Green (excitation, 497 nm; emission, 524 nm) CEPY Yp11.1-q11.3—Spectrum Orange (excitation, 559 nm; emission, 588 nm) and 18S RNA probe—Spectrum Aqua (excitation, 433 nm; emission, 480 nm).
IHC staining
Formalin-fixed paraffin-embedded samples were sectioned at 4-μm thickness onto Superfrost Plus slides (Fisher Scientific, catalogue no. 12-550-15). IHC staining was performed on the Ventana Discovery Ultra Instrument (Roche) as described90. After applying antigen retrieval buffer (CC1 (Tris, pH 8.0) (Roche Ventana, catalogue no. 950-124), CD45 primary antibody (Cell Signaling, catalogue no. 13917S, rabbit monoclonal) was applied. Primary antibody was diluted antibody dilution buffer (Roche Ventana, catalogue no. ADB250) for 1 h at room temperature: anti-CD45 (1:500). DISC anti-Rabbit HQ (Roche Ventana, catalogue no. 760-4815) was then applied for chromagen staining. After DAPI nuclear counterstain, the tissue area was covered coverslipped and mounted with ProLong antifade medium (Invitrogen, catalogue no. P36984).
Whole-slide imaging
XY FISH immunofluorescence slides were scanned using the ZEISS Axio Scan.Z1 whole slide scanner at ×20 magnification (Plan-Apochromat lens (numerical aperture, 0.8; M27)). TMA tissue cores were outlined with permanent marker pen on the coverslip for tissue detection. Region of scan was generated by a polygon tool and the raw focus map was generated using the ‘every-2-tiles’ strategy (z-range 150 µm, 21.04-µm step size) under ×5 lens (Fluor ×5/0.25 M27), while a fine focus map was generated using onion skin (z-range 100 µm, 2.06-µm step size, 0.1 density, 24 maximum number of points). Both focus maps were generated in the DAPI channel at 2% LED intensity, 50-ms exposure time. Spectrum Green (X probe) was excited at 495-nm wavelength (5% LED intensity, 150-ms exposure time) and detected at 500–550-nm bandwidth. Spectrum Orange (Y probe) was excited at 548-nm wavelength (25% LED intensity, 150 ms exposure time), detected at 570–640-nm bandwidth. Nuclear DAPI fluorescence was excited at 420-nm wavelength (2.5% LED intensity, 50-ms exposure time), detected at 430–470-nm bandwidth. Spectrum Aqua (18S RNA probe) was excited at 434-nm wavelength (5% LED intensity, 150-ms exposure time) and detected at 460–500-nm bandwidth. All signals were detected by Hamamatsu Orca Flash camera and 16-bit depth format image setting was applied. Standard IHC slide was imaged using the Leica Aperio AT2 whole slide scanner at ×20 magnification.
Image quantitation and analysis: HALO AI module
The whole slide image obtained from Zeiss Axio scan system was imported into HALO AI Module (Indica Labs), v.4.0.5107.318, for analysis. Upon import, the TMA image underwent segmentation to identify individual tissue cores. Missing cores were identified and removed from the analysis. The remaining cores were processed using the Nuclei Segmentation AI module, following the manufacturer’s guidelines. For AI training, seven distinct regions of interest were selected, comprising a total of 43 nuclei, to refine the Nuclei Segmentation plugin. Following segmentation, FISH analysis was conducted using the HALO FISH module, v.3.2.3, to detect nuclear signals. The resulting data were exported as.csv files, containing object-level (cell) data for subsequent analysis.
Validation of LOY correlation via FACS-sorted scRNA-seq data
To further validate the results and minimize the impact of mis-annotating LOY epithelial cells as LOY immune cells, we analysed 21 CD45-based FACS-sorted samples from three independent public scRNA-seq datasets (HNSC, GSE182227 (ref. 32); CHOL, GSE171899 (ref. 33) and BLCA, GSE211388 (ref. 34)). This collection included 12 matched CD45+ and CD45− samples from six tumours. Detailed dataset and sample information are provided in Supplementary Table 7. The same quality control, normalization and batch correction procedures described for the pan-cancer human scRNA-seq datasets were applied. CD45 expression was validated to ensure the purity of the FACS-selected samples. LOY cells were predicted using a Random Forest model.
To further validate the accumulation of LOY immune cells in tumours, we analysed two additional datasets: RCC dataset36 (accession number, EGAD0001008030), comprising 14 matched tumour (also included in the pan-cancer datasets) and blood samples. HNSC dataset (accession number, GSE139324 (ref. 37)), containing 38 matched TIL and PBMC samples. Detailed dataset and sample information are presented in Supplementary Tables 4 and 7. The same quality control, normalization, batch correction and LOY cell prediction methods were applied. Additionally, cell types were identified using the scANVI algorithm and marker gene expression, with annotated pan-cancer scRNA-seq datasets serving as references.
Long-term in vitro T cell stimulation assay
Mouse CD8+ T cells were isolated from spleens of C57BL/6N mice using the Mouse CD8+ T Cell Isolation kit (Miltenyi Biotec, catalogue no. 130-104-075). CD8+ T cells were then activated by seeding onto six-well plates coated with 1 µg ml−1 anti-CD3 (clone 2C11, BioLegend, catalogue no. 100302) and anti-CD8 (clone 37.51, BioLegend, catalogue no. 102102). T cells were cultured in RPMI supplemented with 10% fetal calf serum, 1% penicillin–streptomycin, 50 µM 2-mercaptoethanol, 1% insulin transferrin sodium selenite as well as 0.1 µg ml−1 IL-7 (Peprotech, catalogue no. 217-17) and IL-2 (Peprotech, catalogue no. 212-12). T cells were kept at no higher than 1 × 106 ml−1 and transferred to new coated plates every 2–3 days to maintain activation. DNA and RNA was isolated at the timepoints indicated using the Monarch Genomic DNA Purification Kit (New England Biolabs, catalogue no. T3010L) or RNeasy Plus Mini Kit with gDNA Eliminator (Qiagen, catalogue no. 74134), respectively. CDNA was generated with Maxima H Minus cDNA Synthesis Master Mix (Thermo Fisher, catalogue no. M1662) followed by qPCR. Data were normalized to day 1.
Quantitative PCR
Genomic DNA (10 ng per reaction) was used to detect and quantify Y‐chromosome-specific genes associated with LOY signatures—Kdm5d, Uty, Eif2s3y, Ddx3y, Ssty1, Ssty2 and Zfy1/2—as well as to detect the presence of Cas9 in immune and epithelial compartments. Housekeeping genes (B2m, Gapdh and Actb) served as endogenous controls. All qPCR reactions were carried out using SYBR Green Universal Master Mix (Applied Biosystems, catalogue no. 4309155) on a Quant Studio 6 Flex Real-Time PCR system (Applied Biosystems). To assess Y chromosome copy number in various TIL immune cell populations (T cells and non-T cells), we compared cycle threshold (Ct) values from each sorted population against Ct values from wild-type male tumour cells, using the ΔΔCt method to calculate FC. For Cas9 detection, Ct values in sorted immune populations were compared with DNA from wild-type C57Bl/6N mice, which have no Cas9 integration, using Gapdh and Actb. Absence (or near-absence) of Cas9 amplification in immune compartments confirmed that these cells were not contaminated by, or had phagocytosed, genome-edited epithelial cells (Supplementary Fig. 1).
Details of primer sequences used in this manuscript for DNA qPCR are as follows:
Uty forward, TCACCCTCTTCAGCCATTTC; reverse, GTTCTCATGCCCTTCTCCATTA
Kdm5d forward, CTGCAAGATGGCTGCATTTC; reverse, TCGCTCCTCCTGTACCATAA
Ddx3y forward, AGCAGATTCAGTGGAGGATTT; reverse, CCACTACTTCGGCTGCTATT
Eif2s3y forward, CGTTATGCCGAGCAGATAGAA; reverse, CCGTCTCAGTAGGAAGTAGGA
Sssty1 forward, TGAAGAAGAGGAGGAGGAAGT; reverse, TTGGGTGACAGGCTCATTAC
Ssty2 forward, GGTGCCATTCTTACAGGACTAT; reverse, GTGGAGGTTACCTTCCTTGTAG
Zfy1/2 forward, CACCAAGAAAGCAGAACACATC; reverse, GCCTTTGTGTGAACGGAAATTA
Gapdh forward, AACAGCAACTCCCACTCTTC; reverse, CCTGTTGCTGTAGCCGTATT
Actb forward, ACCCAGGCATTGCTGACAGG; reverse, GGACAGTGAGGCCAGGATGG
B2m forward, ACAGTTCCACCCGCCTCACATT; reverse, TAGAAAGACCAGTCCTTGCTGAAG
Cas9 forward, CCCAAGAGGAACAGCGATAAG; reverse, CCACCACCAGCACAGAATAG
RNA primers:
Pdcd1 forward, CGGTTTCAAGGCATGGTCATTGG; reverse, TCAGAGTGTCGTCCTTGCTTCC
Havcr2 (Tim3) forward, GTATCCTGCAGCAGTAGGTC; reverse, CCCTGCAGTTACACTCTACC
Ctla4 forward, GTACCTCTGCAAGGTGGAACTC; reverse, CCAAAGGAGGAAGTCAGAATCCG
Tcf7 forward, CCTGCGGATATAGACAGCACTTC; reverse, TGTCCAGGTACACCAGATCCCA
Gapdh forward, ATGCCTCCTGCACCACCAACT; reverse, ATGGCATGGACTGTGGTCATGAGT
Actb forward, ACCCAGGCATTGCTGACAGG; reverse, GGACAGTGAGGCCAGGATGG.
FC values were calculated using the ΔΔCt method relative to the appropriate wild-type controls. Data were used to quantify the relative copy number of Y chromosome genes in tumour‐derived immune subsets or to confirm the absence of Cas9 in cells not genetically engineered.
Validation of T cell exhaustion impact on LOY via scRNA-seq
The publicly available processed scRNA-seq dataset from Giles et al.39 was analysed to investigate the impact of chronic stimulation on the stability of the Y chromosome in T cells. This dataset included gp33-specific CD8+ T cells from TCR-transgenic mice subjected to acute (LCMV Armstrong) and chronic (LCMV Clone 13) LCMV infections. Chronic stimulation of T cells was validated through the upregulation of canonical exhaustion markers, including Tox, Pdcd1 and Ctla4, and the downregulation of Tcf7. To evaluate LOY, the expression levels of Y-linked genes (Uty, Kdm5d, Ddx3y, Usp9y) were analysed.
Cell-type-specific gene signatures for deconvolution analysis
To generate cell-type-specific gene signatures for LOYSCR/WTYSCR epithelial cells, CD4+ T cells, and CD8+ T cells from scRNA-seq data, we conducted differential analysis using the ‘sc.tl.rank_genes_groups’ function of the Scanpy (v.1.9.5) package. This analysis used Wilcoxon rank sum (Mann–Whitney U) tests to identify significant differences across each LOYSCR and WTYSCR cell type. We first identified genes significantly up-regulated (log2FC > 1, adjusted P value < 0.05) in the LOYSCR versus WTYSCR epithelial cells, CD4+ T cells and CD8+ T cells separately. To establish unique signatures for each cell type, we then excluded genes expressed in more than 15% of any other LOYSCR or WTYSCR cell type. We then performed deconvolution on normalized bulk expression data from TCGA cancer types using the ssGSEA algorithm, evaluating the relationship of these signatures with patient outcome.
Survival analysis
Time-to-event outcomes were presented by using Kaplan–Meier curves and compared by using log-rank test or univariate Cox proportional hazards model (survival R package; v.3.5.8) as noted in each figure. Two multivariable Cox proportional hazards models were fitted, each as a function of (1) YchrS with ancestry and race as known risk factors and confounders; (2) LOY signatures scRNA-seq signatures, including LOYSCR CD4+ T cell, LOYSCR CD8+ T cell, and LOYSCR epithelial cell signatures, with age as known risk factors and confounders. Hazard ratio along with 95% CI based on multivariable Cox proportional hazards models were reported. The function surv_cutpoint from the survminer R package (v.0.4.9) was used to determine the optimal cut-off value for the LOYSCR signatures in relation to the time-to-event outcome. This method uses maximally selected rank statistics from the maxstat91 R package (v.0.7-25) to classify two groups (low- versus high-risk) based on the optimal cut-point. Moreover, continuous variables included as covariates in the Cox proportional hazards model were evaluated92. Linearity was assessed to ensure model adequacy.
Development and validation of prognostic nomogram
According to clinical risk factors and risk scores of multivariate Cox regression coefficients for Extended Data Table 2, a prognostic nomogram was established using the ‘rms’ R software package (v.6.8-0), and the prediction accuracy of the nomogram was assessed using the calibration curve to evaluate the match between expected and observed events at 2, 5 and 8 years.
Ethics statement
Human samples
All human specimens and associated data were collected following protocols approved by the Institutional Review Board (IRB protocol 43021) at Cedars-Sinai Medical Center, adhering strictly to the Declaration of Helsinki guidelines. Written informed consent was obtained from each participant or their legal guardian. Detailed information regarding patient recruitment, sample collection (including TMA preparation), and data management can be found within IRB protocol 43021.
Animal studies
All animal procedures were reviewed and approved by the Institutional Animal Care and Use Committee (IACUC protocol 8253) at Cedars-Sinai Medical Center. Experiments were conducted in strict accordance with the guidelines specified in the National Institutes of Health (NIH) Guide for the Care and Use of Laboratory Animals. Protocol 8253 comprehensively describes animal housing conditions, care standards and experimental methodologies. All animal experiments were performed in accordance with institutional IACUC protocols. Mouse were housed under standard conditions with a 12-h light/12-h dark cycle, temperatures maintained between 68 °F and 79 °F (20–26 °C), and relative humidity between 30% and 70%.
Statistical analysis
All analyses were conducted using R (v.4.3.1) and Python (v.3.10.9). Before commencing tests, data were assessed for normality using the Kolmogorov–Smirnov test, followed by Bartlett or Levene tests to evaluate homogeneity of variances. For normally distributed variables, the unpaired Student’s t-test (Stats R package; v.4.3.1) was applied, whereas non-normally distributed variables were analysed using Wilcoxon rank sum tests. The correlation between paired variables was assessed using Spearman’s correlation coefficients. Data presentation and multiple comparison corrections are as stated in figure legends. Statistical significance was considered when P values were less than 0.05, including adjusted P values. Discovery analyses involving more than 20 comparisons underwent multiple testing correction using the p.adjust function in R or multipletests function in Python, applying the Benjamini–Hochberg method to control the false discovery rate at 0.05. To compare ROC curves, we used the roc.test function from the pROC R package (v.1.18.5). This allowed us to assess differences between AUC of YchrS and the AUC of YwholeS or LOYDNA. Python packages such as Scanpy (v.1.9.5), Pandas (v.2.0.0), Statsmodels (v.0.14.0), NumPy (v.1.24.2), Scipy (v.1.10.1), Matplotlib (v.3.8.0), Seaborn (v.0.11.2) and Sklearn (v.1.3.2), were used for data analysis. The R package ComplexHeatmap (v.2.11.1) was used to generate heat maps, and visualization was facilitated using ggplot2 (v.3.3.5), ggpubr (v.0.6.0), ggrepel (v.0.9.2), Statannot (v.0.6.0), Circlize (v.0.4.16), GseaVis (v.0.0.5), Enrichplot (v.1.22.0), GridExtra (v.2.3.0), Pheatmap(v.1.0.12) and DEGreport (v.1.38.5) R packages. For data manipulation, Readr (v.2.1.5), Readxl (v.1.4.3), Dplyr (v.1.1.4), Plyr (v.8.9), Apeglm (v.1.24.0), Tidyr (v.1.3.1), Tidyverse (v.2.0.0), Tibble (v. 3.2.1), Iranges (v.2.36.0), Biobase (v.2.62.0), BiocGenerics (v.0.48.1), Lubridate (v.1.9.3), Stringr (v.1.5.1) and AnnotationDbi (v.1.64.1) were used for analysis.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The data supporting the findings of this study are available within the Article and Supplementary Information. All bulk RNA-seq, single-cell and nuclear RNA-seq data and WES data generated for this study are available in the Gene Expression Omnibus (accession numbers GSE290112, GSE290113, GSE290114, GSE290115, GSE290587 and GSE290588). Source data are provided with this paper.
Code availability
Software packages, notebooks and scripts used for analysis are available at https://github.com/KnottLab/NATURE_LOY_Pancancer.
References
Forsberg, L. A. et al. Mosaic loss of chromosome Y in peripheral blood is associated with shorter survival and higher risk of cancer. Nat. Genet. 46, 624–628 (2014).
Danielsson, M. et al. Longitudinal changes in the frequency of mosaic chromosome Y loss in peripheral blood cells of aging men varies profoundly between individuals. Eur. J. Hum. Genet. 28, 349–357 (2020).
Duan, Q. et al. Mosaic loss of chromosome Y in peripheral blood cells is associated with age-related macular degeneration in men. Cell Biosci 12, 73 (2022).
Kido, T. & Lau, Y. F. Roles of the Y chromosome genes in human cancers. Asian J. Androl. 17, 373–380 (2015).
Qi, M., Pang, J., Mitsiades, I., Lane, A. A. & Rheinbay, E. Loss of chromosome Y in primary tumors. Cell https://doi.org/10.1016/j.cell.2023.06.006 (2023).
Brown, D. W. & Machiela, M. J. Why Y? Downregulation of chromosome Y genes potentially contributes to elevated cancer risk. J. Natl Cancer Inst. 112, 871–872 (2020).
Abdel-Hafiz, H. A. et al. Y chromosome loss in cancer drives growth by evasion of adaptive immunity. Nature 619, 624–631 (2023).
Noveski, P. et al. Loss of Y chromosome in peripheral blood of colorectal and prostate cancer patients. PLoS ONE 11, e0146264 (2016).
Mattisson, J. et al. Loss of chromosome Y in regulatory T cells. BMC Genomics 25, 243 (2024).
Sonugur, F. G. & Akbulut, H. The role of tumor microenvironment in genomic instability of malignant tumors. Front. Genet. 10, 1063 (2019).
Prokop, J. W. & Deschepper, C. F. Chromosome Y genetic variants: impact in animal models and on human disease. Physiol. Genomics 47, 525–537 (2015).
Scanlan, M. J., Simpson, A. J. & Old, L. J. The cancer/testis genes: review, standardization, and commentary. Cancer Immun. 4, 1 (2004).
Yuan, J. et al. Integrated analysis of genetic ancestry and genomic alterations across cancers. Cancer Cell 34, 549–560 e549 (2018).
Carrot-Zhang, J. et al. Comprehensive analysis of genetic ancestry and its molecular correlates in cancer. Cancer Cell 37, 639–654 e636 (2020).
McGrail, D. J. et al. High tumor mutation burden fails to predict immune checkpoint blockade response across all cancer types. Ann. Oncol. 32, 661–672 (2021).
Rizvi, N. A. et al. Mutational landscape determines sensitivity to PD-1 blockade in non-small cell lung cancer. Science 348, 124–128 (2015).
Yarchoan, M., Johnson, B. A., Lutz, E. R., Laheru, D. A. & Jaffee, E. M. Targeting neoantigens to augment antitumour immunity. Nat. Rev. Cancer 17, 209–222 (2017).
Lauss, M. et al. Mutational and putative neoantigen load predict clinical benefit of adoptive T cell therapy in melanoma. Nat. Commun. 8, 1738 (2017).
Telli, M. L. et al. Homologous recombination deficiency (HRD) score predicts response to platinum-containing neoadjuvant chemotherapy in patients with triple-negative breast cancer. Clin. Cancer Res. 22, 3764–3773 (2016).
Abkevich, V. et al. Patterns of genomic loss of heterozygosity predict homologous recombination repair defects in epithelial ovarian cancer. Br. J. Cancer 107, 1776–1782 (2012).
Popova, T. et al. Ploidy and large-scale genomic instability consistently identify basal-like breast carcinomas with BRCA1/2 inactivation. Cancer Res. 72, 5454–5462 (2012).
Birkbak, N. J. et al. Telomeric allelic imbalance indicates defective DNA repair and sensitivity to DNA-damaging agents. Cancer Discov. 2, 366–375 (2012).
Malta, T. M. et al. Machine learning identifies stemness features associated with oncogenic dedifferentiation. Cell 173, 338–354.e15 (2018).
Liu, X. et al. Th17 cells secrete TWEAK to trigger epithelial-mesenchymal transition and promote colorectal cancer liver metastasis. Cancer Res. 84, 1352–1371 (2024).
Dumanski, J. P. et al. Smoking is associated with mosaic loss of chromosome Y. Science 347, 81–83 (2015).
Bonnet, S. et al. A mitochondria-K channel axis is suppressed in cancer and its normalization promotes apoptosis and inhibits cancer growth. Cancer Cell 11, 37–51 (2007).
Pishesha, N., Harmand, T. J. & Ploegh, H. L. A guide to antigen processing and presentation. Nat. Rev. Immunol. 22, 751–764 (2022).
Dhatchinamoorthy, K., Colbert, J. D. & Rock, K. L. Cancer immune evasion through loss of MHC class I antigen presentation. Front. Immunol. 12, 636568 (2021).
Fantini, D. et al. A carcinogen-induced mouse model recapitulates the molecular alterations of human muscle invasive bladder cancer. Oncogene 37, 1911–1925 (2018).
Williams, P. D., Lee, J. K. & Theodorescu, D. Molecular credentialing of rodent bladder carcinogenesis models. Neoplasia 10, 838–846 (2008).
Abdel-Hafiz, H. A. et al. Single-cell profiling of murine bladder cancer identifies sex-specific transcriptional signatures with prognostic relevance. iScience 26, 107703 (2023).
Puram, S. V. et al. Cellular states are coupled to genomic and viral heterogeneity in HPV-related oropharyngeal carcinoma. Nat. Genet. 55, 640–650 (2023).
Alvisi, G. et al. Multimodal single-cell profiling of intrahepatic cholangiocarcinoma defines hyperactivated Tregs as a potential therapeutic target. J. Hepatol. 77, 1359–1372 (2022).
Yu, H. et al. Tumor-infiltrating myeloid cells confer de novo resistance to PD-L1 blockade through EMT-stromal and Tgfβ-dependent mechanisms. Mol. Cancer Ther. 21, 1729–1741 (2022).
Hosohama, L. et al. Colorectal cancer stem cell subtypes orchestrate distinct tumor microenvironments. Preprint at bioRxiv https://doi.org/10.1101/2024.04.25.591144 (2024).
Li, R. et al. Mapping single-cell transcriptomes in the intra-tumoral and associated territories of kidney cancer. Cancer Cell 40, 1583–1599 e1510 (2022).
Cillo, A. R. et al. Immune landscape of viral- and carcinogen-driven head and neck cancer. Immunity 52, 183–199 e189 (2020).
Ruffin, A. T. et al. B cell signatures and tertiary lymphoid structures contribute to outcome in head and neck squamous cell carcinoma. Nat. Commun. 12, 3349 (2021).
Giles, J. R. et al. Shared and distinct biological circuits in effector, memory and exhausted CD8(+) T cells revealed by temporal single-cell transcriptomics and epigenetics. Nat. Immunol. 23, 1600–1613 (2022).
Xue, R. et al. Liver tumour immune microenvironment subtypes and neutrophil heterogeneity. Nature 612, 141–147 (2022).
Maluf, S. W., Martinez-Lopez, W. & da Silva, J. DNA damage: health and longevity. Oxid. Med. Cell Longev. 2018, 9701647 (2018).
Ten, A., Kumeiko, V., Farniev, V., Gao, H. L. & Shevtsov, M. Tumor microenvironment modulation by cancer-derived extracellular vesicles. Cells 13, 682 (2024).
Sakaguchi, S., Yamaguchi, T., Nomura, T. & Ono, M. Regulatory T cells and immune tolerance. Cell 133, 775–787 (2008).
Kverneland, A. H. et al. Adoptive cell therapy with tumor-infiltrating lymphocytes supported by checkpoint inhibition across multiple solid cancer types. J. Immunother. Cancer 9, e003499 (2021).
Ratto, G. B. et al. A randomized trial of adoptive immunotherapy with tumor-infiltrating lymphocytes and interleukin-2 versus standard therapy in the postoperative treatment of resected nonsmall cell lung carcinoma. Cancer 78, 244–251 (1996).
Liu, J. et al. An integrated TCGA pan-cancer clinical data resource to drive high-quality survival outcome analytics. Cell 173, 400–416.e411 (2018).
Diboun, I., Wernisch, L., Orengo, C. A. & Koltzenburg, M. Microarray analysis after RNA amplification can detect pronounced differences in gene expression using limma. BMC Genomics 7, 252 (2006).
Barbie, D. A. et al. Systematic RNA interference reveals that oncogenic-driven cancers require TBK1. Nature 462, 108–112 (2009).
Hänzelmann, S., Castelo, R. & Guinney, J. GSVA: gene set variation analysis for microarray and RNA-seq data. BMC Bioinf. 14, 7 (2013).
Taylor, A. M. et al. Genomic and functional approaches to understanding cancer aneuploidy. Cancer Cell 33, 676–689.e3 (2018).
Mermel, C. H. et al. GISTIC2.0 facilitates sensitive and confident localization of the targets of focal somatic copy-number alteration in human cancers. Genome Biol. 12, R41 (2011).
Carter, S. L. et al. Absolute quantification of somatic DNA alterations in human cancer. Nat. Biotechnol. 30, 413–421 (2012).
Knijnenburg, T. A. et al. Genomic and molecular landscape of DNA damage repair deficiency across The Cancer Genome Atlas. Cell Rep. 23, 239–254.e6 (2018).
Timms, K. M. et al. Association of defects with genomic scores predictive of DNA damage repair deficiency among breast cancer subtypes. Breast Cancer Res. 16, 475 (2014).
Nielsen, M. & Andreatta, M. NetMHCpan-3.0; improved prediction of binding to MHC class I molecules integrating information from multiple receptor and peptide length datasets. Genome Med. 8, 33 (2016).
Hundal, J. et al. pVAC-Seq: a genome-guided in silico approach to identify tumor neoantigens. Genome Med. 8, 11.
Cristescu, R. et al. Molecular analysis of gastric cancer identifies subtypes associated with distinct clinical outcomes. Nat. Med. 21, 449–456 (2015).
Li, Y. et al. Pan-cancer characterization of immune-related lncRNAs identifies potential oncogenic biomarkers. Nat. Commun. 11, 1000 (2020).
Zeng, D. Q. et al. IOBR: multi-omics immuno-oncology biological research to decode tumor microenvironment and signatures. Front. Immunol. 12, 687975 (2021).
Chen, X. Y. et al. Turning up the heat on non-immunoreactive tumours: pyroptosis influences the tumor immune microenvironment in bladder cancer. Oncogene 40, 6381–6393 (2021).
Chen, X. Y. et al. CD8 T effector and immune checkpoint signatures predict prognosis and responsiveness to immunotherapy in bladder cancer. Oncogene 40, 6223–6234 (2021).
Mariathasan, S. et al. TGFβ attenuates tumour response to PD-L1 blockade by contributing to exclusion of T cells. Nature 554, 544–548 (2018).
Li, R. Y. et al. Mapping single-cell transcriptomes in the intra-tumoral and associated territories of kidney cancer. Cancer Cell 40, 1583–1599.e10 (2022).
Zhang, Y. P. et al. Single-cell analyses of renal cell cancers reveal insights into tumor microenvironment, cell of origin, and therapy response. Proc. Natl Acad. Sci. USA 118, e2103240118 (2021).
Werba, G. et al. Single-cell RNA sequencing reveals the effects of chemotherapy on human pancreatic adenocarcinoma and its tumor microenvironment. Nat. Commun. 14, 797 (2023).
Ma, L. C. et al. Tumor cell biodiversity drives microenvironmental reprogramming in liver cancer. Cancer Cell 36, 418–430.e6 (2019).
Regner, M. J. et al. A multi-omic single-cell landscape of human gynecologic malignancies. Mol. Cell 81, 4924–4941.e10 (2021).
Chen, Y. P. et al. Single-cell transcriptomics reveals regulators underlying immune cell diversity and immune subtypes associated with prognosis in nasopharyngeal carcinoma. Cell Res. 30, 1024–1042 (2020).
Xu, J. F. et al. Single-cell RNA sequencing reveals the tissue architecture in human high-grade serous ovarian cancer. Clin. Cancer Res. 28, 3590–3602 (2022).
Li, C. B. et al. Single-cell transcriptomics reveals cellular heterogeneity and molecular stratification of cervical cancer. Commun. Biol. 5, 1208 (2022).
Luo, H. et al. Pan-cancer single-cell analysis reveals the heterogeneity and plasticity of cancer-associated fibroblasts in the tumor microenvironment. Nat. Commun. 13, 6619 (2022).
Sathe, A. et al. Single-cell genomic characterization reveals the cellular reprogramming of the gastric tumor microenvironment. Clin. Cancer Res. 26, 2640–2653 (2020).
Kim, N. et al. Single-cell RNA sequencing demonstrates the molecular and cellular reprogramming of metastatic lung adenocarcinoma. Nat. Commun. 11, 2285 (2020).
Lambrechts, D. et al. Phenotype molding of stromal cells in the lung tumor microenvironment. Nat. Med. 24, 1277–1289 (2018).
Chen, S. J. et al. Single-cell analysis reveals transcriptomic remodellings in distinct cell types that contribute to human prostate cancer progression. Nat. Cell Biol. 23, 87–98 (2021).
Ma, X. S. et al. Identification of a distinct luminal subgroup diagnosing and stratifying early stage prostate cancer by tissue-based single-cell RNA sequencing. Mol. Cancer 19, 147 (2020).
Luo, H. et al. Characterizing dedifferentiation of thyroid cancer by integrated analysis. Sci. Adv. 7, eabf3657 (2021).
Chen, Z. H. et al. Single-cell RNA sequencing highlights the role of inflammatory cancer-associated fibroblasts in bladder urothelial carcinoma. Nat. Commun. 11, 5077 (2020).
Qian, J. B. et al. A pan-cancer blueprint of the heterogeneous tumor microenvironment revealed by single-cell profiling. Cell Res. 30, 745–762 (2020).
Zhang, M. et al. Single-cell transcriptomic architecture and intercellular crosstalk of human intrahepatic cholangiocarcinoma. J. Hepatol. 73, 1118–1130 (2020).
Peng, J. Y. et al. Single-cell RNA-seq highlights intra-tumoral heterogeneity and malignant progression in pancreatic ductal adenocarcinoma. Cell Res. 29, 725–738 (2019).
Lin, W. et al. Single-cell transcriptome analysis of tumor and stromal compartments of pancreatic ductal adenocarcinoma primary tumors and metastatic lesions. Genome Med. 12, 80 (2020).
Lopez, R., Regier, J., Cole, M. B., Jordan, M. I. & Yosef, N. Deep generative modeling for single-cell transcriptomics. Nat. Methods 15, 1053–1058 (2018).
Conde, C. D. et al. Cross-tissue immune cell analysis reveals tissue-specific features in humans. Science 376, eabl5197 (2022).
Zhao, Q. et al. Single-cell transcriptome analyses reveal endothelial cell heterogeneity in tumors and changes following antiangiogenic treatment. Cancer Res. 78, 2370–2382 (2018).
Ji, A. L. et al. Multimodal analysis of composition and spatial architecture in human squamous cell carcinoma. Cell 182, 1661–1662 (2020).
Weglarz, T. C., Degen, J. L. & Sandgren, E. P. Hepatocyte transplantation into diseased mouse liver. Kinetics of parenchymal repopulation and identification of the proliferative capacity of tetraploid and octaploid hepatocytes. Am. J. Pathol. 157, 1963–1974 (2000).
Thorsson, V. et al. The immune landscape of cancer. Immunity 48, 812–830.e814 (2018).
Chu, Y. S. et al. Pan-cancer T cell atlas links a cellular stress response state to immunotherapy resistance. Nat. Med. 29, 1550–1562 (2023).
Ho, A. S. et al. Comparative proteomic analysis of HPV(+) oropharyngeal squamous cell carcinoma recurrence. J. Proteome Res. 21, 200–208 (2022).
Lausen, B. & Schumacher, M. Maximally selected rank statistics. Biometrics 48, 73–85 (1992).
Grambsch, P. M. & Therneau, T. M. Proportional hazards tests and diagnostics based on weighted residuals. Biometrika 81, 515–526 (1994).
Acknowledgements
We thank G. Martins and J. Dos Santos for their expert advice and assistance with FACS, H. Ye for interpreting the histological slides used in FISH immunofluorescence experiments and J. Xiao of the Theodorescu laboratory for generating MB49 subcutaneous xenografts and the corresponding scRNA-seq data. This work was supported in part by NIH grants CA278732 (to D.T.) and CA273925 (to E.K.K.), as well as by the NIH National Center for Advancing Translational Sciences through UCLA CTSI grant UL1 TR001881 (to V.F.C.).
Author information
Authors and Affiliations
Contributions
D.T. had the original idea and conceptualized and initiated the study. X.C., S.R.V.K. and D.T. conceived the study design and analyses. X.C., Y.S., S.C., S.R.V.K. and D.T. developed the methodology. X.C., Y.S., S.C., M.B., S.K.K.M., J.Z., E.K.K., V.K.R. and V.F.C. acquired data, performed bioinformatics and biostatistical analyses and generated graphs. M.B., L.H., M.T., H.A.A.-H, V.K.R., M.R., E.K.K. and J.Z. carried out the wet-lab experiments, generated the data and performed the related statistical analyses. S.K.K.M. analysed the mouse HCC sequencing data and generated associated graphs. V.F.C. provided guidance on multivariate Cox analysis and nomogram development. X.C., S.R.V.K. and D.T. wrote the manuscript with input and specific sections from all authors. D.T. and S.R.V.K. supervised the study. All authors reviewed and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature thanks Joshua Rubin and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Development and Validation of the Y Chromosome Transcriptional Signature (YchrS).
a. Differential gene expression analysis for Y Chromosome genes comparing LOYDNA and WTYDNA male TCGA samples. Dot color represents -log10 adjusted P-values for each gene. Vertical lines indicate log2FC of -1 and 1 and the horizontal line indicates -log10 adjusted P-values of 200. The 9 genes used for the RNA-based YchrS are annotated. b. YchrS scores in LOYDNA and WTYDNA TCGA tumor samples, where samples are separated by cancer types. Boxes denote the median (center line) and the first and third quartiles (lower and upper edges of the box). Whiskers extend to either the minimum or maximum values within 1.5 × the interquartile range (IQR). Any data points outside these whiskers are considered outliers. c. Distribution of chromosome segments and corresponding Copy Number Alteration (CNA). Each dot represents one chromosome segment in a particular cell line, with midpoint location shown in X axis and log2 mean CNA shown in Y axis. The color of the dots represents the YchrS level of the samples. d. Average CNA at the chromosome level for the 625 CCLE male cell lines with available Y chromosome CNA, with the lines separated into WTYBR (n = 442) and LOYBR (n = 183) groups. Data presentation as in (a). Two‐sided Wilcoxon rank‐sum test. e. YchrS and corresponding average CNA of each chromosome for samples in (d). Each dot represents a cell line, with YchrS level shown by color.
Extended Data Fig. 2 Integration of Clinical Features with LOY Status.
a. YchrS scores for male TCGA tumors separated by smoking status (Current/Ever, n = 1,019; Never, n = 307) across nine cancer types. Boxes denote the median (center line) and the first and third quartiles (lower and upper edges of the box). Whiskers extend to either the minimum or maximum values within 1.5 × the interquartile range (IQR). Any data points outside these whiskers are considered outliers. Two‐sided Wilcoxon rank-sum tests. b. YchrS scores for Liver Hepatocellular Carcinoma (LIHC) samples, separated by Hepatitis B virus (HBV) or Hepatitis C virus (HCV) infection status (left), and YchrS scores for Stomach Adenocarcinoma (STAD) samples separated by Epstein-Barr Virus (EBV) infection status (right). Boxplot presentation as in (a). Two‐sided Wilcoxon rank-sum tests. c. The distribution of YchrS values (Black line) is shown with two proposed thresholds indicated by vertical dashed lines: mean (Red) and median (Light blue). d. AUROC analysis comparing specificity (X-axis, 0–1) against sensitivity (Y-axis, 0–1) for mean and median YchrS cut-offs used to detect LOY. Arrows indicate sensitivity and specificity for each threshold. e. Kaplan-Meier survival curves for Overall Survival (OS) in WTYBR and LOYBR tumors across three ethnicities from the TCGA pan-cancer dataset. Statistics were calculated using the univariate Cox-Proportional-Hazard (coxPH) model. CI, Confidence Interval. f. Kaplan-Meier survival curves for OS in WTYBR and LOYBR tumors across four genetic ancestries from the TCGA pan-cancer dataset. Statistics were calculated using the univariate coxPH model. g-h. Kaplan-Meier survival curves illustrating OS (g) and Disease-Specific Survival (DSS, h) for TCGA patients, grouped by expression levels of nine Y chromosome genes. Statistics were calculated using the univariate coxPH model.
Extended Data Fig. 3 Tumors with LOY have more genomic instability, enhanced proliferation and stemness, and an immunosuppressive microenvironment.
a. tumor mutational burden (TMB, left), tumor neoantigen burden (TNB, Indel and SNV, middle) and Mutation rates (silent and non-silent, right) in WTYBR (n = 2,685) and LOYBR (n = 1,442) tumors. Data are presented as mean ± s.e.m. Two‐sided Wilcoxon rank sum tests. Indel, Insertion/Deletion. SNV, Single Nucleotide Variant). b. Pearson correlation scores and corresponding P-values comparing YchrS scores and aneuploidy scores (left) and altered fractions (right) in 29 different cancer types. c. Comparison of different genomic instability pathway scores between WTYBR and LOYBR tumors. Dot colors represent mean scaled scores for each pathway in each group. The size of dots represent -log10 P-values adjusted by Benjamini-Hochberg correction as calculated based on two‐sided Wilcoxon rank sum tests. HRD, Homologous Recombination Deficiency; LOH, Loss of Heterozygosity; LST, Large-scale State Transitions; TAI, Telomeric Allelic Imbalance. d. Comparison of different functional pathways scores between WTYBR and LOYBR tumors. The size of squares represents -log10 P-values adjusted by Benjamini-Hochberg correction as assessed by two‐sided Wilcoxon rank sum tests. ENHss, Enhancer element Methylation-based Stemness; DMPss, Differentially Methylated Probe-based Stemness; EREG-METHss, Epigenetically Regulated DNA Methylation-based Stemness; DNAss, DNA methylation-based Stemness; EMT, Epithelial-Mesenchymal Transition. e. Comparison of angiogenesis signature scores between WTYBR (n = 2,685) and LOYBR (n = 1,442) tumors. Data are presented as mean ± s.e.m. and significance was assessed based on two‐sided Wilcoxon rank sum tests. f. Comparison of glycolysis (left) and hypoxia (right) signature scores between WTYBR (n = 2,685) and LOYBR (n = 1,442) tumors. Data are presented as mean ± s.e.m. and significance was assessed based on two‐sided Wilcoxon rank sum tests. g. Comparison of hormone-related pathway signature scores between WTYBR (n = 2,685) and LOYBR (n = 1,442) tumors. Data are presented as mean ± s.e.m. and significance was assessed based on two‐sided Wilcoxon rank sum tests. h. Comparison of expression levels for receptor and co-inhibitory genes between WTYBR and LOYBR tumors. Square color indicates mean scaled gene expression in each group and square size represents -log10 P-values adjusted by Benjamini-Hochberg correction, as assessed by two‐sided Wilcoxon rank sum tests.
Extended Data Fig. 4 QC Framework and Cell Type Annotation for the Pan-Cancer scRNA-seq Dataset.
a. Schematic depicting tumor sources of the human scRNA-seq pan-cancer datasets developed and analyzed in this study. b. Quality control metrics for the pan-cancer scRNA-seq datasets with vertical lines indicating selection criteria: 400 <Gene counts <5500 (top) and 500 <Total counts <30,000 (center and bottom) for further analysis. c. Cells from the pan-cancer scRNA-seq data colored by original dataset (top left), organ (top right), sex information (bottom left) and cancer type (bottom center) and major cell type (bottom right). d. Expression levels of marker genes across the major cell types identified in the pan-cancer scRNA-seq datasets. Dot size indicates the proportion of expressing cells and color indicates mean expression levels.
Extended Data Fig. 5 Development and Validation of the Prediction Model for Determining LOYSCR Status in a Pan-Cancer scRNA-seq Dataset.
a. Schematic of the development of the Random Forest model utilized to predict LOYSCR status in individual cells. b. Expression levels of 9 YchrS signature genes in male and female samples. Dot size indicates the proportion of expressing cells and color indicates mean expression levels. c. Proportion of predicted LOYSCR in samples in 6 major cell types in normal female and male samples from the scRNA-seq datasets. Error bars represent the 95% Confidence Interval (CI) of the mean value. In female samples, the number of analyzed cells per cell type was as follows: B/Plasma cells (n = 23,797), Endothelial cells (n = 24,755), Epithelial cells (n = 174,909), Fibroblasts (n = 69,688), Myeloid cells (n = 69,306), and T/NK cells (n = 171,458). In male samples, the corresponding numbers were B/Plasma cells (n = 25,999), Endothelial cells (n = 22,908), Epithelial cells (n = 157,029), Fibroblasts (n = 31,122), Myeloid cells (n = 74,698), and T/NK cells (n = 185,299). d. Expression levels of the 9 YchrS signature genes in LOYSCR and WTYSCR cells from male tumor samples. Dot size indicates the proportion of expressing cells and color indicates mean expression levels. e. Total counts per cell type, where cells are separated by their cell type and LOYSCR and WTYSCR status. Violin plots show the full distribution of total read counts per cell type. The box plots overlaid within each violin denote the median (center line) and the first and third quartiles (lower and upper edges of the box). Whiskers extend to either the minimum or maximum values within 1.5 × the interquartile range (IQR). Any data points outside these whiskers (if shown) are considered outliers. The number of cells analyzed per category was as follows: in LOYSCR samples, B/Plasma cells (n = 5,935), Endothelial cells (n = 7,975), Epithelial cells (n = 73,576), Fibroblasts (n = 9,950), Myeloid cells (n = 23,292), and T/NK cells (n = 40,675); in WTYSCR samples, B/Plasma cells (n = 20,064), Endothelial cells (n = 14,933), Epithelial cells (n = 83,453), Fibroblasts (n = 21,172), Myeloid cells (n = 51,406), and T/NK cells (n = 144,624). f. Scores for chromosome-specific signatures (with each signature comprising all genes from the corresponding chromosome) for male cells, where cells are separated by their LOYSCR and WTYSCR status. Data are presented as mean values ± 95% Confidence Interval (CI). The number of cells analyzed per category was as follows: in LOYSCR samples, B/Plasma cells (n = 5,935), Endothelial cells (n = 7,975), Epithelial cells (n = 73,576), Fibroblasts (n = 9,950), Myeloid cells (n = 23,292), and T/NK cells (n = 40,675); in WTYSCR samples, B/Plasma cells (n = 20,064), Endothelial cells (n = 14,933), Epithelial cells (n = 83,453), Fibroblasts (n = 21,172), Myeloid cells (n = 51,406), and T/NK cells (n = 144,624). g. Correlations between YchrS from bulk RNA-seq data and average Y chromosome Copy Number Alteration (CNA) from whole-exome sequencing (WES) data (left), the correlation between YchrS and the proportion of LOYSCR cells identified through single-cell RNA sequencing (middle), and the correlation between the proportion of LOYSCR cells and average Ychr CNA (right). Male and female samples are represented by blue and red dots, respectively, with each dot representing a sample. Lines show the linear regression results for male and female samples, with shaded regions showing the 95% confidence interval. R, Pearson correlation coefficient; P-value is calculated by Pearson correlation test.
Extended Data Fig. 6 Characteristics of LOYSCR Epithelial cells.
a. Expression levels of Major Histocompatibility Complex (MHC) class II genes in LOYSCR and WTYSCR epithelial cells. Dot sizes (bottom) indicate the proportion of expressing cells, colored by mean standardized expression levels. Bars (top) indicate the log2Fold Change (FC) between in LOYSCR and WTYSCR epithelial cells, where color indicates the corresponding -log10 adjusted P-value, calculated via sc.tl.rank_genes_group in scanpy package using two‐sided Wilcoxon rank‐sum test with Benjamini-Hochberg correction. b. Scores for pathways related to hormone and oncogenesis in LOYSCR and WTYSCR epithelial cells. Dot color indicates the mean pathway score, while dot size indicates the -log10 adjusted P-value of the difference between cell populations, as calculated by two‐sided Wilcoxon rank sum tests with Benjamini/Hochberg correction. c. Mean Copy Number Variation (CNV) scores of LOYSCR and WTYSCR epithelial cells, as estimated by the inferCNVpy algorithm and where the significance of the difference was calculated based on the two‐sided Wilcoxon rank-sum test. d. Distribution of CNV scores as obtained by the inferCNVpy algorithm for LOYSCR and WTYSCR epithelial cells for 12 cancer types.
Extended Data Fig. 7 Malignant epithelial cells harboring LOY exhibited higher genomic instability.
a. Sequencing depth of Whole Exome Sequencing (WES) data from CRISPR Y-KO and Y-Scr MB49 cells. b. LOY gene phenotype scores in LOYBR (n = 74) versus WTYBR (n = 147) TCGA Bladder Cancer (BLCA) samples. Data are presented as mean ± s.e.m. and significance was assessed based on two‐sided Wilcoxon rank sum tests. c. LOY gene phenotype scores across multiple cancer types in the TCGA dataset. Significant LOY gene phenotype trends were observed in Lung Adenocarcinoma (LUAD), Pancreatic Adenocarcinoma (PAAD), and Stomach Adenocarcinoma (STAD), with variable significance across other cancers. ACC (LOYBR, n = 14; WTYBR, n = 14), BLCA (LOYBR, n = 74; WTYBR, n = 147), BRCA (LOYBR, n = 0; WTYBR, n = 8), CHOL (LOYBR, n = 6; WTYBR, n = 10), COAD (LOYBR, n = 70; WTYBR, n = 85), DLBC (LOYBR, n = 7; WTYBR, n = 13), ESCA (LOYBR, n = 82; WTYBR, n = 33), GBM (LOYBR, n = 4; WTYBR, n = 85), HNSC (LOYBR, n = 143; WTYBR, n = 129), KICH (LOYBR, n = 20; WTYBR, n = 17), KIRC (LOYBR, n = 132; WTYBR, n = 184), KIRP (LOYBR, n = 168; WTYBR, n = 35), LAML (LOYBR, n = 4; WTYBR, n = 59), LGG (LOYBR, n = 16; WTYBR, n = 246), LIHC (LOYBR, n = 64; WTYBR, n = 150), LUAD (LOYBR, n = 77; WTYBR, n = 106), LUSC (LOYBR, n = 151; WTYBR, n = 133), MESO (LOYBR, n = 17; WTYBR, n = 44), PAAD (LOYBR, n = 44; WTYBR, n = 48), PCPG (LOYBR, n = 1; WTYBR, n = 72), PRAD (LOYBR, n = 9; WTYBR, n = 448), READ (LOYBR, n = 33; WTYBR, n = 30), SARC (LOYBR, n = 22; WTYBR, n = 63), SKCM (LOYBR, n = 93; WTYBR, n = 156), STAD (LOYBR, n = 137; WTYBR, n = 75), TGCT (LOYBR, n = 26; WTYBR, n = 94), THCA (LOYBR, n = 4; WTYBR, n = 123), THYM (LOYBR, n = 2; WTYBR, n = 56), UVM (LOYBR, n = 22; WTYBR, n = 22), d-e. Pathway enrichment of the running enrichment scores (top), and positions of pathway genes ordered by log fold change (bottom) in Gene Set Enrichment Analysis (GSEA) comparing CRISPR Y-KO MB49 cells with CRISPR Y-Scr MB49 cells. NES, normalized enrichment score. NES > 0 indicate the pathway is enriched in Y-KO cells, otherwise in Y-Scr cells. f-g. Stacked bar plots showing counts of Single Nucleotide Polymorphisms (SNPs, f) and Insertion and Deletions (Indels, g) in different genomic regions. CDS, coding DNA sequence. h. Ratio of mutation counts (SNPs and Indels) between CRISPR Y-KO cells and Y-Scr MB49 cells across different chromosomes.
Extended Data Fig. 8 Validation of the BBN-induced bladder cancer mouse model through scRNA-seq analysis, aligned with human scRNA-seq results.
a. Single cell RNA sequencing data of 85,759 cells from male and female tumors induced by N-butyl-N-(4-hydroxybutyl)-nitrosamine, where cells are colored by sample (FB prefix indicates female and MB indicates male), cell type and male/female status. b. Expression levels of the 4 genes used as the mouse chrY signature (YchrSmus) genes in male and female cells from the tumors shown in (a). Dot size indicates the proportion of cells expressing the gene and color indicates the mean expression level. c. Expression levels of 4 YchrSmus genes in male and female cells from the tumors shown in (a), where cells are also separated by cell type. Dot size indicates the proportion of cells expressing the gene and color indicates the mean expression level. d. Distribution of YchrSmus across all cells (left), male cells (middle), and female cells (right). e-f. Inferred Copy Number Variation (CNV) profiles across chromosomes (columns) in single cells (rows), grouped by major cell types (colored bars on the left). (e) Cells classified as LOYSCR. (f) Cells as WTYSCR. Each column spans chromosome 1 through 22, arranged along the horizontal axis. Red indicates relative copy number gains, and blue indicates losses. The color scale (−0.2 to 0.2) reflects the smoothed expression deviations estimated by inferCNV. Differences in chromosomal signal patterns highlight potential aneuploidies and region‐specific alterations linked to LOY status.
Extended Data Fig. 9 The impact of LOY on the benign cells in the TME.
a. Mean YchrSmus score across various cell types. Displayed are scRNA-seq data for normal bladder tissues from female (left) and male (middle) C57BL/6 N mice; tumors from C57BL/6 N mice following subcutaneous inoculation with LOY MB49 mouse bladder cancer cell lines (right). Error bars represent the 95% confidence interval (CI) of the mean value, estimated by bootstrap resampling. Sample sizes (n) for each cell type were as follows: Normal Bladder (Female): Epithelium (n = 443), Fibroblast (n = 6,361), Endothelium (n = 427), CD8+ T cell (n = 51), Myeloid cell (n = 350), Other immune cell (n = 47), CD4+ T cell (n = 52); Normal Bladder (Male): Epithelium (n = 976), Fibroblast (n = 10,338), Endothelium (n = 612), CD8+ T cell (n = 57), Myeloid cell (n = 640), Other immune cell (n = 89), CD4+ T cell (n = 68); LOY MB49 tumor: Epithelium (n = 178), Fibroblast (n = 97), Endothelium (n = 23), CD8+ T cell (n = 1,600), Myeloid cell (n = 2,447), Other immune cell (n = 2,242), CD4+ T cell (n = 1,335). b-c. Analysis of LOY percentage in cell populations from 6 mouse hepatocellular carcinoma (HCC) tumor samples. (b) LOY percentages of sorted CD45+ immune cell populations evaluated by scRNAseq from 3 independent samples. (c) LOY percentage in 3 independent whole tumor cell populations evaluated by snRNAseq. d. Proportion of LOYSCR and WTYSCR in individual CD45+ samples from the HNSC32 (left), CHOL33 (middle), and BLCA34 datasets (right). HNSC, Head and Neck Squamous Cell Carcinoma. CHOL, Cholangiocarcinoma. BLCA, Bladder cancer. e. LOYSCR cell proportion in matched CD45+ and CD45− samples in HNSC and BLCA datasets. Each dot represents one patient. f. Mean scaled YchrSmus values across 3 different cell types from a xenograft scRNA-seq dataset—endothelium, fibroblast, and myeloid cells—for 3 groups: Female Control (orange), Group SW480 (male CRC cells, red), Male Control (blue). Error bars represent the 95% confidence interval (CI) of the mean value, estimated by bootstrap resampling. Sample sizes (n) for each group and cell type were as follows: Female Control: Endothelium (n = 4), Fibroblast (n = 95), Myeloid cell (n = 1,068); Group SW480: Endothelium (n = 654), Fibroblast (n = 3,871), Myeloid cell (n = 6,204); Male Control: Endothelium (n = 2,946), Fibroblast (n = 4,490), Myeloid cell (n = 432). g. Representative FISH images selected from the human patient TMA cores. Smaller regions (80 micron x 80 micron) of images from the normal male and LOY cancer male patient tissue microarray cores (original diameter ~1 mm) are displayed corresponding to CD45-high and CD45-low regions as shown. CD45 signals were probed by immunohistochemistry staining and bright field imaging. Pseudocolor immunofluorescence images of nuclear DAPI, X chromosome FISH probe, Y chromosome FISH probe and the control 18sRNA FISH probe are shown as indicated in the figure. Scale bar = 20um. These data are representative of male (n = 18) staining and imaging experiments that yielded similar results.
Extended Data Fig. 10 Validation of Y chromosome loss in MB49 tumor models and immune cells.
a-b. Genomic DNA (10 ng per reaction) was isolated from sorted epithelial cells, non–T cells, and T cells derived from CRISPR‐engineered (Y-Scr or Y-KO) MB49 tumors. Wild‐type (WT) C57Bl/6 N genomic DNA (lacking Cas9) served as the reference in the ΔΔCt analysis. (a) Ct values were normalized to Gapdh and plotted as fold change relative to WT. (b) Ct values were normalized to Actb and similarly plotted as fold change over WT. Error bars represent mean ± s.e.m. from 4 biological replicates in each group. c. DNA qPCR analysis of Y chromosome genes in TdTomato+ CD45- epithelial cells (left) and CD3+ T cells (right) from CRISPR Y-Scr and CRISPR Y-KO groups. Fold changes normalized to Gapdh (purple dots) and Actb (yellow dots). P-values from two-way ANOVA with Fisher’s LSD test and Geisser-Greenhouse correction. Error bars represent mean ± s.e.m.; Each dot denotes pooled samples from six independent tumors. Six independent tumors were mashed and pooled together for substantial number of T cells isolation and then randomly aliquoted to 4 tubes to increase the efficacy of the result and reduce human error. Each dot of one color represent data from one such tube. d. DNA qPCR analysis of Y chromosome genes (Kdm5d, Uty, Eif2s3y, and Ddx3y) in PBMCs extracted from BBN-treated mice. Each dot represents the pooled DNA sample from 3-4 mice. On X axis: the time points of samples collection, along with a timeline of BBN administration and bladder tumor onset; on the Y axis the fold change expressed as relative gene expression level compared to untreated ctrl at initiation of BBN. e. Changes in DNA levels of Y chromosome genes (Ddx3y, Kdm5d, Zfy1/2, Ssty1, Ssty2) upon long term activation of primary mouse T cells in vitro. qPCR data normalized to housekeeping genes Actin (left) or B2m (right) relative to day 1 after mouse T cell isolation. Mean ± SD, n = 4. SD, Standard Deviation. f-g. Expression changes of T cell exhaustion markers (Ctla4, Pdcd1, Tcf7, Tim3) during long term activation of primary mouse T cells in vitro. Expression normalized to housekeeping genes Actin (f) or Gapdh (g) are shown relative to day 1 post T cell isolation. Mean ± SD, n = 4. h-i. Mean expression of exhaustion (h) and Y chromosome genes (i) in Naïve P14 CD8+ T cells at baseline (Day 0) and compared to at Days 8, 15, and 30 post-infection under acute (LCMV Armstrong; solid lines) or chronic (LCMV Clone 13; dashed lines) conditions. Data were extracted from publicly available transcriptomic datasets39.
Extended Data Fig. 11 Patient Survival and Calibration of Nomogram.
a. Kaplan-Meier Disease-Specific Survival (DSS) curves for TCGA samples with high or low signature scores for LOYSCR and WTYSCR CD4+ T cells (two leftmost plots), for LOYSCR and WTYSCR CD8+ T cells (two middle plots), and for LOYSCR and WTYSCR epithelial cells (two rightmost plots). Significance was assessed based on univariate Cox Proportional Hazard (coxPH) model. b. Kaplan-Meier curves of overall survival (OS) for liver cancer scRNA-seq dataset samples stratified by the proportion of LOYSCR CD4+ T cells in immune cells(left), LOYSCR CD8+ T cells in immune cells (middle), and LOYSCR cells in tumor cells (right). P-values calculated using univariate coxPH model. c. Kaplan-Meier survival curves of OS for samples in (b) stratified by the combinatorial proportions of LOYSCR tumor cells and LOYSCR CD4+ T cells, and LOYSCR tumor cells and LOYSCR CD8+ T cells. P-values for pairwise comparisons between each combinatorial group are also displayed below Kaplan-Meier curves, calculated using log-rank tests. d. Calibration plots used to assess the accuracy of the OS probabilities predicted by the nomogram (Fig. 5h) at 2,5, and 8 years compared to the observed OS rates (%). Each colored dot represents a group of subjects randomly selected from the whole cohort. Each plot includes the total number of subjects (n = 4,010), the number of events (1,203), and 500 subjects per plotted group.
Supplementary information
Supplementary Fig. 1 (download PDF )
Spectral flow gating strategies. a, Representative FACS plots illustrating the sequential gating strategy for live, single-cell tumour suspensions derived from CRISPR Y-KO and CRISPR Y-Scr tumours. tumours were dissociated mechanically, stained with Ghost Red 710 viability dye (Tonbo Biosciences) and antibodies against CD45, CD3, TCRβ, CD11b and CD45R/B220, followed by sorting of the CD3+TCRb+ T cells using the BD S6 flow cytometry machine. Debris and doublets were excluded through sequential gating (All Events → P1 → P2). Within the CD45− compartment (purple in the Alexa Fluor 700 versus APC‐Cy7 panel), TdTomato+ tumour epithelial cells were identified (bottom left). Immune cells displayed minimal presence of TdTomato (very less percentage population), confirming their purity in both Y-KO and Y-Scr groups (top panels). T cells (CD45+CD11b−B220−CD3+TCRβ+) were gated from the CD45+ population (green or orange in the FITC versus BUV805 panel). The final sorted cell populations included: (1) Ghost Red 710−CD45− (containing TdTomato+ tumour cells), (2) Ghost Red 710−CD45+CD11b+B220+ myeloid and B cells (non-T population) and (3) Ghost Red 710−CD45+CD11b−B220−CD3+TCRβ+ T cells. All sorting was performed using a BD FACSymphony S6. The red events represent both CD45− and CD45+ cells, while black events indicate CD45+ immune cells (top panels), which showed minimal tdTomato expression. This confirms the successful separation of tumour epithelial cells from immune cell fractions in both Y-KO and Y-Scr groups.
Supplementary Tables (download ZIP )
Supplementary Tables 1–9.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chen, X., Shen, Y., Choi, S. et al. Concurrent loss of the Y chromosome in cancer and T cells impacts outcome. Nature 642, 1041–1050 (2025). https://doi.org/10.1038/s41586-025-09071-2
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s41586-025-09071-2
This article is cited by
-
Sexual dimorphism in cancer: molecular mechanisms and precision oncology perspectives
Biology of Sex Differences (2026)
-
Y chromosome-linked EIF1AY deletion drives sex differences in multiple myeloma
npj Precision Oncology (2026)
-
Onkochirurgie im Kontext von Immuntherapie, Neoadjuvanz und HPV
HNO (2026)
-
Loss of Y chromosome and its implications in male amyotrophic lateral sclerosis: insights from the UK Biobank
BMC Medicine (2025)
-
Cancer more deadly when tumours lack Y chromosomes — and the loss could be contagious
Nature (2025)
