
Abstract
A ‘silent trial’ refers to the prospective, noninterventional testing of artificial intelligence (AI) models in the intended clinical setting without affecting patient care or institutional operations. The silent evaluation phase has received less attention than in silico algorithm development or formal clinical evaluations, despite its increasing recognition as a critical phase. There are no formal guidelines for performing silent AI evaluations in healthcare settings. We conducted a scoping review to identify silent AI evaluations described in the literature and to summarize current practices for performing silent testing. We screened the PubMed, Web of Science and Scopus databases for articles fitting our criteria for silent AI evaluations, or silent trials, published from 2015 to 2025. A total of 891 articles were identified, of which 75 met the criteria for inclusion in the final review. We found wide variance in terminology, description and rationale for silent evaluations, leading to substantial heterogeneity in the reported information. Overwhelmingly, the papers reported measurements of area under the curve and similar metrics of technical performance. Far fewer studies reported verification of outputs against an in situ clinical ground truth; when reported, the approaches varied in comprehensiveness. We noted less discussion of sociotechnical components, such as stakeholder engagement and human–computer interaction elements. We conclude that there is an opportunity to bring together diverse evaluative practices (for example, from data science, human factors and other fields) if the silent evaluation phase is to be maximally effective. These gaps mirror challenges in the effective translation of AI tools from computer to bedside and identify opportunities to improve silent evaluation protocols that address key needs.
Similar content being viewed by others

Main
Despite the increasing deluge of papers describing the development of artificial intelligence (AI) models for healthcare applications, strikingly few of those models have proceeded to clinical use1. A translational gap2 remains, partially due to the substantial difference between building a model that works in silico (that is, validation within a dataset) and creating one that is clinically useful, actionable and beneficial to patients or the healthcare system3.
One mechanism for bridging the translational gap is conducting an evaluation following algorithmic validation, but before the clinical evaluation of the model in practice. This phase is known as a ‘silent trial’ (a term with many variants, including ‘shadow evaluation’ or ‘silent testing’) and is common practice among many healthcare institutions with advanced internal AI teams4,5. ‘Silent’ traditionally refers to the notion that the model’s outputs are produced in parallel to (and thus separate from) the standard of care; therefore, they do not influence clinicians (Table 1).
Primarily, the silent phase of AI development is used to ascertain whether the model will maintain its performance in a live context6. The value of this phase is that it allows teams not only to test a model for potential utility (data pipeline stability and model drifts, among other concerns; see the glossary in Box 1) but also to assess the financial sustainability of models in real-world evaluations without affecting care or operation7. During this stage, teams can make informed decisions about whether to discard a model, iteratively improve its performance or move to deployment based on local evidence8.
The importance of local evidence is perhaps more relevant to AI tools than to historical healthcare interventions. While we would not expect the performance of a drug or device to change substantially when tested in a hospital across the street with the same patient population, this is indeed the case for AI models6,8,9. Even for models that have received regulatory clearance or approval based on clinical evidence, substantial differences may be apparent in local performance such that their reliability may vary across settings10,11. Researchers have noted the challenges of bringing AI systems to market based solely on retrospective evidence12,13. The silent evaluation stage may represent a low-risk bridge between retrospective and clinical evidence that may help developers decide whether a clinical trial is warranted. The regulatory science of AI involves the important consideration of which types of evidence are acceptable for determining the safety of AI as a medical device. The silent phase of translation offers a low-risk testing paradigm that reflects real-world conditions by which one might judge the performance of an algorithm. This may be a critical step before determining whether (and what type of) clinical trials should be pursued—a judgement that may be made by regulatory professionals, ethics committees or AI oversight bodies.
Given that the silent phase of AI testing offers an opportunity to evaluate performance locally using precise metrics relevant to the population and institution, yet does not affect care (thus minimizing risk to health institutions and patients alike), it is perhaps surprising that this key phase does not receive more attention. Silent trials have equivalents in other fields (for example, beta testing in software engineering, silent review in aviation, and simulations in training, which are standard practices), but, to the best of our knowledge, no reporting guidelines or authoritative publications have addressed the silent phase in medical AI. Our project group, the Collaboration for Translational AI Trials (CANAIRI), has a particular focus on building knowledge and best practices around the silent phase to facilitate local capacity-building in AI evaluations and to demonstrate accountable AI integration14. We conducted a scoping review and critical analysis15 to explore the literature around the following key points: (1) How is the silent phase defined, described and justified? (2) What practices are being undertaken during this phase? (3) What are the implications of the latter in relation to the larger goal of responsibly translating AI into healthcare systems? Scoping reviews map the existing literature on a topic, identify knowledge gaps and clarify concepts. We find this method valuable because we are addressing a nascent paradigm in AI with the goal of synthesizing and reflecting on the available literature. This Analysis aims to bring clarity and consistency to the silent phase while considering the implications of current practices for AI translation efforts.
Results
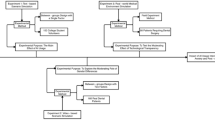
From September 2024 to October 2025, we scoped the published literature for primary research studies published in English that describe testing an AI model in a manner closely mimicking its intended use but without modifications to the standard of care, to validate the model in a ‘live’ context. From a total of 898 papers, we removed duplicates (n = 29) and screened 530 full-text articles for inclusion (Fig. 1). After excluding papers that did not describe a true live validation study, those involving substantial alterations to patient care, those with insufficient detail for us to assess the silent component of their study and those that did not involve an AI tool, we finally included 75 studies.

Following the data charting process, a further 54 papers did not meet the criteria.
We then looked for papers related to the AI tools evaluated in that set of 75 studies. We identified six additional studies that provided further details about the silent evaluation. Of these, two16,17 contained information about the original silent phase evaluation that was included in data charting, while four others18,19,20,21 explored the later clinical, stakeholder or human factors impacts of the algorithm after the silent evaluation, during its integration into patient care. As our unit of analysis is the silent phase itself, we combined only the information retrieved about the practices undertaken during the silent phase, excluding postdeployment work. Therefore, we incorporated the information extracted from the first two papers and did not include the latter four, as they were conducted while the model was not silent (that is, live), thus falling under the exclusion criteria. The results of data charting are summarized in Table 2.
Composition of silent evaluations
The geographical locations and institutions of the included silent evaluations were extracted. From the 75 final papers (excluding sister studies, as they share the same characteristics), we found silent evaluations performed in Australia, Austria, Canada, China, France, India, Germany, Mexico, the Netherlands, Saudi Arabia, Spain, South Korea, Taiwan, Turkey, the UK and the USA, with demographic information obtainable for 74 of the 75 papers (as shown in Fig. 2, generated using R software22 and RStudio23). Most silent evaluations were conducted in the USA (48%), China (19%) and the UK (7%). A list of institutions (hospitals and research centres) where silent evaluations were performed is provided in Table 3. Nine studies reported the evaluation of a commercially available AI system. Four of the nine studies reported the approval regime10,24,25,26 (for example, CE-marked, cleared device, or approved device and class rating), while the remaining papers did not provide details about the system.

The countries of silent trials were counted once for each paper, if available (74 of 75 papers). The USA was the most represented country (36 trials), followed by China (14 trials), the UK (5 trials) and Canada (3 trials). In total, 16 countries were represented in the silent trials. Figure created using R software and RStudio (2025).
Study design and purpose
Our eligibility criteria led us to papers that self-identified as silent trials, as well as to model validations under other names and forms that paralleled the silent trial methods. Importantly, only 15 studies explicitly used the term silent to describe their evaluation, highlighting that similar methodologies exhibit substantial variation in their nomenclature and conceptualization.
Definitions varied along a spectrum, ranging from technical validation of the algorithm in a live clinical environment to broad, multistage silent evaluations of the clinical setting. We note that algorithmic validation, clinical validation, temporal validation and prospective validation were often used interchangeably to describe similar methodologies but with varying scopes of evaluation (Table 2). Variation in the clinical verification of the model (human or automated annotation of ground truth for model comparison) was less predictive of the breadth and depth of clinical evaluation than the purpose of the trial itself. For instance, some papers aimed to prospectively validate the technical performance of a model (for example, “…to evaluate the ability of three metrics to monitor for a reduction in performance of a CKD model deployed at a paediatric hospital.” (ref. 27)), while others purported to evaluate the potential clinical utility of the algorithm across a wider array of elements (for example, “…to assess the AI system’s predictive performance in a retrospective setting and evaluate the human factors surrounding the BPA before initiating the quasi-experimental clinical study.” (ref. 28)).
While we only included papers for which we could be relatively confident that there was a separation between model evaluation and clinical care, this core component of the silent phase was often not clearly articulated. When not articulated as such, we inferred separation from contextual information within the paper (for example, “Clinicians assessed patients as per usual practice.”), grammatical tense (for example, “This algorithm would have identified X patients in practice.”) and minor methodological cues (for example, “The research team did not intervene in the clinical management of these patients.”).
The length of the evaluation phase was consistently reported, either as a specified date range or as a quantitative number of patients or cases; however, a justification or rationale for these choices was rarely provided. The total time period for silent evaluations ranged from 2 days to 18 months.
Model evaluation during the silent phase
Most studies described the input data and their form (for example, tabular data and images), and more than half described how the inputs were selected during the development stage. Some studies focused explicitly on technical performance-related reasons for feature selection, while others reported clinical justifications for specific variables, including the feasibility of using these variables relative to the intended use environment (and thus their relevance to evaluation during the silent phase).
Metrics of model performance included AUROC (area under the receiver operating characteristic curve), sensitivity, specificity, negative predictive value and positive predictive value, with all studies describing at least one of these. Some studies, often predominant in medical imaging, examined model performance in greater depth and included an assessment of failure modes—for example, descriptive performance on subgroups within disease categories or an exploration of a specific class of suboptimal performance, such as describing all false-negative cases.
Few studies that reported feedback to recalibrate the model included changing model thresholds to improve sensitivity or specificity, as well as updating the model based on changing demographics or features of the prospective patients. Some papers16,29,30 reported not updating the model during the evaluation (for example, “Models were not retrained for both validations for fair assessment.” (ref. 30)). Rarely did studies describe data shifts or the steps taken to address performance shifts; often, these were simply observed during the evaluation period.
A minority of studies addressed potential algorithmic biases. Typically, this meant exploring model performance among contextualized subgroups of interest (that is, algorithmic bias), which involves assessing an algorithm’s performance against identified clinical (for example, specific health conditions) or demographically defined (for example, age, sex, race and ethnicity) subgroups at risk of disparate health outcomes based on the intended use of the AI tool (that is, marginalized, vulnerable or under-represented groups)31. Race and sex were the most common subgroups of interest; rarely was a link made to health inequities or other structural issues as a rationale for conducting this testing, and when justified, it included only a general appeal.
In addition to subgroup analyses, a subset of studies examined algorithmic bias that appeared at test time when development and evaluation settings did not match. Some reported drops in performance linked to noisy or incomplete data and inconsistencies in electronic health record (EHR) coding, while others noted reduced accuracy due to differences in data acquisition, patient populations and clinical practices. Some studies specifically linked these issues to temporal or distributional shifts between training and deployment data. A common conclusion across all studies was that a performance drop is apparent when moving from retrospective to live evaluation, showing that models often perform less reliably during silent or prospective evaluation.
A key process during the silent phase is verifying the correctness of the model’s predictions in a live environment, which we have termed ‘verification of model outputs’. Such verification could refer to any of the following: agreement between a model’s prediction and information noted or coded in the medical record; an expert evaluator’s (for example, a physician’s or nurse’s) assessment of the model prediction; or a case-by-case evaluation by experts independently compared with the model’s outputs to determine agreement, conducted blind to the model output for comparison purposes. We categorize verification in our papers as human annotation versus automatic annotation, in which trials used either automated annotation of ground truth (obtaining algorithm performance (AUROC) by comparing with a test set of clinical information that was not transparently defined) or live human annotation (comparing the algorithm with clinical ground truth obtained through expert or novice consensus panels during the trial). When human annotation was used, only a small minority of these studies described the characteristics of evaluators, such as qualifications, role or whether they received any formal instructions for review. However, the evaluator of the algorithm—who was responsible for comparing the model with annotations and for viewing the system during the trial—was often invisible and was rarely reported. When alluded to, evaluators were used either to provide an independent assessment of the same outcome the model was predicting (for example, “Variance between performance of senior sonographers and AI measurements was compared.” (ref. 32)) or to evaluate aspects of the tool itself, such as establishing clinical utility (for example, “assessed the face validity, timing, and clinical utility of predictions” (ref. 33)). In some cases, it was not clearly described whether the evaluator’s role was to conduct an independent (blind) assessment of the same outcome the model was meant to predict or whether they were viewing the model output and meant to verify its accuracy.
Many studies discussed data quality issues and their management during the silent phase. While some studies described the process for removing patients with incomplete data points, conflicting data or nonstandardized data inputs, there was limited discussion on how this would be managed in a live, real-world deployment context. Some reported on elements around the data pipeline (that is, the flow of data from input to inference), including data quality issues (for example, missingness) and ‘downtime’ (that is, when the data flow stopped or was negatively affected, causing the model to become nonfunctional). Few studies detailed the granular elements of data flow from the point of contact through processing and analysis to generate predictions, but any such descriptions were generally comprehensive. One study describing the full processing stream for data flow noted the rationale of needing to most closely approximate the conditions of clinical integration, noting that the ‘deployment server’ was on the same secure private network as the clinical systems, with data pipelines monitored and continually audited by a dedicated data science team34.
Some studies described model scalability, either as a formal assessment of the computational feasibility of the model in the clinical pipeline or as a stated assertion that the model was scalable. However, it was not always clear what scalability meant in these papers.
Sociotechnical considerations
Sociotechnical considerations concern the ways in which humans design and interact with AI tools. A minority of papers described some element of user engagement either before or during the silent phase.
Most sociotechnical evaluations analysed subjective user experience related to the prediction/interface or the overall impact of the model on workflow, either in the silent environment or presumably before the model was deployed to end users. These evaluations were often conducted in collaboration with clinicians and healthcare staff, indicating that stakeholder expertise and preferences are important. However, when these end users contributed to the usability and preferences of the model20,28,35,36,37,38,39, it was often not explicitly stated that these consumers were not exposed to model predictions on live patients during the prospective testing phase to evaluate model usability.
We describe the role of human factors in the silent phase as ambiguous, much like earlier difficulties in describing model evaluators and separating the model from care. As such, the evaluation of human factors operates similarly to stakeholder engagement with end users, where feedback is used to refine the later deployment of the system, rather than to comprehensively examine the relationship between the model and the evaluator. Nevertheless, one of the papers considered cognitive factors, such as alert fatigue, in its human factors evaluation; for example, “allowed for consideration of false alerts, alert fatigue, and resources required for a sepsis huddle when designing our model. The Aware tier with high sensitivity was designed to enable situational awareness and prompt discussions about sepsis risk at the individual patient, clinical team, and unit level.” (ref. 20). Further, some studies described the integration of explainability methods (for example, SHAP (SHapley Additive exPlanations), heat maps) with model outputs during the silent phase, with the aim of preparing for improved adoption following integration. However, no study assessed the potential impact of visualizations on human decision-making, such as whether the use of explainability mechanisms could prevent persuasion by incorrect AI results.
Users and stakeholders were engaged in the process of testing or designing the model most commonly through interview groups that provided feedback on the context and facilitation of the tool, often as multidisciplinary teams (for example, “This expert group was set up in order to enhance participation of health professionals, including senior physicians, ward nurses, technicians, and leading employees.” (ref. 19)). The reasons behind these evaluations, if described at all, were usually to assess model accuracy, the feasibility of model integration and user acceptance. Assessments of usability and AI evaluation were conducted almost entirely before deployment. One study described an evaluator developing potential automation bias following a silent phase evaluation (referred to as the phenomenon of ‘induced belief revision’ (ref. 17)), which the authors note is important to address to ensure scientifically rigorous evaluation and separation of the model’s testing from care17. In the process of assessing the model’s performance against real-world information, consideration of the potential for incidental findings in the data that could have implications for patient safety was described in four papers17,24,34,39. None of these studies described any form of patient or consumer engagement.
Discussion
The vastness and diversity of literature reporting on silent evaluations of AI indicate that there is undoubtedly a perceived value in this paradigm for ensuring model performance in the prospective setting, linked to motivations around ‘responsible AI’. The heterogeneity of the currently reported practices highlights the immense opportunity to coalesce around best practices; we hope that this work is one step in this regard. In this vein, we focus specifically on the silent phase, which is bounded by good model development on one side40 and first-in-human studies (DECIDE-AI41), clinical trials (SPIRIT-AI42, CONSORT-AI43) and other clinical evaluation studies on the other. Considering the silent phase not only as a means to assess the prospective performance of a model but also as a mechanism to facilitate responsible and effective downstream translation, our scoping study highlights several opportunities for enhancing practice around this critical translational stage41.
A consistent challenge in determining whether a paper described a proper silent trial centred on the variability in the use of the term silent. Some papers used the term silent trial but then described the outputs as being visible to the care team (and thus were excluded). We adopted the multiple-reviewer method for adjudication partly because it was difficult to discern whether the model outputs were truly silent. It was common for silent evaluations to be reported in tandem with retrospective testing and/or live deployment. Due to this combination, it was similarly challenging to discern which reported aspects of the study design pertained to which of these stages. For instance, data cleaning might be described, but it was unclear whether this occurred during retrospective or prospective testing. Additionally, the number of case observations or the time period was reported as an aggregate, leaving the proportion during the silent phase unclear. In some cases, reporting on the model’s performance was aggregated across the silent and live phases in a manner similar to randomized controlled trials.
We propose that, as a first step, the field should consolidate the notion of silent as a state in which the model’s outputs are not visible to the treating team or clinician while the model’s performance is being evaluated. This does not necessarily mean that the model itself is invisible; for example, testing user interfaces may involve exposing some staff to the system. We suggest that maintaining a silent trial requires that these staff members are not caring for the same patients for whom the model inference is being run, to prevent contamination of the trial and thus ensure an objective evaluation17.
We further suggest that papers reporting on evaluations during this phase should clearly distinguish between model evaluation and the care environment. Understandably, resourcing can be a challenge to complete separation; in line with medical literature more broadly44, transparency should be encouraged, with authors able to comment on the rationale for the choices they made.
An intriguing finding—and one where we feel efforts ought to be consolidated—is the gap between what is most commonly reported and what those with extensive experience deploying AI systems know to be important. Specifically, there is an overwhelmingly strong focus on model metrics (for example, AUROC and AUPRC (area under the precision–recall curve)), with far more limited discussion of workflow and systems integration, human factors, and verification of clinically relevant ground truth labels. By contrast, the NICE (National Institute for Health and Care Excellence) standards for digital health technologies (including AI) emphasize the use of human factors and a broader set of considerations to evaluate such tools, which is far more in keeping with a healthcare environment45.
One possible explanation is that silent suggests invisibility, and human factor evaluations require end users to engage with some aspects of the model. However, we find that most reported usability evaluations involve healthcare professionals, who we assume are the intended end users of the model. Guidelines endorsed by regulatory agencies, such as Good Machine Learning Practices40, recommend the involvement of clinical staff in model development and evaluation, and the literature we describe here indicates some recognition of this guidance. Given that researchers are identifying emergent risks from additions like explainability46,47, it seems important to ensure that these impacts are measured before exposing patients (and research participants) to the model’s influence over their care. There is an immense opportunity to explore how human factors might be involved during the silent stage, which could reduce risk once the model reaches the integration stage in addition to improving the precision of the clinical evaluation protocol41,48,49.
Safety-oriented metrics for model testing can include failure modes, model bias and data shift50—well-known limitations of AI models once they proceed to real-time deployment, during which model performance typically drops (to varying degrees)51. Reasons can include data quality (for example, feature set discrepancy, temporal feature leakage, operational feature constraints52), limitations of model generalizability, mismatch between the data available for development and the deployment environment, concept drift, and unintended changes such as data drift6,14,53. Importantly, failure mode testing supports the identification of systematic patterns of lower performance. In radiology, where AI tools have seen the most uptake and have undergone rigorous research on their limitations54, failure mode reporting was much more common than for nonimaging models in our results.
Algorithmic bias is a known ethical threat in health AI, so it was somewhat surprising to see limited reporting of subgroup-specific performance testing in silent phase evaluations. It is possible that developers conducted bias testing during the development phase, with the presumption that fairness had already been addressed at that point. However, the under-reporting of subgroup-specific performance has been noted in machine learning studies55 and randomized controlled trials of AI56. Assumptions behind choices regarding algorithmic fairness approaches must be verified in their real-world environments to prevent algorithmic discrimination57,58,59. This is particularly important given that some AI models may embed patterns that track patient race even when this is not explicitly coded in the algorithm60. Clinical use of AI tools must be informed by details of the model’s performance across particular subgroups so that clinicians can properly calibrate how they weight the model’s output in their clinical decision-making to avoid risk61,62. The silent phase is an ideal stage to test the real-time failure modes of the model and to identify mitigation strategies to prevent worsening inequities and missing clinically relevant gaps in subgroup-specific performance.
While our charting framework extends beyond the original conceptualization of silent trials6, we note that, across the 75 studies reviewed, each element of charting was reported by some studies. We consider this to support the notion of a silent phase as offering an opportunity for more than just in situ technical validation. We suggest that, if this phase is considered a key component of AI translation, there would be considerable advantage in incorporating a more holistic set of practices. Without aligning silent phase evaluations with real-world needs, we risk implementing clinical applications incorrectly, potentially causing the optimism and momentum around AI to collapse and leading to preventable harm. The concept of translational trials, as advocated by our team14, frames silent evaluation as a fundamental step in responsible AI translation, with methodological practices guided primarily by the intention of replicating as closely as possible the clinical conditions in which the tool will be used. This paradigm then provides maximally relevant and nuanced information about the model’s performance to support more effective and precise translation.
We acknowledge that our scoping review has the limitation of being restricted to practices reported in the literature through published studies and is subject to the typical limitations of such work, including restriction to English-language papers and a subset of publication venues. It is possible that some elements we observed to be under-reported were actually undertaken by teams to facilitate translation but were not reported in the paper. We accept this limitation, although we also note that some teams did report these aspects. Therefore, we view the choice to report or not as reflective of the inherent values of the broader field. To address this limitation, our research team has planned a series of key informant interviews to investigate whether other practices were undertaken but simply not described in the paper.
Another limitation concerns the review process and the terminology. We initially focused on the term silent trial and its known variants, but it is possible that we are unaware of other terms describing analogous evaluative processes. Thus, by missing such works, this review might have failed to cover some other aspects of silent evaluations. Similarly, some silent evaluations may have been conducted by industry groups but not published in the literature, being available only through internal technical reports.
If the ultimate goal of the silent evaluation phase is to bridge the gap in the translation from bench to bedside, we need to ensure that the practices undertaken during this phase most closely approximate the needs of the translational environment. By intentionally designing silent trials to gather evidence that incorporates a sociotechnical and systems engineering63,64 lens, there is good reason to believe that we can improve the efficacy of translation for these complex interventions65. What does this mean for the silent evaluation phase? We believe that by broadening the scope of practices undertaken during this translation stage, we can improve the AI implementation ecosystem in healthcare. These practices should reflect, as closely as possible, the intended implementation setting. A translational evaluation paradigm embodies this framing by explicitly positioning translation as the end goal and necessitating the collection of evidence that adequately informs this state14. As more attention is placed on silent evaluations, we hope to provide constructive guidance based on this work to improve the preparation, conduct and reporting of silent phase evaluations and to move towards a focus on a translational evaluation paradigm.
Methods
This scoping review follows the framework for scoping review studies outlined by Arksey and O’Malley15. This study complies with the methodology from the JBI Manual for Evidence Synthesis guidelines66 and adheres to the PRISMA-ScR checklist (PRISMA extension for scoping reviews)67. This review study was preregistered with the Open Science Framework (https://osf.io/63bhx/) rather than PROSPERO, as it did not assess direct health-related outcomes. Institutional ethics approval was not required.
Information sources and search strategy
Our initial scope was to search the literature for studies reporting on a silent evaluation (including processes reported under analogous terms) of an AI tool in healthcare settings. The full search strategy was developed with a University of Adelaide librarian in collaboration with M.D.McC. and L.T. (Supplementary Table 1). The first search was conducted on 23 October 2024 and updated on 25 September 2025. Controlled vocabulary terms for nondatabase searches were derived from the database search terms.
Searches were conducted using the PubMed, Web of Science and Scopus databases. We also used reference snowballing (using reference lists from the included papers) and hand searched the literature from these lists, including papers that fit our inclusion criteria. We chose not to include regulatory guidelines as a primary source in this review, as our focus is less on the AI product itself and more on the design and ecological validity of its local testing.
During the process, we recognized that some teams published different components of a silent phase evaluation across multiple papers (for example, one paper might describe the model evaluation while another describes the evaluation of human factors or workflows). Therefore, a complementary search strategy was added during the extraction stage, in which the reviewer (L.T.) performed an adjacent hand search for each included paper to find additional studies exploring sociotechnical evaluations of the silently tested AI system in the final set of included papers. The papers sought were primarily on human factors, stakeholder engagement, qualitative evaluation, or adjunct studies that contained trial information not discussed in the original paper. We believe that these papers provide information about the broader life cycle of translating AI into practice that may not be immediately reported in current silent phase evaluations; however, we extracted only information pertaining to the silent phase.
Eligibility criteria
We included articles that described the evaluation of an AI or machine learning model during a silent phase evaluation in a healthcare environment (for example, hospitals, clinics, outpatient settings or other environments where healthcare is provided). Due to the ambiguous nature of classifying algorithms as AI, we relied on the consensus of members with technical expertise to categorize algorithms as eligible. We define AI (or machine learning) broadly as any model that builds predictive models from input–output data68, with training on datasets as a key process. We recognize that there may be a variety of opinions on whether some models constitute machine learning or AI; as a group, we sought to be broad in our inclusion criteria to ensure that cases in which the silent trial paradigm was used were included (encompassing many traditional machine learning approaches). We included a broad variety of machine learning and deep learning models, with more details on how papers self-classified their models available in Table 2. We excluded studies that were not related to healthcare, did not involve AI or machine learning methods, involved models unrelated to a clinical target or clinician use (for example, research-based use of machine learning in health), mentioned the silent phase but were not primary research articles, or described plans to conduct a silent evaluation (for example, protocol papers). Articles not written in English, as well as those published before 1 January 2015, were excluded, as we sought to understand current practices. Two reviewers carried out title and abstract screening, as well as full-text screening (L.T. and A.M). A third reviewer (M.D.McC.) resolved conflicts. A systematic review software (Covidence, Veritas Health Innovation69) was used for each stage of screening. The study selection criteria were applied to (1) title and abstract screening, (2) full-text screening with two pilot rounds and (3) full-text extraction for papers that did not meet the criteria during data charting.
While conducting the initial review of articles, we noted that the lack of consistent nomenclature and definitions made it difficult to distinguish a true silent phase from other paradigms, such as external or internal validations (see Table 1 and Box 1 for the nomenclature of testing paradigms). Through an iterative and collaborative process with extractors and the wider CANAIRI group, we identified the following elements as minimum qualifications for a silent phase evaluation: (1) the trial of the AI tool must be conducted in its intended use setting or simulate this setting as closely as possible (live), and (2) the AI tool’s outputs must not be acted on by the intended users and should not be seen at the time of treatment (silent). We note that the ‘live’ nature of the silent phase may be limiting depending on the operational constraints of its intended context; thus, we emphasize replicating the live context as closely as possible as an important consideration. For instance, in radiology, most scans are not analysed in real time by the clinician. As such, algorithms can run on consecutive prospective patient scans, but the results can be analysed retrospectively by evaluators to mimic real-time practice as closely as possible while remaining realistic. Another important distinction of silent trials is the separation of model evaluation and care, meaning that we excluded studies in which changes were made to the patient’s experience of care to suit the study’s aims. For example, in diagnostic studies, model outputs may not be acted on by the treating team, but the patient may undergo study-specific procedures such as new tests or interventions70. As the primary objective of a silent period is to first assess the ecological validity of the model4,6, changing the way care is delivered would contradict this goal. It should be noted that, among the various interpretations of the word ‘silent’, we opted for silence defined by the model prediction’s lack of impact on care, not the model itself being silent in the sense of being invisible (Table 1). This distinction allowed us to include studies that engage clinical end users to test different workflow integrations, evaluate user interfaces, and conduct other preclinical testing that exposes users to an AI algorithm while maintaining at least an intended separation between model evaluation and clinical care. Very often, we needed to review the full text of the paper in extensive detail to ensure that the above two criteria were met. We used at least two, often three, team members to agree on including each of the final papers.
Our above-described criteria were iteratively refined by L.T. and M.D.McC., with input from our authorship team, until we were satisfied that the studies included in the final analysis met the described conditions. While certain aspects of the evaluation’s conduct remain somewhat uncertain (see further details in the Discussion), our final list of included papers represents evaluations of AI tools that were validated live or near live in their intended implementation environment (also see Table 2 for inclusion and exclusion criteria).
Data charting process
Our data charting form was initially developed by L.T. and M.D.McC., with input from X.L., and then reviewed by the CANAIRI Steering Group. The charting process was initially drafted based on the authorship team’s own experiences with running silent evaluations at their respective institutions, and we included items that were commonly reported in these protocols71. We triangulated these protocols with relevant reporting guidelines (for example, DECIDE-AI, TRIPOD + AI), regulatory guidance (US Food and Drug Administration, Health Canada, Therapeutic Goods Administration (Australia)) and authoritative guidance documents (for example, NICE, World Health Organization). The item categories of information for extraction are listed in Supplementary Table 1, and a glossary of terms is available in Box 1.
A key assumption we made in our charting process is that AI is a sociotechnical system72. Under this framing, the evaluation of an AI tool must include not only the algorithm’s technical performance but also the entire system in which it operates, combined with the human element that sustains its performance. This assumption is grounded in the lived experience of many members of our CANAIRI collaboration team in developing and deploying machine learning models in healthcare settings—a perspective that is gaining increasing support within the literature73,74. We chose to chart information related to the evaluators, their perception of the interface, human adaptation influencing AI evaluation and the engagement of relevant stakeholders throughout the process as entry points for sociotechnical evaluation.
We completed two charting pilot rounds of six full-text papers, the first on grey literature (reports) and the second on original research from scientific journals (hand searched). Once consensus on these extractions was reached by L.T., M.D.McC. and X.L., we progressed to the official extraction. Data charting consisted of a colour-coded scheme in which items that the reviewer was unable to find were highlighted in red, uncertain items were highlighted in orange, and charting elements found in the text were either copied directly or paraphrased by the reviewer. Data were extracted using a standardized data collection form created in Google Sheets (Alphabet). Two independent reviewers (L.T. and C.S.) charted data for 55 studies and any accompanying metadata (for example, separately published study protocols, supplementary materials) in the same repository. After the initial extraction was completed, the papers were split among seven group members (L.E., L.J.P., A.v.d.V., S.B., N.P., C.S., M. Mamdani, G.K., H.T, N.C.K, M.D.McC.) based on their areas of expertise (system, technical, sociotechnical), and the papers were accordingly categorized into these groups by L.T. Therefore, these members had separate Google Sheets with L.T.’s original charting results and were required to read the papers and compare the initial charting against their own findings, resulting in each paper undergoing a minimum of two reviews. Elements remained in red if both reviewers were unable to find them, while any conflicting responses were discussed with and resolved by M.D.McC. or X.L.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The study database, which describes our full extraction from the included studies, is publicly available at https://docs.google.com/spreadsheets/d/17CFyfViM0IMPQYnBquQ16H-fqGtYvNT9D-wCX5zZO4I/edit?usp=sharing.
References
Chen, J. H. & Asch, S. M. Machine learning and prediction in medicine—beyond the peak of inflated expectations. N. Engl. J. Med. 376, 2507–2509 (2017).
Seneviratne, M. G., Shah, N. H. & Chu, L. Bridging the implementation gap of machine learning in healthcare. BMJ Innov. 6, 45–47 (2020).
Sendak, M. P. et al. A path for translation of machine learning products into healthcare delivery. EMJ Innov. https://doi.org/10.33590/emjinnov/19-00172 (2020).
McCradden, M. D., Stephenson, E. A. & Anderson, J. A. Clinical research underlies ethical integration of healthcare artificial intelligence. Nat. Med. 26, 1325–1326 (2020).
Sendak, M. et al. Editorial. Surfacing best practices for AI software development and integration in healthcare. Front. Digit. Health 5, 1150875 (2023).
Wiens, J. et al. Do no harm: a roadmap for responsible machine learning for health care. Nat. Med. 25, 1337–1340 (2019).
Morse, K. E., Bagley, S. C. & Shah, N. H. Estimate the hidden deployment cost of predictive models to improve patient care. Nat. Med. 26, 18–19 (2020).
McCradden, M. D. et al. A research ethics framework for the clinical translation of healthcare machine learning. Am. J. Bioeth. 22, 8–22 (2022).
Futoma, J., Simons, M., Panch, T., Doshi-Velez, F. & Celi, L. A. The myth of generalisability in clinical research and machine learning in health care. Lancet Digit. Health 2, e489–e492 (2020).
Kim, C. et al. Multicentre external validation of a commercial artificial intelligence software to analyse chest radiographs in health screening environments with low disease prevalence. Eur. Radiol. 33, 3501–3509 (2023).
Wong, A. et al. External validation of a widely implemented proprietary sepsis prediction model in hospitalized patients. JAMA Intern. Med. 181, 1065–1070 (2021).
Harvey, H. B. & Gowda, V. How the FDA regulates AI. Acad. Radiol. 27, 58–61 (2020).
Wu, E. et al. How medical AI devices are evaluated: limitations and recommendations from an analysis of FDA approvals. Nat. Med. 27, 582–584 (2021).
McCradden, M. D. et al. CANAIRI: the Collaboration for Translational Artificial Intelligence Trials in healthcare. Nat. Med. 31, 9–11 (2025).
Arksey, H. & O’Malley, L. Scoping studies: towards a methodological framework. Int. J. Soc. Res. Methodol. 8, 19–32 (2005).
Manz, C. R. et al. Validation of a machine learning algorithm to predict 180-day mortality for outpatients with cancer. JAMA Oncol. 6, 1723–1730 (2020).
Kwong, J. C. C. et al. When the model trains you: induced belief revision and its implications on artificial intelligence research and patient care—a case study on predicting obstructive hydronephrosis in children. NEJM AI 1, AIcs2300004 (2024).
Sendak, M. P. et al. Real-world integration of a sepsis deep learning technology into routine clinical care: implementation study. JMIR Med. Inform. 8, e15182 (2020).
Jauk, S. et al. Risk prediction of delirium in hospitalized patients using machine learning: an implementation and prospective evaluation study. J. Am. Med. Inform. Assoc. 27, 1383–1392 (2020).
Stephen, R. J. et al. Sepsis prediction in hospitalized children: clinical decision support design and deployment. Hosp. Pediatr. 13, 751–759 (2023).
Aakre, C. et al. Prospective validation of a near real-time EHR-integrated automated SOFA score calculator. Int. J. Med. Inform. 103, 1–6 (2017).
R Core Team. R: A Language and Environment for Statistical Computing (R Foundation for Statistical Computing, 2025); https://www.r-project.org/
Posit Team. RStudio: Integrated Development Environment for R (Posit Software, PBC, 2025).
Escalé-Besa, A. et al. Exploring the potential of artificial intelligence in improving skin lesion diagnosis in primary care. Sci. Rep. 13, 4293 (2023).
Rajakariar, K. et al. Accuracy of a smartwatch based single-lead electrocardiogram device in detection of atrial fibrillation. Heart 106, 665–670 (2020).
Tan, P., Nyeko-Lacek, M., Walsh, K., Sheikh, Z. & Lewis, C. J. Artificial intelligence-enhanced multispectral imaging for burn wound assessment: insights from a multi-centre UK evaluation. Burns 51, 107550 (2025).
Morse, K. E. et al. Monitoring approaches for a pediatric chronic kidney disease machine learning model. Appl. Clin. Inform. 13, 431–438 (2022).
Afshar, M. et al. Deployment of real-time natural language processing and deep learning clinical decision support in the electronic health record: pipeline implementation for an opioid misuse screener in hospitalized adults. JMIR Med. Inform. 11, e44977 (2023).
Sheppard, J. P. et al. Prospective external validation of the Predicting Out-of-OFfice Blood Pressure (PROOF-BP) strategy for triaging ambulatory monitoring in the diagnosis and management of hypertension: observational cohort study. BMJ 361, k2478 (2018).
Wong, A. I. et al. Prediction of acute respiratory failure requiring advanced respiratory support in advance of interventions and treatment: a multivariable prediction model from electronic medical record data. Crit. Care Explor. 3, e0402 (2021).
Ganapathi, S. et al. Tackling bias in AI health datasets through the STANDING Together initiative. Nat. Med. 28, 2232–2233 (2022).
Ouyang, D. et al. Video-based AI for beat-to-beat assessment of cardiac function. Nature 580, 252–256 (2020).
Razavian, N. et al. A validated, real-time prediction model for favorable outcomes in hospitalized COVID-19 patients. NPJ Digit. Med. 3, 130 (2020).
Pou-Prom, C., Murray, J., Kuzulugil, S., Mamdani, M. & Verma, A. A. From compute to care: lessons learned from deploying an early warning system into clinical practice. Front. Digit. Health 4, 932123 (2022).
Aakre, C. A., Kitson, J. E., Li, M. & Herasevich, V. Iterative user interface design for automated sequential organ failure assessment score calculator in sepsis detection. JMIR Hum. Factors 4, e14 (2017).
Brajer, N. et al. Prospective and external evaluation of a machine learning model to predict in-hospital mortality of adults at time of admission. JAMA Netw. Open 3, e1920733 (2020).
Nemeth, C. et al. TCCC decision support with machine learning prediction of hemorrhage risk, shock probability. Mil. Med. 188, 659–665 (2023).
Shelov, E. et al. Design and implementation of a pediatric ICU acuity scoring tool as clinical decision support. Appl. Clin. Inform. 9, 576–587 (2018).
Bedoya, A. D. et al. Machine learning for early detection of sepsis: an internal and temporal validation study. JAMIA Open 3, 252–260 (2020).
Artificial Intelligence/Machine Learning-enabled Working Group. Good Machine Learning Practice for medical device development: guiding principles. FDA https://www.fda.gov/medical-devices/software-medical-device-samd/good-machine-learning-practice-medical-device-development-guiding-principles (2025).
DECIDE-AI Steering Group. DECIDE-AI: new reporting guidelines to bridge the development-to-implementation gap in clinical artificial intelligence. Nat. Med. 27, 186–187 (2021).
Rivera, S. C. et al. Guidelines for clinical trial protocols for interventions involving artificial intelligence: the SPIRIT-AI extension. Lancet Digit. Health 2, e549–e560 (2020).
Liu, X. et al. Reporting guidelines for clinical trial reports for interventions involving artificial intelligence: the CONSORT-AI extension. Lancet Digit. Health 2, e537–e548 (2020).
Moher, D. Guidelines for reporting health care research: advancing the clarity and transparency of scientific reporting. Can. J. Anaesth. 56, 96–101 (2009).
Evidence standards framework for digital health technologies. Section C: evidence standards tables. NICE https://www.nice.org.uk/corporate/ecd7/chapter/section-c-evidence-standards-tables (2018).
Gaube, S. et al. Do as AI say: susceptibility in deployment of clinical decision-aids. NPJ Digit. Med. 4, 31 (2021).
Chromik, M., Eiband, M., Buchner, F., Krüger, A. & Butz, A. I think I get your point, AI! The illusion of explanatory depth in explainable AI. In 26th International Conference on Intelligent User Interfaces 307–317 (Association for Computing Machinery, 2021); https://doi.org/10.1145/3397481.3450644
Felmingham, C. M. et al. The importance of incorporating human factors in the design and implementation of artificial intelligence for skin cancer diagnosis in the real world. Am. J. Clin. Dermatol. 22, 233–242 (2021).
Tikhomirov, L. et al. Medical artificial intelligence for clinicians: the lost cognitive perspective. Lancet Digit. Health 6, e589–e594 (2024).
Park, Y. et al. Evaluating artificial intelligence in medicine: phases of clinical research. JAMIA Open 3, 326–331 (2020).
Lemmon, J. et al. Evaluation of feature selection methods for preserving machine learning performance in the presence of temporal dataset shift in clinical medicine. Methods Inf. Med. 62, 60–70 (2023).
Kelly, C. J., Karthikesalingam, A., Suleyman, M., Corrado, G. & King, D. Key challenges for delivering clinical impact with artificial intelligence. BMC Med. 17, 195 (2019).
Finlayson, S. G. et al. The clinician and dataset shift in artificial intelligence. N. Engl. J. Med. 385, 283–286 (2021).
Badgeley, M. A. et al. Deep learning predicts hip fracture using confounding patient and healthcare variables. NPJ Digit. Med. 2, 31 (2019).
Bozkurt, S. et al. Reporting of demographic data and representativeness in machine learning models using electronic health records. J. Am. Med. Inform. Assoc. 27, 1878–1884 (2020).
Plana, D. et al. Randomized clinical trials of machine learning interventions in health care: a systematic review. JAMA Netw. Open 5, e2233946 (2022).
Obermeyer, Z., Powers, B., Vogeli, C. & Mullainathan, S. Dissecting racial bias in an algorithm used to manage the health of populations. Science 366, 447–453 (2019).
McCradden, M. D., Joshi, S., Mazwi, M. & Anderson, J. A. Ethical limitations of algorithmic fairness solutions in health care machine learning. Lancet Digit. Health 2, e221–e223 (2020).
McCradden, M. et al. What’s fair is… fair? Presenting JustEFAB, an ethical framework for operationalizing medical ethics and social justice in the integration of clinical machine learning: JustEFAB. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency 1505–1519 (Association for Computing Machinery, 2023); https://dl.acm.org/doi/abs/10.1145/3593013.3594096
Gichoya, J. W. et al. AI recognition of patient race in medical imaging: a modelling study. Lancet Digit. Health 4, e406–e414 (2022).
Arora, A. et al. The value of standards for health datasets in artificial intelligence-based applications. Nat. Med. 29, 2929–2938 (2023).
McCradden, M. D. et al. What makes a ‘good’ decision with artificial intelligence? A grounded theory study in paediatric care. BMJ Evid. Based Med. 30, 183–193 (2025).
Assadi, A. et al. An integration engineering framework for machine learning in healthcare. Front. Digit. Health 4, 932411 (2022).
Militello, L. G. et al. Using human factors methods to mitigate bias in artificial intelligence-based clinical decision support. J. Am. Med. Inform. Assoc. 32, 398–403 (2025).
Campbell, N. C. et al. Designing and evaluating complex interventions to improve health care. BMJ 334, 455–459 (2007).
Aromataris, E. et al. (eds) JBI Manual for Evidence Synthesis (JBI, 2024); https://synthesismanual.jbi.global
Tricco, A. et al. PRISMA extension for scoping reviews (PRISMAScR): checklist and explanation. Ann. Intern. Med. 169, 467–473 (2018).
Breiman, L. Statistical modeling: the two cultures (with comments and a rejoinder by the author). Stat. Sci. 16, 199–231 (2001).
Covidence Systematic Review Software https://www.covidence.org (Veritas Health Innovation, 2025).
Abràmoff, M. D., Lavin, P. T., Birch, M., Shah, N. & Folk, J. C. Pivotal trial of an autonomous AI-based diagnostic system for detection of diabetic retinopathy in primary care offices. NPJ Digit. Med. 1, 39 (2018).
Tonekaboni, S. et al. How to validate machine learning models prior to deployment: silent trial protocol for evaluation of real-time models at ICU. In Proceedings of the Conference on Health, Inference, and Learning Vol. 174 (eds Flores, G. et al.) 169–182 (PMLR, 2022).
Sendak, M. et al. “The human body is a black box”: supporting clinical decision-making with deep learning. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency 99–109 (Association for Computing Machinery, 2020); https://doi.org/10.1145/3351095.3372827
Balagopalan, A. et al. Machine learning for healthcare that matters: reorienting from technical novelty to equitable impact. PLOS Digit. Health 3, e0000474 (2024).
Papoutsi, C., Wherton, J., Shaw, S., Morrison, C. & Greenhalgh, T. Putting the social back into sociotechnical: case studies of co-design in digital health. J. Am. Med. Inform. Assoc. 28, 284–293 (2021).
Alrajhi, A. A. et al. Data-driven prediction for COVID-19 severity in hospitalized patients. Int. J. Environ. Res. Public Health 19, 2958 (2022).
Aydın, E. et al. Diagnostic accuracy of a machine learning-derived appendicitis score in children: a multicenter validation study. Children (Basel) 12, 937 (2025).
Bachelot, G. et al. A machine learning approach for the prediction of testicular sperm extraction in nonobstructive azoospermia: algorithm development and validation study. J. Med. Internet Res. 25, e44047 (2023).
Berg, W. A. et al. Toward AI-supported US triage of women with palpable breast lumps in a low-resource setting. Radiology 307, e223351 (2023).
Butler, H. J. et al. Development of high-throughput ATR-FTIR technology for rapid triage of brain cancer. Nat. Commun. 10, 4501 (2019).
Campanella, G. et al. Real-world deployment of a fine-tuned pathology foundation model for lung cancer biomarker detection. Nat. Med. 31, 3002–3010 (2025).
Chen, Y. et al. Endoscopic ultrasound-based radiomics for predicting pathologic upgrade in esophageal low-grade intraepithelial neoplasia. Surg. Endosc. 39, 2239–2249 (2025).
Cheng, Y. et al. Two-year hypertension incidence risk prediction in populations in the desert regions of northwest China: prospective cohort study. J. Med. Internet Res. 27, e68442 (2025).
Chiang, D.-H., Jiang, Z., Tian, C. & Wang, C.-Y. Development and validation of a dynamic early warning system with time-varying machine learning models for predicting hemodynamic instability in critical care: a multicohort study. Crit. Care 29, 318 (2025).
Chufal, K. S. et al. Machine learning model for predicting DIBH non-eligibility in left-sided breast cancer radiotherapy: development, validation and clinical impact analysis. Radiother. Oncol. 205, 110764 (2025).
Coley, R. Y., Walker, R. L., Cruz, M., Simon, G. E. & Shortreed, S. M. Clinical risk prediction models and informative cluster size: assessing the performance of a suicide risk prediction algorithm. Biom. J. 63, 1375–1388 (2021).
Corbin, C. K. et al. DEPLOYR: a technical framework for deploying custom real-time machine learning models into the electronic medical record. J. Am. Med. Inform. Assoc. 30, 1532–1542 (2023).
Dave, C. et al. Prospective real-time validation of a lung ultrasound deep learning model in the ICU. Crit. Care Med. 51, 301–309 (2023).
El Moheb, M. et al. An open-architecture AI model for CPT coding in breast surgery: development, validation, and prospective testing. Ann. Surg. 282, 439–448 (2025).
Faqar-Uz-Zaman, S. F. et al. The diagnostic efficacy of an app-based diagnostic health care application in the emergency room: eRadaR-trial. A prospective, double-blinded, observational study. Ann. Surg. 276, 935–942 (2022).
Felmingham, C. et al. Improving Skin cancer Management with ARTificial Intelligence (SMARTI): protocol for a preintervention/postintervention trial of an artificial intelligence system used as a diagnostic aid for skin cancer management in a specialist dermatology setting. BMJ Open 12, e050203 (2022).
Feng, W. et al. Identifying small thymomas from other asymptomatic anterior mediastinal nodules based on CT images using logistic regression. Front. Oncol. 15, 1590710 (2025).
Hanley, D. et al. Emergency department triage of traumatic head injury using a brain electrical activity biomarker: a multisite prospective observational validation trial. Acad. Emerg. Med. 24, 617–627 (2017).
Hoang, M. T. et al. Evaluating the utility of a clinical sepsis AI tool in emergency waiting rooms: a preliminary silent trial. Stud. Health Technol. Inform. 329, 307–311 (2025).
Im, H. et al. Design and clinical validation of a point-of-care device for the diagnosis of lymphoma via contrast-enhanced microholography and machine learning. Nat. Biomed. Eng. 2, 666–674 (2018).
Korfiatis, P. et al. Automated artificial intelligence model trained on a large data set can detect pancreas cancer on diagnostic computed tomography scans as well as visually occult preinvasive cancer on prediagnostic computed tomography scans. Gastroenterology 165, 1533–1546 (2023).
Kramer, D. et al. Machine learning-based prediction of malnutrition in surgical in-patients: a validation pilot study. Stud. Health Technol. Inform. 313, 156–157 (2024).
Kwong, J. C. C. et al. The silent trial—the bridge between bench-to-bedside clinical AI applications. Front. Digit. Health 4, 929508 (2022).
Liu, R. et al. Development and prospective validation of postoperative pain prediction from preoperative EHR data using attention-based set embeddings. NPJ Digit. Med. 6, 209 (2023).
Liu, Y. et al. Validation of an established TW3 artificial intelligence bone age assessment system: a prospective, multicenter, confirmatory study. Quant. Imaging Med. Surg. 14, 144–159 (2024).
Luo, H. et al. Real-time artificial intelligence for detection of upper gastrointestinal cancer by endoscopy: a multicentre, case–control, diagnostic study. Lancet Oncol. 20, 1645–1654 (2019).
Lupei, M. I. et al. A 12-hospital prospective evaluation of a clinical decision support prognostic algorithm based on logistic regression as a form of machine learning to facilitate decision making for patients with suspected COVID-19. PLoS ONE 17, e0262193 (2022).
Mahajan, A. et al. Development and validation of a machine learning model to identify patients before surgery at high risk for postoperative adverse events. JAMA Netw. Open 6, e2322285 (2023).
Major, V. J. & Aphinyanaphongs, Y. Development, implementation, and prospective validation of a model to predict 60-day end-of-life in hospitalized adults upon admission at three sites. BMC Med. Inform. Decis. Mak. 20, 214 (2020).
Miró Catalina, Q. et al. Real-world testing of an artificial intelligence algorithm for the analysis of chest X-rays in primary care settings. Sci. Rep. 14, 5199 (2024).
O’Brien, C. et al. Development, implementation, and evaluation of an in-hospital optimized early warning score for patient deterioration. MDM Policy Pract. 5, 2381468319899663 (2020).
Pan, Y. et al. An interpretable machine learning model based on optimal feature selection for identifying CT abnormalities in patients with mild traumatic brain injury. EClinicalMedicine 82, 103192 (2025).
Pyrros, A. et al. Opportunistic detection of type 2 diabetes using deep learning from frontal chest radiographs. Nat. Commun. 14, 4039 (2023).
Qian, Y.-F., Zhou, J.-J., Shi, S.-L. & Guo, W.-L. Predictive model integrating deep learning and clinical features based on ultrasound imaging data for surgical intervention in intussusception in children younger than 8 months. BMJ Open 15, e097575 (2025).
Rawson, T. M. et al. Supervised machine learning to support the diagnosis of bacterial infection in the context of COVID-19. JAC Antimicrob. Resist. 3, dlab002 (2021).
Ren, L.-J. et al. Artificial intelligence assisted identification of newborn auricular deformities via smartphone application. EClinicalMedicine 81, 103124 (2025).
Schinkel, M. et al. Diagnostic stewardship for blood cultures in the emergency department: a multicenter validation and prospective evaluation of a machine learning prediction tool. EBioMedicine 82, 104176 (2022).
Shah, P. K. et al. A simulated prospective evaluation of a deep learning model for real-time prediction of clinical deterioration among ward patients. Crit. Care Med. 49, 1312–1321 (2021).
Shamout, F. E. et al. An artificial intelligence system for predicting the deterioration of COVID-19 patients in the emergency department. NPJ Digit. Med. 4, 80 (2021).
Shi, Y.-H. et al. Construction and validation of machine learning-based predictive model for colorectal polyp recurrence one year after endoscopic mucosal resection. World J. Gastroenterol. 31, 102387 (2025).
Smith, S. J., Bradley, S. A., Walker-Stabeler, K. & Siafakas, M. A prospective analysis of screen-detected cancers recalled and not recalled by artificial intelligence. J. Breast Imaging 6, 378–387 (2024).
Stamatopoulos, N. et al. Temporal and external validation of the algorithm predicting first trimester outcome of a viable pregnancy. Aust. N. Z. J. Obstet. Gynaecol. 65, 128–134 (2025).
Swinnerton, K. et al. Leveraging near-real-time patient and population data to incorporate fluctuating risk of severe COVID-19: development and prospective validation of a personalised risk prediction tool. EClinicalMedicine 81, 103114 (2025).
Tariq, A., Patel, B. N., Sensakovic, W. F., Fahrenholtz, S. J. & Banerjee, I. Opportunistic screening for low bone density using abdominopelvic computed tomography scans. Med. Phys. 50, 4296–4307 (2023).
Titano, J. J. et al. Automated deep-neural-network surveillance of cranial images for acute neurologic events. Nat. Med. 24, 1337–1341 (2018).
Vaid, A. et al. Machine learning to predict mortality and critical events in a cohort of patients with COVID-19 in New York City: model development and validation. J. Med. Internet Res. 22, e24018 (2020).
Wall, P. D. H., Hirata, E., Morin, O., Valdes, G. & Witztum, A. Prospective clinical validation of virtual patient-specific quality assurance of volumetric modulated arc therapy radiation therapy plans. Int. J. Radiat. Oncol. Biol. Phys. 113, 1091–1102 (2022).
Wan, C.-F. et al. Radiomics of multimodal ultrasound for early prediction of pathologic complete response to neoadjuvant chemotherapy in breast cancer. Acad. Radiol. 32, 1861–1873 (2025).
Wang, X. et al. Prediction of the 1-year risk of incident lung cancer: prospective study using electronic health records from the state of Maine. J. Med. Internet Res. 21, e13260 (2019).
Wang, L., Wu, H., Wu, C., Shu, L. & Zhou, D. A deep-learning system integrating electrocardiograms and laboratory indicators for diagnosing acute aortic dissection and acute myocardial infarction. Int. J. Cardiol. 423, 133008 (2025).
Wissel, B. D. et al. Prospective validation of a machine learning model that uses provider notes to identify candidates for resective epilepsy surgery. Epilepsia 61, 39–48 (2020).
Xie, Z. et al. Enhanced diagnosis of axial spondyloarthritis using machine learning with sacroiliac joint MRI: a multicenter study. Insights Imaging 16, 91 (2025).
Ye, C. et al. A real-time early warning system for monitoring inpatient mortality risk: prospective study using electronic medical record data. J. Med. Internet Res. 21, e13719 (2019).
Ye, J.-Z. et al. Nomogram for prediction of the International Study Group of Liver Surgery (ISGLS) grade B/C posthepatectomy liver failure in HBV-related hepatocellular carcinoma patients: an external validation and prospective application study. BMC Cancer 20, 1036 (2020).
Yu, S. C. et al. Sepsis prediction for the general ward setting. Front. Digit. Health 4, 848599 (2022).
Zhang, Z. et al. Development of an MRI based artificial intelligence model for the identification of underlying atrial fibrillation after ischemic stroke: a multicenter proof-of-concept analysis. EClinicalMedicine 81, 103118 (2025).
Escalé-Besa, A. et al. Using artificial intelligence as a diagnostic decision support tool in skin disease: protocol for an observational prospective cohort study. JMIR Res. Protoc. 11, e37531 (2022).
Faqar-Uz-Zaman, S. F. et al. Study protocol for a prospective, double-blinded, observational study investigating the diagnostic accuracy of an app-based diagnostic health care application in an emergency room setting: the eRadaR trial. BMJ Open 11, e041396 (2021).
Felmingham, C. et al. Improving skin cancer management with ARTificial intelligence: a pre–post intervention trial of an artificial intelligence system used as a diagnostic aid for skin cancer management in a real-world specialist dermatology setting. J. Am. Acad. Dermatol. 88, 1138–1142 (2023).
Miró Catalina, Q., Fuster-Casanovas, A., Solé-Casals, J. & Vidal-Alaball, J. Developing an artificial intelligence model for reading chest x-rays: protocol for a prospective validation study. JMIR Res. Protoc. 11, e39536 (2022).
Sheppard, J. P., Martin, U., Gill, P., Stevens, R. & McManus, R. J. Prospective Register Of patients undergoing repeated OFfice and Ambulatory Blood Pressure Monitoring (PROOF-ABPM): protocol for an observational cohort study. BMJ Open 6, e012607 (2016).
Acknowledgements
This scoping review is part of a larger study exploring and expanding considerations for silent phase evaluations of healthcare AI. The Project CANAIRI Steering Group has been involved in the design of this overall work, and we would like to thank L. Oakden-Rayner, M. Mamdani, J. Louise and L. A. Smith. No funding source supported this scoping study. M.D.McC. gratefully acknowledges salary support from The Hospital Research Foundation Group. Additional support for CANAIRI-related activities has been generously provided by the Australian Institute for Machine Learning through the Centre for Augmented Reasoning.
Funding
Open access funding provided by Adelaide University.
Author information
Authors and Affiliations
Contributions
Study design and conceptualization: M.D.McC., X.L., L.T. Methodology: M.D.McC., X.L., L.T., C.S., A.v.d.V., M.P.S., K.V., J.A.A., S.J., A.J.L., A.M., I.S., I.A., S.S., L.E., L.-A.F. Data extraction and analysis: L.T., A.M., H.T., N.C.K., G.K., S.B., N.P., A.v.d.V., L.E., L.J.P., C.S. Data interpretation and synthesis: all authors. Writing—first draft: L.T. Writing—review and editing: all authors. Project supervision: M.D.McC.
Corresponding author
Ethics declarations
Competing interests
S.R.P. is an employee of Google and may own stock as part of a standard compensation package. X.L. is an employee of Microsoft. M.P.S. is a co-inventor of software licensed from Duke University to Cohere Med, Inc., KelaHealth, Fullsteam Health and Clinetic. M.P.S. owns equity in Clinetic. M.D.McC. discloses financial support related to independent ethics consultation activities for Google Health (USA), Cephalgo and iheed. The other authors declare no competing interests.
Peer review
Peer review information
Nature Health thanks Stephen Gilbert and Pearse Keane for their contribution to the peer review of this work. Primary Handling Editor: Lorenzo Righetto, in collaboration with the Nature Health team.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary Information
Supplementary reporting guideline.
Supplementary Tables
Supplementary Tables 1–3.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tikhomirov, L., Semmler, C., Prizant, N. et al. A scoping review of silent trials for medical artificial intelligence. Nat. Health (2026). https://doi.org/10.1038/s44360-025-00048-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s44360-025-00048-z
