
Abstract
The development of the human neocortex is highly dynamic, involving complex cellular trajectories controlled by gene regulation1. Here we collected paired single-nucleus chromatin accessibility and transcriptome data from 38 human neocortical samples encompassing both the prefrontal cortex and the primary visual cortex. These samples span five main developmental stages, ranging from the first trimester to adolescence. In parallel, we performed spatial transcriptomic analysis on a subset of the samples to illustrate spatial organization and intercellular communication. This atlas enables us to catalogue cell-type-specific, age-specific and area-specific gene regulatory networks underlying neural differentiation. Moreover, combining single-cell profiling, progenitor purification and lineage-tracing experiments, we have untangled the complex lineage relationships among progenitor subtypes during the neurogenesis-to-gliogenesis transition. We identified a tripotential intermediate progenitor subtype—tripotential intermediate progenitor cells (Tri-IPCs)—that is responsible for the local production of GABAergic neurons, oligodendrocyte precursor cells and astrocytes. Notably, most glioblastoma cells resemble Tri-IPCs at the transcriptomic level, suggesting that cancer cells hijack developmental processes to enhance growth and heterogeneity. Furthermore, by integrating our atlas data with large-scale genome-wide association study data, we created a disease-risk map highlighting enriched risk associated with autism spectrum disorder in second-trimester intratelencephalic neurons. Our study sheds light on the molecular and cellular dynamics of the developing human neocortex.
Similar content being viewed by others

Main
Human neocortex development is a complex and coordinated process crucial for establishing the brain’s intricate structure and functionality. In the developing neocortex, radial glia (RGs) generate glutamatergic excitatory neurons (ENs) in a characteristic inside-out laminar pattern, with non-intratelencephalic (non-IT) neurons produced first, followed by intratelencephalic (IT) neurons1. Subsequently, ENs migrate along the RG scaffold to the cortical plate, where they differentiate and form distinct cortical layers with coordinated synaptic connections. Meanwhile, GABAergic inhibitory neurons (INs) originating in the ganglionic eminence migrate to the cortex through the marginal and germinal zones, eventually becoming cortical interneurons of the adult cortex. During the late second trimester, RGs transition from neurogenesis to gliogenesis, producing astrocytes and oligodendrocyte-lineage cells that populate the cortex. Cell-type-specific gene regulatory mechanisms that underlie cell proliferation and differentiation govern these dynamic processes. However, our understanding of these mechanisms remains incomplete.
Gene regulation involves epigenetic reprogramming and subsequent gene expression changes2. Over the past decade, single-cell transcriptome and chromatin accessibility analyses have expanded our knowledge of cellular diversity and the molecular changes that occur during human neocortical development. However, in many instances, measurements of the transcriptome and epigenome were conducted independently, limiting our understanding of how these two modalities coordinate with each other to form regulatory networks in the same cell. Recent studies explored gene-regulatory mechanisms in the developing human cortex by profiling chromatin accessibility and gene expression within the same nuclei3,4,5. However, these analyses were confined either to a restricted number of samples and cell types or to the first trimester.
Here we conducted paired RNA sequencing (RNA-seq) and assay for transposase-accessible chromatin with sequencing (ATAC–seq) analysis of single nuclei from multiple regions and age groups of the developing human neocortex. Moreover, spatial transcriptomic analysis was used to reveal cellular niches and cell–cell communication. These datasets have enabled the construction of a single-cell multi-omic atlas of the developing human neocortex. Using this atlas, we investigated the molecular and cellular dynamics of the developing human neocortex. Our findings identify multipotential IPCs and cellular trajectories and shed light on the mechanisms underlying brain cancer and neuropsychiatric disorders.
Multi-omic atlas of the developing neocortex
We collected 27 brain specimens and 38 biological samples from five key developmental stages, spanning the first trimester to adolescence, to study transcriptomic and epigenomic changes in human neocortical development (Fig. 1a and Supplementary Table 1). Samples from both the prefrontal (PFC) and primary visual (V1) cortices were included to explore regional diversity. Using the single-nucleus multiome (snMultiome) technique from 10x Genomics, we obtained paired single-nucleus ATAC–seq and RNA-seq data from 243,535 nuclei after quality control. Excluding nuclei from the diencephalon and striatum resulted in 232,328 nuclei in the final dataset (Extended Data Fig. 1a–d and Supplementary Table 2). Each nucleus yielded a median of 2,289 genes, 4,840 transcripts and 4,121 ATAC peak region fragments (Extended Data Fig. 2a).

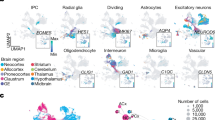
a, Description of the samples used in this study. The diagram was created using BioRender. b, UMAP plots of the snMultiome data, showing the distribution of 33 cell types. c, UMAP plots showing the distribution of age groups (left) and regions (right). d, The proportion of individual cell types across developmental stages and cortical regions. Bars are colour coded by cell types, the legend for which is shown in b. e, The expression of signature TFs in individual cell types (left). Middle, aggregated chromatin accessibility profiles at the promoter of signature TFs across cell types. The blue arrows represent each TF’s transcriptional start site and direction. Right, normalized chromVAR motif activity of signature TFs across cell types.
We performed weighted nearest-neighbour analysis6 to integrate information from the paired ATAC and RNA modalities. The resulting nearest-neighbour graph was used for uniform manifold approximation and projection (UMAP) embedding and clustering. On the basis of the established cortical cell-type references7,8 and marker genes (Extended Data Fig. 3 and Supplementary Table 3), we determined 5 classes, 11 subclasses and 33 high-fidelity cell types (Methods, Fig. 1b, Extended Data Fig. 1e and Supplementary Table 2). Cells clustered by lineage, type, age and region, with ENs, oligodendrocytes and astrocytes showing strong regional differences (Fig. 1b,c and Extended Data Fig. 2b). Combined ATAC and RNA embeddings provided better separation of cell types, age groups and regions compared with either modality alone (Extended Data Fig. 2c). Cell-type proportions varied significantly across age groups and regions (Fig. 1d and Supplementary Table 3). Progenitors and immature neurons were more abundant in the first and second trimesters but became depleted later. By contrast, upper-layer IT neurons and macroglia increased after birth. EN-L4-IT neurons were more prevalent in the V1 than in the PFC after the third trimester, aligning with the expansion of the thalamorecipient layer 4 (L4) in the V1.
To further evaluate data quality, we compared gene expression, chromatin accessibility and transcriptional regulatory activity of lineage-specific transcription factors (TFs) across cell types and found strong concordance between these attributes (Fig. 1e and Supplementary Table 4). For example, PAX6 and EMX2, two TFs that are critical for cortical progenitor specification, showed selective expression, high promoter accessibility and enriched motif activity in RGs (Fig. 1e), highlighting coordinated epigenomic and transcriptomic changes in neocortical development.
Cytoarchitecture of developing neocortex
To localize the observed cell types, we designed a 300-gene panel based on cell-type markers identified from our snMultiome data (Supplementary Table 5) and conducted spatial transcriptomic analysis using multiplexed error-robust fluorescence in situ hybridization (MERFISH)9. We analysed six PFC and V1 samples across three age groups from the second trimester to infancy (Supplementary Table 5), retaining 404,030 high-quality cells. This yielded 29 cell types with one-to-one correspondence to their counterparts in the snMultiome data from matching age groups (Fig. 2a, Extended Data Fig. 4a and Supplementary Table 6). Cell-type proportions were consistent between MERFISH and snMultiome, indicating limited sampling bias (Extended Data Fig. 4b). To define neocortical cytoarchitecture, we grouped cells into 10 niches based on their 50 closest spatial neighbours. These niches aligned with histologically established cortical domains and were named accordingly (Fig. 2a).

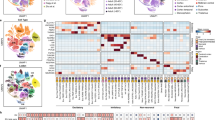
a, Spatial transcriptomic analysis of six neocortical samples. Cells are colour coded by types or the niches to which they belong. b, The proportion of different cell types in individual niches. Niche numbers correspond to the legend in a. c, The neighbourhood enrichment scores of the PFC sample at infancy. The row and column annotations are colour coded by cell types as defined a. d, The percentage of significant intercellular communication determined by NCEM identified across all datasets. The row and column annotations are colour coded by cell types, as defined in a. e, The direction of cellular interactions mediated by neuregulin signalling (left). Right, the communication probability of example ligand–receptor pairs in the neuregulin signalling pathway from EN-IT-immature to other cell types. Empty space means that the communication probability is zero. P values were calculated using one-sided permutation tests. f, The direction of cellular interactions mediated by somatostatin signalling (left). Right, the communication probability of example ligand–receptor pairs in the somatostatin signalling pathway from IN-MGE-SST to other cell types. Empty space means that the communication probability is zero. P values were calculated using one-sided permutation tests.
Different cell types exhibited distinct patterns of niche distribution. Neural progenitors were primarily localized in the ventricular/subventricular zone (VZ/SVZ), whereas mature ENs were confined to their specific cortical layers throughout development (Fig. 2b and Extended Data Fig. 5a–f). Immature interneurons in the second trimester were enriched in both the marginal zone and VZ/SVZ, two routes that they use to migrate into the cortex. At this stage, the overall ratio of migrating interneurons in the marginal zone to VZ/SVZ was 1:4.1, with a higher ratio for caudal ganglionic eminence (CGE)-derived interneurons compared with medial ganglionic eminence (MGE)-derived ones (odds ratio = 1.58, P < 2.2 × 10−16, two-sided Fisher’s exact test), indicating lineage-specific route preferences. This finding was further validated through immunostaining (Extended Data Fig. 6a,b; weighted average odds ratio = 1.56). This bias probably contributes to the laminar distribution of interneuron subtypes, with CGE-derived interneurons enriched in upper layers and MGE-derived PVALB-expressing interneurons (IN-MGE-PV) in L4–6 (Fig. 2a,b and Extended Data Fig. 5a–f). The dorsal lateral ganglionic eminence (dLGE) primarily gives rise to olfactory bulb interneurons10. Notably, we observed IN-dLGE-immature cells, a subtype of INs expressing MEIS2, SP8, TSHZ1 and PBX3, and presumably originating from the dLGE, in the white matter across all three age groups (Extended Data Fig. 5a–f). These neurons will probably constitute a subset of the white-matter interstitial interneurons in adulthood. Regarding glial cells, OPCs were evenly distributed between grey and white matter, whereas oligodendrocytes were more abundant in the white matter (Fig. 2b and Extended Data Fig. 5a–f), supporting a non-progenitor role of OPCs in cortical grey matter11.
In early neonatal and adult mammalian brains, neurogenesis continues in the VZ/SVZ of the lateral ventricles, producing mostly GABAergic interneurons that migrate to the olfactory bulb12. However, in our perinatal PFC sample, which included the VZ/SVZ, we found a large number of glutamatergic EN-newborn cells and a smaller number of IPC-ENs, specifically in the SVZ (Extended Data Fig. 5c). Notably, the count of EN-newborn cells was 10.3× higher than IN-dLGE-immature cells, the putative GABAergic interneurons for the olfactory bulb or the white matter. Whether these late-born EN-newborn cells will migrate to the cortical grey matter, the subcortical white matter or the olfactory bulb remains to be determined.
Cell–cell communication
To identify cell–cell communication in the developing human neocortex, we first evaluated the spatial proximity of cell types in each MERFISH sample through neighbourhood enrichment analysis. Different EN types were enriched in their own neighbourhoods, reflecting strong layer specificity. We also observed enrichment between specific ENs and INs, such as EN-IT-immature cells with IN-CGE-VIPs and EN-L4-IT neurons with IN-MGE-SSTs (Fig. 2c and Extended Data Fig. 7a). To determine whether the gene expression of a cell type was influenced by its proximity to a neighbouring cell type, we performed node-centric expression modelling (NCEM)13. We found strong interactions among ENs and between ENs and INs across datasets (Fig. 2d, Extended Data Fig. 7b and Supplementary Table 7). EN-IT-immature cells (sender) influenced gene expression in various IN types (receivers), and IN-MGE-SSTs (sender) affected multiple EN types (receivers).
As most MERFISH samples were collected before peak synaptogenesis, we performed ligand–receptor analysis using CellChat14 to identify potential communication mechanisms (Extended Data Fig. 7c). Neuregulin and somatostatin were identified as potential mediators between EN-IT-immature cells and IN-MGE-SSTs with INs and ENs, respectively (Fig. 2e,f and Supplementary Table 8). We explored somatostatin’s role by treating midgestational human cortical slice cultures with two receptor agonists and analysed gene expression using single-cell RNA-sequencing (scRNA-seq) (Extended Data Fig. 8a,b and Supplementary Tables 9 and 10). Gene expression changes induced by the two agonists were positively correlated in EN subtypes that were predicted to interact with IN-MGE-SSTs, but not EN-newborn cells, which were not expected to interact with IN-MGE-SSTs, demonstrating the on-target effects of the agonists (Extended Data Fig. 8c). Both agonists inhibited neuron projection development and synaptogenesis, while activating metabolic processes across EN subtypes (Extended Data Fig. 8d and Supplementary Tables 11 and 12). These results suggest that somatostatin produced from IN-MGE-SSTs regulates EN maturation, highlighting reciprocal communications between the two neuronal subclasses during cortical development.
GRNs
To establish the gene regulatory networks (GRNs) governing human neocortical development, we used SCENIC+15, which combines single-cell ATAC and gene expression data with motif discovery to infer enhancer-driven regulons (eRegulons), linking individual TFs to their respective target cis-regulatory regions and genes. We identified 582 eRegulons, with 385 transcriptional activators and 197 repressors, targeting 8,134 regions and 8,048 genes (Supplementary Table 13). We validated eRegulon target region predictions using ChIP–seq data from the human neocortex16, finding that 79% of tested TFs had higher-than-expected overlap, with 58% showing significant enrichment (Extended Data Fig. 9a and Supplementary Table 14). Predicted region-to-gene connections were also enriched in enhancer–promoter loops from 3D genome profiling17 (odds ratio = 2.47, P = 1.1 × 10−7) (Extended Data Fig. 9b and Supplementary Table 14), further supporting the validity of identified eRegulons.
We quantified eRegulon activity using AUCell18, assessing area under the curve (AUC) scores based on target region accessibility or target gene expression. As expected, activators were positively correlated with targets, and repressors showed negative correlations (Extended Data Fig. 9c). In activators, we recovered known master regulators of cortical progenitors (EMX1 and SALL1), ENs (FOXP1 and TBR1) and INs (ARX and LHX6), and identified cell-type- and age-specific eRegulons as potential lineage-determining factors (Fig. 3a, Extended Data Fig. 9d and Supplementary Table 15).

a, The minimum–maximum-normalized TF expression levels, region-based AUC scores and gene-based AUC scores of selective eRegulons across cell types. b, GRNs of selective eRegulons in three distinct cell types (RG-vRG, EN-L4-IT and IN-MGE-PV). TF nodes and their links to enhancers are individually coloured. The size and transparency of the TF nodes represent their gene expression levels in each cell type. ACC, accessibility; GEX, gene expression; R2G, region to gene. c, UMAP plots of cells belonging to EN lineages, showing the nine trajectories. Cells are colour coded by types, regions, age groups or pseudotime. d, Standardized gene-based AUC scores of six eRegulon modules along the trajectories of EN lineages. eRegulons are colour coded by neuronal trajectories. Thick, non-transparent lines represent the average AUC scores of each module in each trajectory. e, Gene Ontology enrichment analysis for target genes of individual eRegulon modules. Empty space indicates adjusted P > 0.05. Statistical analysis was performed using one-sided hypergeometric tests; nominal P values were adjusted using the Benjamini–Hochberg method. f, BPs during EN differentiation. g, Trajectories of four IT neuron lineages. h, Differentially expressed genes between V1-specific and common EN-L4-IT neurons. Statistical analysis was performed using likelihood ratio tests; nominal P values were adjusted using the Benjamini–Hochberg method. i, Representative eRegulons (activators) involved in trajectory determination at BPs. j, UMAP representation of representative eRegulons involved in trajectory determination at BPs.
Many cell-type-specific eRegulons shared target regions or genes (Extended Data Fig. 10a), such as TCF7L1 and TCF7L2 in ventricular RGs (RG-vRGs), GLIS1 and SMAD3 in EN-L4-IT neurons, MAF and PRDM1 in IN-MGE-PV neurons, PAX6 and SOX9 in astrocyte-protoplasmic cells, and OLIG2 and VSX1 in OPCs (Fig. 3b and Extended Data Fig. 10b). These cooperative TFs exhibit three modes of action: they share the same motif and binding sites (Extended Data Fig. 10c), they bind in tandem at the same enhancer (Extended Data Fig. 10d) or they target different enhancers but converge on the same target gene (Extended Data Fig. 10e,f). The cooperative sharing of regulatory targets probably serves to increase the specificity and robustness of GRNs during cortical development19,20.
Genetic programs governing EN identities
Having established GRNs, we aimed to understand how cell-type-specific eRegulons control cortical neuron differentiation. We selected EN-lineage nuclei, inferred nine differentiation trajectories from RG-vRG and calculated pseudotime values for each nucleus21 (Fig. 3c, Extended Data Fig. 11a–f and Supplementary Table 16). Except for one leading to late-stage RG, inlcuding outer RG (oRG) and truncated RG (tRG), the other eight trajectories ended in terminally differentiated ENs. Using a generalized additive model22, we analysed eRegulon activity along each trajectory, categorizing them into six modules based on temporal patterns of activity (Fig. 3d and Supplementary Table 17). Overall, all six modules exhibited distinct activity patterns along pseudotime but comparable patterns across trajectories (Fig. 3d). Modules active at the early, intermediate and late stages, respectively, promoted cell division, morphogenesis and synaptic plasticity (Fig. 3e and Supplementary Table 17). These findings highlight that most eRegulons demonstrate conserved activity across EN types, governing shared cellular processes during neuronal differentiation.
We next explored gene regulatory mechanisms defining EN identities, pinpointing five bifurcation points (BPs) along eight trajectories (Fig. 3f). Notably, EN-L4-IT neurons diverged into two trajectories based on their region of origin (Fig. 3c,f), with V1-specific EN-L4-IT neurons branching at BP2 to follow EN-L2–3-IT, whereas PFCs and V1-shared EN-L4-IT neurons overlapped with EN-L5-IT cells (Fig. 3f,g). Differential gene expression analysis identified 1,908 genes distinguishing V1-specific from common EN-L4-IT neurons (Fig. 3h, Extended Data Fig. 12a,b and Supplementary Table 18). We next examined the expression patterns of top differentially expressed genes using in situ hybridization (ISH) data from the Allen Brain Atlas, confirming that CUX1 and KCNIP1 were enriched in L4 of the V1, and KCNAB1 was prevalent in L4 of the secondary visual cortex (V2) (Extended Data Fig. 12c). Moreover, both V1-specific and common EN-L4-IT neurons expressed markers of their counterparts recently reported in the adult human cortex8 (Extended Data Fig. 12d). These findings highlight the unique developmental trajectory of V1-specific EN-L4-IT neurons.
To identify eRegulons associated with lineage bifurcation, we segmented trajectories into five parts and conducted differential eRegulon activity analysis at each BP (Methods and Extended Data Fig. 11g). Top-ranked differentially active eRegulons included well-established TFs crucial for identity, such as CUX2 for upper-layer IT neurons, FEZF2 for non-IT neurons and NR4A2 for EN layer 6b (EN-L6b) neurons (Fig. 3i and Supplementary Table 19). Additionally, we identified putative regulators, including POU3F1 for IT neurons, SMAD3 for upper-layer IT neurons and CUX1 for V1-specific EN-L4-IT neurons (Fig. 3i,j and Extended Data Fig. 11h). These results reveal genetic programs driving the divergence of EN identities.
Lineage potential of glial progenitors
Between gestational week 18 (GW18) and GW26, RGs in the human neocortex gradually transition from neurogenesis to gliogenesis23. However, gliogenesis in the human neocortex is less understood than neurogenesis. In the snMultiome dataset, we identified ten different cell types within the macroglia lineage, including three RG types, IPC-glia, and other cell types associated with astrocyte or oligodendrocyte lineages (Extended Data Fig. 13a,b). Among them, EGFRhighOLIG2+ IPC-glia have been previously reported by us and others as pre-OPC24, pri-OPC25, mGPC5, bMIPC26, gIPC27 or GPC28 in humans. A similar cell type has been noted in mice as pri-OPC29, tri-IPC30 or bMIPC31. Human IPC-glia can produce OPCs24 and astrocytes28. Moreover, genetic labelling experiments in mice suggest their additional potential to produce olfactory bulb interneurons30,31. Despite this progress, debates remain regarding the origin and lineage potential of human glial progenitors, especially in the late second trimester.
To address this uncertainty, we leveraged our snMultiome data collected between GW20 and GW24 and explored the expression patterns of surface protein markers (Extended Data Fig. 13c,d). We identified five proteins of which the combinatorial expression distinguishes different glial cell types in the late second trimester (Fig. 4a and Extended Data Fig. 13e). Using tissue dissection, surface staining and fluorescence-activated cell sorting, we isolated four glial progenitors—RG-tRGs, RG-oRGs, IPC-glia and OPCs (Fig. 4b and Extended Data Fig. 13f)—from late second-trimester human cortex. After 5 days in basal medium without growth factors, RG-tRGs and RG-oRGs appear unipolar, featuring a large soma and a long process akin to the radial fibre, whereas IPC-glia were mostly bipolar or oligopolar with shorter processes (Fig. 4b). OPCs displayed a bushy morphology, indicating differentiation into premyelinating oligodendrocytes. Most cells in the OPC culture died within 8 days, consistent with their dependence on growth factors28. Thus, our subsequent analysis focused on RG-tRGs, RG-oRGs and IPC-glia. We validated cell identities by immunostaining on day one in vitro (DIV1) (Extended Data Fig. 14a–e). RG-tRGs and RG-oRGs expressed progenitor marker TFAP2C, with CRYAB specifically in RG-tRGs. IPC-glia were positive for OLIG2 and EGFR. Few cells across all cultures expressed the EN marker NeuN, astrocyte marker SPARCL1 or IN marker DLX5. Moreover, few cells were OLIG2+ only, suggesting minimum contamination from OPCs or oligodendrocytes.

a, The expression patterns of surface proteins used for progenitor isolation. b, Schematic of the sorting strategy for isolation of progenitor subtypes (left). Right, phase-contrast images of progenitor subtypes after 5 days in culture. iSVZ, inner SVZ; oSVZ, outer SVZ; CP and SP, cortical plate and subplate. The diagram was created using BioRender. Scale bar, 50 μm. c, The proportion of individual cell types across progenitor subtypes and differentiation stages during progenitor differentiation in vitro. d, Clonal analysis demonstrating multipotency of individual progenitor cells. n = 26, 29 and 22 clones across three independent experiments. Scale bar, 100 μm. e, Immunostaining of descendants of Tri-IPCs 12 weeks after transplantation into mouse cortex, demonstrating the presence of astrocytes (GFAP+), OPCs or oligodendrocytes (SOX10+), and INs (GABA+). n = 2 injections. HNA, human nuclear antigen. The diagram was created using BioRender. Scale bar, 10 μm. f, SingleCellNet-predicted identities of INs and astrocytes derived from Tri-IPCs. g, Graphical summary of cell lineage relationships in late second-trimester human neocortex. The diagram was created using BioRender. h, UMAP plots of malignant GBM cells colour coded by SingleCellNet-predicted cell types. i, UMAP plots of malignant GBM cells colour coded by their main cellular states. j, The proportion of predicted cell types across different cellular states in malignant GBM cells. The legend is shown in h.
After validating our isolation strategy, we allowed cells to differentiate without growth factors for 14 days and performed scRNA-seq at DIV0, DIV7 and DIV14 to track differentiation (Extended Data Fig. 15a and Supplementary Table 20). Cells clustered in the UMAP based on differentiation stage, seeding cell type and identity (Extended Data Fig. 15b–d), revealing ten distinct cell types (Methods and Extended Data Fig. 15d,e), which closely matched in vivo populations from snMultiome data (Extended Data Fig. 15f and Supplementary Table 21). Data from DIV0 confirmed the identities of sorted cells (Fig. 4c and Extended Data Fig. 15g). At DIV7, three types of descendants emerged in the IPC-glia culture—astrocytes (9.4%), OPCs (1.1%) and IN lineage cells, namely DLX5+BEST3+ IPC-INs (26.2%) and DLX5+BEST3− INs (19.9%) (Fig. 4c and Extended Data Fig. 15e,g). Thus, we renamed IPC-glia to Tri-IPC to highlight their tripotency. The low OPC proportion (1.1% on DIV7 and 1.8% on DIV14) could be attributed to missing growth factors required for their survival. By contrast, RG-tRGs and RG-oRGs differentiated into IPC-ENs at DIV7 and ENs by DIV14, indicating that they continue to produce ENs into the late second trimester (Fig. 4c and Extended Data Fig. 15g). Tri-IPCs also appeared in RG cultures by DIV7 (3.0% and 6.3%), alongside small proportions of IPC-INs (1.0% and 3.0%) but not INs. By DIV14, astrocytes (0.7% and 1.8%), OPCs (1.5% and 1.8%) and INs (5.4% and 9.1%) were all present (Fig. 4c and Extended Data Fig. 15g). The delayed appearance of INs from RG cultures was consistent with our recent report that oRGs can produce INs32, but provided additional evidence that they do so indirectly through Tri-IPCs. Immunostaining further validated these results (Extended Data Fig. 14f–j).
The lineage-tracing experiments described so far were conducted at the population level. To assess the lineage potential of glial progenitors at the single-cell level, we isolated individual RG-tRGs, RG-oRGs and Tri-IPCs and cultured them for 14 days to produce clonal descendants. About 30% of RG-tRG and RG-oRG clones contained both IPC-ENs and Tri-IPCs, illustrating that individual RGs generate both cell types (Fig. 4d and Supplementary Table 22). Around 80% of Tri-IPC clones produced astrocytes, OPCs and INs, confirming their tripotential nature (Fig. 4d and Supplementary Table 22). When transplanted onto cultured human cortical slices ex vivo, RGs predominantly produced IPC-ENs within 8 days, whereas Tri-IPCs produced astrocytes, OPCs and INs (Extended Data Fig. 16a–e), consistent with the in vitro findings. To assess Tri-IPC potential in vivo, we transplanted them into early postnatal immunodeficient mice (Extended Data Fig. 16f). After 12 weeks, Tri-IPCs generated GFAP+ astrocytes, SOX10+ oligodendrocyte lineage cells and GABA+ INs in deep cortical layers, white matter and SVZ (Fig. 4e and Extended Data Fig. 16g,h). These results confirm that Tri-IPCs are tripotential neural progenitor cells.
To identify the IN subtypes produced by Tri-IPCs, we used scRNA-seq data from the human ganglionic eminence as a reference33 and annotated interneuron subtypes based on known marker genes34 (Extended Data Fig. 17a,b). A random-forest classifier using SingleCellNet35 based on this reference revealed that Tri-IPC-derived INs closely resemble MEIS2+PAX6+ INs from dLGE and CGE (Fig. 4f), consistent with their mapping to IN-dLGE-immature neurons in snMultiome data (Extended Data Fig. 15f). These cells were also SP8+SCGN+ and were projected to develop into olfactory-bulb and white-matter interneurons34. Our MERFISH data further support this, showing Tri-IPCs and IN-dLGE-immature cells in the white matter of prenatal and postnatal telencephalon (Extended Data Fig. 5a–f) and suggest that some IN-dLGE-immature cells may originate from Tri-IPCs. We renamed them neocortex and dorsal ganglionic eminence-derived immature INs (IN-NCx_dGE-immature) to reflect their broader origin. Similar results were obtained with nearest-neighbour-based label transfer using Seurat (Fig. 4f and Extended Data Fig. 17c,d). Moreover, we aimed to categorize the types of astrocytes derived from Tri-IPCs. We also classified astrocytes from Tri-IPCs, referencing mouse scRNA-seq36 and our snMultiome data (Extended Data Fig. 17e,f,i,j). Tri-IPC-derived astrocytes mapped to both Olig2 (protoplasmic) and S100a11 (fibrous) lineages (Fig. 4f and Extended Data Fig. 17g,h,k,l). These findings led us to propose an updated model of human neural progenitor lineage potential in the late second trimester (Fig. 4g).
GBM cells resemble Tri-IPCs
Tri-IPCs produce neurons, oligodendrocyte lineage cells and astrocytes, all considered to be important components of glioblastoma (GBM)37. Previous studies have also identified glial-progenitor-cell-like populations in malignant GBM cells27,29,38. We leveraged our developmental atlas and trained a multiclass classifier for cell type assignment using SingleCellNet35. We then used the trained model to match malignant GBM cells to their closest counterparts in the developing cortex. Our analysis revealed that over half of malignant GBM cells transcriptionally resemble Tri-IPCs (Fig. 4h–j). Moreover, Tri-IPC was the most abundant mapped cell type across all four tumour cell states defined previously37 (Fig. 4j), present in 87% of all GBM samples (Extended Data Fig. 17m). The second most abundant cell type is vascular, probably corresponding to the glial-like wound-response state39 (Fig. 4j). Other prominent cell types in GBM include OPC, oligodendrocyte-immature, astrocyte-fibrous and IN-NCx_dGE-immature (Fig. 4j), all potential Tri-IPC descendants. These results suggest that GBM cells hijack Tri-IPC multipotency and proliferation to drive tumour heterogeneity and rapid growth.
Cell-type relevance to cognition and diseases
Leveraging the chromatin accessibility data, we applied SCAVENGE40 to map genome-wide association study (GWAS) variants to their relevant cellular context. Specifically, this algorithm quantifies the enrichment of GWAS variants within accessible regions and addresses the sparsity of single-cell profiles through network propagation. The enrichment strength was quantified by trait-relevance scores (TRSs) at the single-cell level and the proportion of significantly enriched cells at the cell-group level. Using this approach, we analysed four cognitive traits and five neuropsychiatric disorders (Supplementary Table 23). For cognitive traits, fluid intelligence and processing speed were associated with IT neurons, aligning with findings in the adult human brain41 (Fig. 5a,c). Moreover, we were surprised to observe an association between RGs and executive function, as well as between microglia and working memory (Fig. 5a,c). The exact mechanisms underlying these associations remain to be elucidated. Regarding psychiatric disorders, all exhibited significant associations with ENs (Fig. 5b,c). Bipolar disorder (BPD), schizophrenia (SCZ) and attention-deficit/hyperactivity disorder (ADHD), but not autism spectrum disorder (ASD) or major depressive disorder (MDD), were additionally linked to INs (Fig. 5b,c). Notably, some of the strongest associations were found between ASD and specific IT types (EN-IT-immature and EN-L6-IT neurons). As a control, we analysed Alzheimer’s disease, which is known to have a strong heritability component in microglia42,43. We observed the strongest enrichment in microglia, with significant enrichment also in vascular cells and astrocytes (Extended Data Fig. 18a,b), consistent with their involvement in Alzheimer’s disease44,45.

a, Standardized per-cell SCAVENGE TRS for four cognitive functions. b, Standardized per-cell SCAVENGE TRS for five brain disorders, including ASD, MDD, BPD, ADHD and SCZ. c, The proportion of cells with enriched trait relevance across cell types. Tiles with significant TRS enrichment (two-sided hypergeometric test, *FDR-adjusted P < 0.01 and odds ratio > 1.4) are annotated by their odds ratios. d, Standardized SCAVENGE TRS of four brain disorders plotted along the IT neuron lineage pseudotime. The best-fitted smoothed lines indicate the average TRS and the 95% confidence interval in each pseudotime bin. e, Standardized gene-based AUC scores for top ten disease-relevant eRegulons (activators) ranked by Spearman’s ρ along the IT neuron lineage pseudotime. eRegulons with SFARI ASD-associated genes as core TFs are highlighted in red. For the box plots in a,b, the centre line shows the median, the box limits show the 25th and 75th percentiles, and the whiskers show the standard error. For a,b, statistical analysis was performed using two-sided hypergeometric tests; *FDR-adjusted P < 0.01 and odds ratio > 1.4.
In addition to cell types, we compared trait associations among brain regions and age groups, revealing that differences between age groups were more pronounced (Extended Data Fig. 18c–f and Supplementary Table 24). For example, ASD risk peaked in the second trimester, and BPD and SCZ peaked in infancy (Extended Data Fig. 18e,f). Given the predominant risk enrichment in ENs (Fig. 5b,c), we postulated that they target distinct stages of EN differentiation. To test this, we selected EN-lineage cells and examined the patterns of TRSs along their pseudotime (Fig. 5d). Indeed, ASD showed the earliest TRS peak, followed by MDD, BPD and SCZ. This pattern is consistent with the earlier onset of ASD compared to the other disorders and explains why previous ASD heritability analyses in the adult brain found only a modest signal in ENs41. To pinpoint potential GRNs disrupted by risk variants during EN differentiation, we identified eRegulons whose activity was positively correlated with the TRSs for each condition (Fig. 5e and Supplementary Table 25). Among the core TFs of the top ten eRegulons correlated with ASD, six were recognized as ASD-risk genes in the SFARI gene database46. Together, our analysis not only pinpoints the most relevant cell types and developmental stages for cognitive traits and brain disorders but also elucidates potential disease mechanisms.
Discussion
Our data collectively establish a multi-omic atlas of the developing human neocortex at single-cell resolution, providing insights into diverse aspects of brain development, including cellular composition, spatial organization, GRNs, lineage potential and susceptibility to diseases. By combining spatial and snMultiome data, we further elucidate intricate cell–cell communication networks during development, emphasizing robust interactions between EN and IN subclasses.
The V1 in humans and other binocular mammals has a specialized layer 4 that receives thalamic inputs. Recent studies identified a distinct population of EN-L4-IT neurons unique to the V18, but their developmental mechanisms were unclear. Our results show that common and V1-specific EN-L4-IT neurons follow a shared trajectory until the third trimester, then diverge. After this divergence, common EN-L4-IT neurons continue to share a trajectory with EN-L5-IT, while V1-specific EN-L4-IT neurons align more closely with EN-L2_3-IT cells. We identified TFs and regulatory networks guiding the differentiation of V1-specific EN-L4-IT and other neuronal subtypes. These factors could serve as a basis for the development of layer- and area-specific cortical models.
Recent studies, including ours, demonstrate that human cortical RGs in the second trimester produce LGE- and CGE-like INs, which share a lineage with ENs32,47. Here we found that cortical RGs generate INs through Tri-IPCs, which also produce oligodendrocytes and astrocytes. Tri-IPCs, probably analogous to bMIPCs found in mice31 and proposed in humans26, emerge after GW18, potentially due to increased sonic hedgehog signalling30. The involvement of Tri-IPCs in GBM is another interesting observation and helps to explain how GBM cells maintain their stemness and achieve heterogeneity. Most Tri-IPC-derived INs resemble MEIS2+PAX6+ INs, typically thought to originate from the dLGE34. These INs also appear in scRNA-seq data from the CGE33 and in dorsally patterned human cerebral organoids, especially during later stages32. We therefore renamed these neurons as IN-NCx_dGE-immature to reflect their broader origin from both the cortical germinal zone and adjacent ganglionic eminence. INs from bMIPCs in mice differentiate into olfactory bulb neurons31, and our spatial transcriptomic data indicate that IN-NCx_dGE-immature cells may become white-matter interneurons. Further investigation is needed to determine whether they also contribute to the repertoire of cortical interneurons.
The mechanisms underlying neuropsychiatric disorders, largely driven by common non-coding variants, remained unclear owing to the lack of detailed cell-type-resolved epigenomic data from the developing human brain. Leveraging our single-cell multi-omic atlas, we demonstrate that common variants associated with ASD are significantly enriched in IT neurons during the second trimester. This finding reinforces the midgestational origins of ASD and underscores the critical role of IT neuronal connectivity in its development. Our analysis extends beyond ASD and reveals temporal- and cell-type-specific risk patterns associated with multiple brain disorders. ASD shows the earliest risk, followed by MDD, then BPD and SCZ. These findings highlight the importance of studying normal brain development to understand disease-related deviations.
Methods
Brain tissue samples
Human brain tissue samples (Supplementary Tables 1 and 5) were acquired from four sources.
Four de-identified first-trimester human tissue samples were collected from the Human Developmental Biology Resource (HDBR), staged using crown-rump length, dissected and snap-frozen on dry ice.
Thirteen de-identified second-trimester human tissue samples were collected at the Zuckerberg San Francisco General Hospital (ZSFGH). Acquisition of second-trimester human tissue samples was approved by the UCSF Human Gamete, Embryo and Stem Cell Research Committee (10-05113). All experiments were performed in accordance with protocol guidelines. Informed consent was obtained before sample collection and use for this study.
Two de-identified third-trimester and early postnatal tissue samples were obtained at the UCSF Pediatric Neuropathology Research Laboratory (PNRL) led by E.J.H. These samples were acquired with patient consent in strict observance of the legal and institutional ethical regulations and in accordance with research protocols approved by the UCSF IRB committee. These samples were dissected and snap-frozen either on a cold plate placed on a slab of dry ice or in isopentane on dry ice.
Twenty-three de-identified third-trimester, early postnatal and adolescent tissue samples without known neurological disorders were obtained from the University of Maryland Brain and Tissue Bank through NIH NeuroBioBank.
A list of the samples used for single-nucleus multiome analysis is provided in Supplementary Table 1, and a list of the samples that were used for spatial transcriptomic analysis is provided in Supplementary Table 5.
Animals
Mouse experiments were approved by UCSF Institutional Animal Care and Use Committee (IACUC) and performed in accordance with relevant institutional guidelines. Mice were housed under a standard 12 h–12 h light–dark cycle with humidity between 30 and 70% and temperature between 68 and 79 °F.
Nucleus isolation and generation of snMultiome data
A detailed protocol was reported previously48. All of the procedures were done on ice or at 4 °C. In brief, frozen tissue samples (20–50 mg) were homogenized using a pre-chilled 7 ml Dounce homogenizer containing 1 ml cold homogenization buffer (HB) (20 mM Tricine-KOH pH 7.8, 250 mM sucrose, 25 mM KCl, 5 mM MgCl2, 1 mM dithiothreitol, 0.5 mM spermidine, 0.5 mM spermine, 0.3% NP-40, 1× cOmplete protease inhibitor (Roche), and 0.6 U ml−1 RiboLock (Thermo Fisher Scientific)). The tissue samples were homogenized 10 times with the loose pestle and 15 times with the tight pestle. Nuclei were pelleted by centrifuging at 350g for 5 min, resuspended in 25% iodixanol solution, and loaded onto 30% and 40% iodixanol layers to make a gradient. The gradient was centrifuged at 3,000g for 20 min. Clean nuclei were collected at the 30–40% interface and diluted in wash buffer (10 mM Tris-HCl pH 7.4, 10 mM NaCl, 3 mM MgCl2, 1 mM dithiothreitol, 1% BSA, 0.1% Tween-20, and 0.6 U ml−1 RiboLock (Thermo Fisher Scientific)). Next, nuclei were pelleted by centrifuging at 500g for 5 min and resuspended in diluted nucleus buffer (10x Genomics). Nuclei were counted using a haemocytometer, diluted to 3,220 nuclei per μl, and further processed according to the 10x Genomics Chromium Next GEM Single Cell Multiome ATAC + Gene Expression Reagent Kits user guide. We targeted 10,000 nuclei per sample per reaction. Libraries from individual samples were pooled and sequenced on the NovaSeq 6000 sequencing system, targeting 25,000 read pairs per nucleus for ATAC and 25,000 read pairs for RNA.
snMultiome data pre-processing
The raw sequencing signals in the BCL format were demultiplexed into fastq format using the mkfastq function in the Cell Ranger ARC suite (v.2.0.0, 10x Genomics). The Cell Ranger-ARC count pipeline was implemented for cell barcode calling, read alignment and quality assessment using the human reference genome (GRCh38, GENCODE v32/Ensembl98) according to the protocols described by 10x Genomics. The pipeline assessed the overall quality to retain all intact nuclei from the background and filtered out non-nucleus-associated reads. All gene expression libraries in this study showed a high fraction of reads in nuclei, indicating high RNA content in called nuclei and minimal levels of ambient RNA detected. The overall summary of data quality for each sample is listed in Supplementary Table 1. We next further assessed the data at the individual-nucleus level and retained high-quality nuclei with the following criteria: (1) gene expression count (nCount_RNA) is in the range of 1,000 to 25,000; (2) the number of detected genes (nFeature_RNA) is greater than 400; (3) the total ATAC fragment count in the peak regions (atac_peak_region_fragments) is in the range of 100 to 100,000; (4) the transcription start site (TSS) enrichment score for ATAC–seq is greater than 1; and (5) the strength of nucleosome signal (the ratio of mononucleosome to nucleosome-free fragments) is below 2. To ensure that only single nuclei were analysed, we measured the doublet probability by Scrublet49 and excluded all potential doublets receiving a score greater than 0.3 for downstream analyses. In total, 243,535 nuclei that passed all of the quality control criteria were included for further analysis.
snMultiome data integration, dimensionality reduction, clustering and cell-type identification
For ATAC data of snMultiome analysis, open chromatin region peaks were called on individual samples using MACS2 (v.2.2.7)50. Peaks from all samples were unified into genomic intervals, and the intervals falling in the ENCODE blacklisted regions were excluded51. Among all 398,512 processed ATAC peaks, the top 20% of consensus peaks (n = 82,505) across all nuclei were selected as variable features for downstream fragment counting and data integration. The peak-by-nucleus counts for each sample were integrated by reciprocal latent semantic indexing (LSI) projection functions using the R package Signac (v.1.10.0)52. For RNA-seq data, normalization and data scaling were performed using SCTransform v2 (v.0.4.1)53 in Seurat (v.4)6. The cell cycle difference between the G2M and S phase for each nucleus was scored and regressed out before data integration. The transformed gene-by-nucleus data matrices for all nuclei passing quality control were integrated by reciprocal PCA projections between different samples using Seurat v.4 following the best practice described previously52,54.
Weighted nearest-neighbour analysis was done using Seurat v.4 with 1–50 principal components and 2–40 LSI components. The resulting nearest-neighbour graph was used to perform UMAP embedding and clustering using the SLM algorithm55. Clusters with known markers expressed in the striatum (ISL1 and SIX3) and diencephalon (OTX2 and GBX2) were discarded. Moreover, clusters with both transcripts present in neurites (NRGN) and oligodendrocyte processes (MBP), probably due to debris contamination, were discarded. These filtering steps resulted in 232,328 nuclei in the final dataset (Extended Data Fig. 1 and Supplementary Table 2). Weighted nearest neighbour, dimension reduction and clustering were recalculated using the filtered data. Cell identities were determined based on the expression of known marker genes, as is shown in Extended Data Fig. 3 and Supplementary Table 3. The five identified classes were progenitors, neurons, glia, immune cells and vascular cells. The 11 identified subclasses were RGs, intermediate progenitor cell for ENs (IPC-EN), glutamatergic neurons, GABAergic neurons, intermediate progenitor cell for glia (IPC-glia), astrocytes, oligodendrocyte precursor cells (OPCs), oligodendrocytes, Cajal–Retzius cells, microglia and vascular cells. The 33 identified cell types were ventricular RGs (RG-vRG), truncated RGs (RG-tRG), outer RGs (RG-oRG), IPC-EN, newborn ENs (EN-newborn), immature IT neurons (EN-IT-immature), layer 2–3 (L2–3) IT neurons (EN-L2_3-IT), L4 IT neurons (EN-L4-IT), L5 IT neurons (EN-L5-IT), L6 IT neurons (EN-L6-IT), immature non-IT neurons (EN-non-IT-immature), L5 extratelencephalic neurons (EN-L5-ET), L5–6 near-projecting neurons (EN-L5_6-NP), L6 corticothalamic neurons (EN-L6-CT), EN-L6b, dorsal lateral ganglionic eminence-derived immature INs (IN-dLGE-immature), caudal ganglionic eminence-derived immature INs (IN-CGE-immature), VIP INs (IN-CGE-VIP), SNCG INs (IN-CGE-SNCG), LAMP5 INs (IN-mix-LAMP5), medial ganglionic eminence-derived immature INs (IN-MGE-immature), SST INs (IN-MGE-SST), PVALB INs (IN-MGE-PV), IPC-glia), immature astrocytes (astrocyte-immature), protoplasmic astrocytes (astrocyte-protoplasmic), fibrous astrocytes (astrocyte-fibrous), OPCs, immature oligodendrocytes (oligodendrocyte-immature), oligodendrocytes, Cajal–Retzius cells, microglia and vascular cells.
Cell-type proportion analysis
The investigation of variations in cell-type proportions across different age groups and brain regions was conducted using a linear model approach implemented in the R packages speckle (v.1.2.0)56 and limma (v.3.58.1)57. To determine changes in cell-type proportions over time, we logit-transformed the proportions within each sample and fitted a linear model (~log2[age] + region) using limma. Moreover, to address the potential correlation among samples from the same individual, the duplicateCorrelation function in limma was applied. Once the model was fit, a moderated t-test with empirical Bayes shrinkage was used to test the statistical significance of the log2[age] coefficient for each cell type. To determine cell-type proportion differences between the PFC and V1, a similar analysis was performed, but only samples in the third trimester and older were used. Cell types with Benjamini–Hochberg adjusted P < 0.05 were determined to be significant (Supplementary Table 3).
TF motif enrichment analysis
The per-cell regulatory activities of TFs were quantified by chromVAR (v.1.16.0)58. In brief, peaks were combined by removing any peaks overlapping with a peak with a greater signal, and only peaks with a width greater than 75 bp were retained for motif enrichment analysis. We computed the per-cell enrichment of curated motifs from the JASPAR2020 database59. In total, 633 unique human transcriptional factors were assigned to their most representative motifs. The per-cell-type transcriptional activity of each TF was represented by averaging the per-cell chromVAR scores within the cell type, and the cell-type-specific TFs were chosen for further analysis and visualization (Supplementary Table 4).
Spatial transcriptomic analysis using MERFISH
Spatial transcriptomic analysis using MERFISH was performed using the Vizgen MERSCOPE platform. We designed a customized 300-gene panel composed of cell-type markers (Supplementary Table 5b) using online tools (https://portal.vizgen.com/). Fresh-frozen human brain tissue samples were sectioned at a thickness of 10 µm using a cryostat and mounted onto MERSCOPE slides (Vizgen). The sections were fixed with 4% formaldehyde, washed three times with PBS, photobleached for 3 h and stored in 70% ethanol for up to 1 week. Hybridizations with gene probes were performed at 37 °C for 36–48 h. Next, the sections were fixed using formaldehyde and embedded in a polyacrylamide gel. After gel embedding, the tissue samples were cleared using a clearing mix solution supplemented with proteinase K for 1–7 days at 37 °C until no visible tissue was evident in the gel. Next, the sections were stained for DAPI and poly(T) and fixed with formaldehyde before imaging. The imaging process was performed on the MERSCOPE platform according to the manufacturer’s instructions. Cell segmentation was performed using the Watershed algorithm based on seed stain (DAPI) and watershed stain (poly(T)).
MERFISH data integration, dimensionality reduction, clustering, cell-type assignment and niche analysis
Standard MERSCOPE output data were imported into Seurat (v.5)60. We retained high-quality cells with the following criteria: (1) cell volume is greater than 10 µm3; (2) gene expression count (nCount_Vizgen) is in the range of 25 to 2,000; (3) the number of detected genes (nFeature_ Vizgen) is greater than 10. Normalization, data scaling and variable feature detection were performed using SCTransform v.2 (v.0.4.1)53. The transformed gene-by-cell data matrices for all cells passing quality control were integrated by reciprocal PCA projections between samples using 1–30 principal components. After integration, nearest-neighbour analysis was performed with 1–30 principal components. The resulting nearest-neighbour graph was used to perform UMAP embedding and clustering using the Louvain algorithm61. Clusters with markers known to be mutually exclusive were deemed doublets and discarded. These filtering steps resulted in 404,030 cells in the final dataset (Supplementary Table 6). The identity of specific cell types was determined based on the expression of known marker genes, as is shown in Extended Data Fig. 4b. Niches were identified by k-means clustering cells based on the identities of their 50 nearest spatial neighbours.
Frozen section staining to quantify the distribution of INs
GW23–24 human cortical samples were fixed in 4% paraformaldehyde (PFA) in PBS at 4 °C overnight. The samples were cryoprotected in 15% and 30% sucrose in PBS and frozen in OCT. The samples were sectioned at a thickness of 16 µm, air-dried and rehydrated in PBS. Antigen retrieval was performed using citrate-based antigen unmasking solution (Vector Laboratory) at 95 °C for 15 min. The slides were then washed in PBS and blocked in PBS-based blocking buffer containing 10% donkey serum, 0.2% gelatin and 0.1% Triton X-100 at room temperature for 1 h. After blocking, the slides were incubated with primary antibodies in the blocking buffer at 4 °C overnight. The slides were washed in PBS and 0.1% Triton X-100 (PBST) three times and incubated with secondary antibodies in the blocking buffer at room temperature for 2 h. The slides were then washed in PBST three times as described above, counterstained with DAPI and washed in PBS once more. The slides were mounted with coverslips using ProLong Gold (Invitrogen). Confocal tiled images were acquired on the Zeiss LSM900 microscope using a 20× air objective. Acquired images were processed using Imaris v.9.7 (Oxford Instruments) and ImageJ v.1.5462. The following antibodies were used: NR2F2 (Abcam, ab211777, 1:250) and LHX6 (Santa Crux, sc-271433, 1:250).
Neighbourhood enrichment and intercellular communication modelling
To evaluate the spatial proximity of cell types in each sample, we obtained a neighbourhood enrichment z-score using the nhood_enrichment function from Squidpy (v.1.2.3)63. The graph neural-network-based NCEM (v.0.1.4) method13 was used for intercellular communication modelling (Supplementary Table 7). A node-centric linear expression analysis was implemented to predict gene expression states from both cell-type annotations and the surrounding neighbourhood of each cell, where dependencies between sender and receiver cell types were constrained by the connectivity graph with a mean number of neighbours around 10 for each cell within each sample. One exception is that sample ARKFrozen-65-V1 was randomly downsampled to 60,000 cells to ensure that it has a similar neighbourhood size to other samples. Significant interactions were called if the magnitude of interactions (the Euclidean norm of coefficients in the node-centric linear expression interaction model) was above 0.5 and at least 25 differentially expressed genes (q < 0.05 for specific sender–receiver interaction terms) were detected. For visualization purposes, only significant interactions were plotted in circular plots.
Quantification of ligand–receptor communication using CellChat
We implemented CellChat (v.1.6.1)14 to quantify the strength of interactions among cell types using the default parameter settings (Supplementary Table 8). After normalization, the batch-corrected gene expression data from all 232,328 nuclei were taken as the CellChat input. We considered all curated ligand–receptor pairs from CellChatDB, where higher expression of ligands or receptors in each cell type was identified to compute the probability of cell-type-specific communication at the ligand–receptor pair level (refer to the original publication for details). We filtered out the cell–cell communication if less than ten cells in the outgoing or incoming cell types expressing the ligand or receptor, respectively. The computed communication network was then summarized at the signalling pathway level and was aggregated into a weighted-directed graph by summarizing the communication probability. The calculated weights represent the total interaction strength between any two cell types. The statistically significant ligand–receptor communications between the two groups were determined by one-sided permutation tests, where P < 0.05 was considered to be considered significant.
Organotypic slice culture and treatment with somatostatin receptor agonists
Primary cortical tissue from GW16–24 was maintained in artificial cerebrospinal fluid (ACSF) containing 110 mM choline chloride, 2.5 mM KCl, 7 mM MgCl2, 0.5 mM CaCl2, 1.3 mM NaH2PO4, 25 mM NaHCO3, 10 mM d-(+)-glucose and 1× penicillin–streptomycin. Before use, ACSF was bubbled with 95% O2/5% CO2. Cortical tissue was embedded in a 3.5% or 4% low-melting-point agarose gel. Embedded tissue was acutely sectioned at 300 μm thickness using the Leica VT1200 vibratome before being plated on Millicell inserts (Millipore, PICM03050) into six-well tissue culture plates. Tissue slices were cultured at the air–liquid interface in medium containing 32% HBSS, 60% basal medium Eagle, 5% FBS, 1% glucose, 1% N2 and 1× penicillin–streptomycin–glutamine. The slices were maintained for 12 h in culture at 37 °C for recovery. After recovery, the slices were grown in the presence of 1 μM Octreotide (SelleckChem, P1017), 4 μM (1R,1′S,3′R/1R,1′R,3′S)-l-054,264 (Tocris, 2444), or without any compound as a control. The slices were maintained for 72 h in culture at 37 °C, and the medium was changed every 24 h.
10x fixed single-cell RNA profiling of cultured slices treated with somatostatin receptor agonists
The cultured slices treated with somatostatin receptor agonists were fixed using the Chromium Next GEM Single Cell Fixed RNA Sample Preparation Kit (10x Genomics, 1000414) according to the manufacturer’s instructions. In brief, the slices were finely minced on the prechilled glass Petri dish, transferred into 1 ml fixation buffer, incubated at 4 °C for 18 h and stored at −80 °C with 10% enhancer and 10% glycerol. After collecting all of the samples from six experimental batches, the stored samples were manually dissociated using Liberase TL (Sigma-Aldrich, 5401020001). Dissociated cells were counted using a haemocytometer and then proceeded to fixed scRNA-seq following the 10x Chromium Fixed RNA Profiling Reagent Kits (for Multiplexed Samples) user guide. In brief, fixed single-cell suspensions were mixed with Human WTA Probes BC001–BC016, hybridized overnight (18 h) at 42 °C, washed individually and pooled after the washing. Gene expression libraries were pooled and sequenced on the NovaSeq X sequencing platform, targeting 20,000 read pairs per cell.
The Cell Ranger multi pipeline was implemented for cell barcode calling, read alignment and quality assessment using the human probe set reference (Chromium_Human_Transcriptome_Probe_Set_v1.0.1_GRCh38-2020-A) according to the protocols described by 10x Genomics. The overall summary of data quality for each sample is listed in Supplementary Table 9. We next further assessed the data at the individual-cell level and retained high-quality cells with the number of detected genes (nFeature_RNA) greater than 500. Doublets were removed using the R package scDblFinder (v.1.18.0)64 with the default settings. Normalization and data scaling were performed using SCTransform v.2 (v.0.4.1)53. The transformed gene-by-cell data matrices for all cells passing quality control were integrated by reciprocal PCA projections between samples using 1–30 principal components. After integration, nearest-neighbour analysis was performed with 1–30 principal components. The resulting nearest-neighbour graph was used to perform UMAP embedding and clustering using the Louvain algorithm61. Clusters with fewer UMI counts and markers known to be mutually exclusive were deemed low quality and discarded. These filtering steps resulted in 132,856 cells in the final dataset (Supplementary Table 10). The identity of specific cell types was determined based on the expression of known marker genes, as is shown in Extended Data Fig. 8b.
Differential gene expression analysis to determine the effects of somatostatin receptor agonists
Pseudobulk differential gene expression analysis was performed using the pseudoBulkDGE function from the R package scran (v.1.32.0). UMI counts were aggregated across cell types, individual patients and treatment conditions. Pseudobulk samples with less than 10 cells were discarded. Next, we fitted the pseudobulked count data to a fixed-effect limma-voom model (~patient_ID +treatment). Once the model was fit, moderated t-tests were used to determine statistical significance through limma’s standard pipeline (Supplementary Table 11). The resulting moderated t-statistics of each gene were ranked and used as the input for gene set enrichment analysis (GSEA) using the R package clusterProfiler65. GSEA was performed against gene sets defined by the terms of biological processes in Gene Ontology (Supplementary Table 12). Only pathway sets with gene numbers between 10 and 500 were used for the analysis.
Gene regulatory network analysis
We implemented the SCENIC+ (v0.1.dev448+g2c0bafd) workflow15 to build GRNs of the developing human neocortex based on the snMultiome data. As running the workflow on all nuclei is memory intensive, we subsampled 10,000 representative nuclei by geometric sketching66 to accelerate the analyses while preserving rare cell states and the overall data structure. First, MACS2 was used for consensus peak calling in each cell type50. Each peak was extended for 250 bp in both directions from the summit. Next, weak peaks were removed, and the remaining peaks were summarized into a peak-by-nuclei matrix. Topic modelling was performed on the matrix by pycisTopic67 using the default parameters, and the optimal number of topics (48) was determined based on log-likelihood metrics. Three different methods were used in parallel to identify candidate enhancer regions: (1) regions of interest were selected by binarizing the topics using the Otsu method; (2) regions of interest were selected by taking the top 3,000 regions per topic; and (3) regions of interest were selected by calling differentially accessible peaks on the imputed matrix using a Wilcoxon rank sum test (log[FC] > 0.5 and Benjamini–Hochberg-adjusted P < 0.05). Pycistarget and discrete element method (DEM) based motif enrichment analysis were then implemented to determine whether the candidate enhancers were linked to a given TF68. Next, eRegulons, defined as TF-region-gene triplets consisting of a specific TF, all regions that are enriched for the TF-annotated motif, and all genes linked to these regions, were determined by a wrapper function provided by SCENIC+ using the default settings. We applied a standard eRegulon filtering procedure: (1) only eRegulons with more than ten target genes and positive region–gene relationships were retained; (2) only genes with top TF-to-gene importance scores were selected as the target genes for each eRegulon; and (3) eRegulons with an extended annotation was only kept if no direct annotation is available. After filtering, 582 eRegulons were retained (Supplementary Table 13). For each retained eRegulon, specificity scores were calculated using the RSS algorithm based on region- or gene-based eRegulon enrichment scores (AUC scores)69 (Supplementary Table 14). eRegulons with top specificity scores in each cell type were selected for visualization. Finally, we extended our eRegulon enrichment analysis from the 10,000 sketched nuclei to all 232,328 nuclei by computing the gene-based AUC scores for all 582 eRegulons using the R package AUCell (v.1.20.2)18 using the default settings.
Validation of the predicted eRegulons by SCENIC+
The predicted open chromatin regions (OCRs) regulated by the selected TFs in SCENIC+ were validated using ChIP–seq data described previously16. The data were downloaded from Synapse (https://www.synapse.org/Synapse:syn51942384.1/datasets). We focused on available data for core TFs of eRegulons with >10,000 ChIP–seq peaks, resulting in 24 datasets for further analysis. For each TF, the enrichment of eRegulon-targeted OCRs in the identified ChIP–seq peaks against the genomic background was computed as the odds ratio. The P values were derived from the two-sided Fisher’s exact test, with corrections for multiple comparisons. The association of OCRs with their target genes was validated using long-range H3K4me3-mediated chromatin interactions captured by PLAC-seq17, where pairs with overlaps of both interaction bins were considered. The over-representation of OCR-to-gene interactions was tested using the two-sided Fisher’s exact test.
Trajectory inference and trajectory-based differential expression analysis
Cells belonging to excitatory neuronal lineages, including RG cells, IPC-ENs and glutamatergic neurons, were selected from the whole dataset for trajectory inference using Slingshot (v.2.6.0)21. A weighted nearest-neighbour graph was recalculated on the subset using 1–50 principal components and 2–40 LSI components. Dimension reduction was performed based on the calculated nearest-neighbour graph, generating an eight-dimensional UMAP embedding. We identified 23 clusters in this UMAP space after removing one outlier cluster using mclust70. Next, we identified the global lineage structure with a cluster-based minimum spanning tree (MST). The cluster containing RG-vRG was set as the starting cluster, and those containing terminally differentiated cells were set as ending clusters (Extended Data Fig. 11a). Subsequently, we fitted nine simultaneous principal curves to describe each of the nine lineages, obtaining each cell’s weight based on its projection distance to the curve representing that lineage. Pseudotimes were inferred based on the principal curves, and shrinkage was performed for each branch for better convergence (Supplementary Table 16). Finally, the principal curves in the eight-dimensional UMAP space were projected to a two-dimensional UMAP space for visualization.
Identification of eRegulon modules
To model the activity of eRegulons along inferred trajectories, we fitted gene-based eRegulon AUC scores against pseudotimes by a generalized additive model (GAM) using tradeSeq (v.1.12.0)22. As AUC scores can be seen as proportions data on (0,1), instead of the default negative binomial GAM, we fitted a beta GAM with six knots in tradeSeq. Fitted values from the tradeSeq models were extracted using the predictSmooth function, with 100 datapoints along each trajectory. The oRG and tRG trajectory was removed because we focused on excitatory neuronal lineages for eRegulon analysis. On the basis of fitted AUC values, six eRegulon modules were identified by k-means clustering (Supplementary Table 17a).
Gene Ontology enrichment analysis for eRegulon modules
The one-sided hypergeometric test implemented in clusterProfiler (v.4.0.5)65 was used to identify over-represented Gene Ontology (biological pathway) in each eRegulon module (Supplementary Table 17b). Genes present in at least 8% of all eRegulons in a module were regarded as the core target genes of that module. Module-specific core target gene sets were used as input gene sets. The union of target genes of any eRegulon was used as the background.
Differential gene expression analysis between common and V1-specific EN-L4-IT
To identify genes that were differentially expressed between common and V1-specific EN-L4-IT, we first selected all EN-L4-IT nuclei and determined their subtype identity (common or V1-specific) based on markers and tissue of origin (Extended Data Fig. 12a,b). We then aggregated counts across samples and subtypes to generate pseudobulk samples. Differential gene expression analysis was performed by fitting the pseudobulked count data to a generalized linear mixed model (~subtype + log2[age] + [1|dataset]) using the R package glmmSeq (v.0.5.5)71. Size factors and dispersion were estimated using the R package edgeR (v.3.42.4)72. Once the model was fit, likelihood ratio tests were used to determine statistical significance using (~log2[age] + [1|dataset]) as the reduced model. Genes with Benjamini–Hochberg-adjusted P < 0.05 were determined to be significant (Supplementary Table 18).
Identification of key eRegulons that regulate neuronal lineage divergence
Based on the principal curves, five BPs were identified along neuronal differentiation. To identify genes that are differentiating around a BP of the trajectory, we performed an earlyDETest using tradeSeq. Specifically, we first separated the pseudotimes into five consecutive segments (Extended Data Fig. 11g). We then compared the expression patterns of gene-based eRegulon AUCs along pseudotime between lineages by contrasting 12 equally spaced pseudotimes within segments that enclose the BP (Supplementary Table 19). We included segments 2–3 for BP1, segments 3–4 for BP2, and segments 4–5 for BP3, BP4 and BP5.
Isolation and in vitro culture of glial progenitors from late second-trimester human cortex
Glial progenitor cells were isolated from GW20–24 human dorsal cortical tissue samples. The VZ/iSVZ and oSVZ were dissected and dissociated using the Papain Dissociation System (Worthington Biochemical). Dissociated cells were layered onto undiluted papain inhibitor solution (Worthington Biochemical) and centrifuged at 70g for 6 min to eliminate debris. The cell pellet was resuspended in 10 ml complete culture medium (DMEM/F12, 2 mM GlutaMAX, 2% B27 without vitamin A, 1% N2 and 1× penicillin–streptomycin) and incubated at 37 °C for 3 h for surface-antigen recovery. From this point on, cells were handled on ice or at 4 °C. Cells were washed once with staining buffer (Hank’s balanced salt solution (HBSS) without Ca2+ and Mg2+, 10 mM HEPES pH 7.4, 1% BSA, 1 mM EDTA, 2% B27 without vitamin A, 1% N2 and 1× penicillin–streptomycin), centrifuged at 300g for 5 min and resuspended in staining buffer to a density of 1 × 108 cells per ml. Cells were blocked by FcR blocking reagent (Miltenyi Biotech, 1:20) for 10 min, followed by antibody incubation for 30 min. Antibodies used for fluorescence-activated cell sorting (FACS) include FITC anti-EGFR (Abcam, ab11400), PE anti-F3 (BioLegend, 365204), PerCP-Cy5.5 anti-CD38 (BD Biosciences, 551400), Alexa Fluor 647 anti-PDGFRA (BD Biosciences, 562798) and PE-Cy7 anti-ITGA2 (BioLegend, 359314). All antibodies were used at 1:20 dilution. After incubation, cells were washed twice in staining buffer, resuspending in staining buffer containing Sytox Blue (Invitrogen) and sorted using the BD FACSAria II sorter. Cells were sorted into collection buffer (HBSS without Ca2+ and Mg2+, 10 mM HEPES pH 7.4, 5% BSA, 2% B27 without vitamin A, 1% N2 and 1× penicillin–streptomycin). After sorting, cells were centrifuged at 300g for 5 min, resuspended in complete culture medium and plated onto glass coverslips pre-coated with poly-d-lysine and laminin at a density of 2.5 × 104 cells per cm2. Cells were cultured in a humidified incubator with 5% CO2 and 8% O2. Half of the medium was changed with fresh medium every 3–4 days until collection at the indicated time.
Immunostaining of cultured cells and confocal imaging
On DIV0 and DIV14, glial progenitors or their progenies were fixed with 4% formaldehyde/4% sucrose in PBS and permeabilized/blocked with PBS-based blocking buffer containing 10% donkey serum, 0.2% gelatin and 0.1% Triton X-100 at room temperature for 1 h. The samples were then incubated with primary antibodies diluted in the blocking buffer at 4 °C overnight. The next day, the samples were washed in PBS three times and incubated with secondary antibodies in the blocking buffer at room temperature for 1 h. Samples were then washed twice in PBS, counterstained with DAPI and washed in PBS again. z-stack images were acquired using the Leica TCS SP8 using a 25× water-immersion objective. Acquired images were processed using Imaris v.9.7 (Oxford Instruments) and ImageJ v.1.5462. The following antibodies were used: TFAP2C (R&D systems, AF5059, 1:50), CRYAB (Abcam, ab13496, 1:200), OLIG2 (Abcam, ab109186, 1:150), EGFR (Abcam, ab231, 1:200), SPARCL1 (R&D systems, AF2728, 1:50), DLX5 (Sigma-Aldrich, HPA005670, 1:100) and NeuN (EMD Millipore, ABN90, 1:250).
scRNA-seq analysis of glial progenitor differentiation
Glial progenitors were either immediately subjected to scRNA-seq or cultured in vitro for 7 and 14 days before scRNA-seq. In the latter cases, cells were released using the Papain Dissociation System (Worthington Biochemical) without DNase for 20 min. Released cells were washed twice in HBSS without Ca2+ and Mg2+ supplemented with 0.04% BSA, centrifuged at 250g for 5 min, and resuspended in HBSS without Ca2+ and Mg2+ supplemented with 0.04% BSA. Cells were counted using a haemocytometer, diluted to ~1,000 nuclei per μl and further processed according to the 10x Genomics Chromium Single Cell 3’ Reagent Kits User Guide (v3.1 Chemistry). We targeted 10,000 cells per sample per reaction. Libraries from individual samples were pooled and sequenced on the NovaSeq 6000 sequencing system, targeting 22,500 read pairs per cell.
The raw sequencing signals in the BCL format were demultiplexed into fastq format using the mkfastq function in the Cell Ranger suite (v.7.1.0, 10x Genomics). The Cell Ranger count pipeline was implemented for cell barcode calling, read alignment and quality assessment using the human reference genome (GRCh38, GENCODE v32/Ensembl98) according to the protocols described by 10x Genomics. The pipeline assessed the overall quality to retain all intact cells from the background and filtered out non-cell associated reads. All gene expression libraries in this study showed a high fraction of reads in cells, indicating high RNA content in called cells and minimal levels of ambient RNA detected. The overall summary of data quality for each sample is listed in Supplementary Table 20. Next, we further assessed the data at the individual-cell level and retained high-quality cells with the following criteria: (1) the number of detected genes (nFeature_RNA) is greater than 1,000 and less than 10,000; and (2) less than 10% of all reads mapped to mitochondrial genes. Raw counts were log-normalized with a size factor of 10,000. The first 30 principal components were used to construct the nearest-neighbour graph, and Louvain clustering was used to identify clusters. Clusters with significantly fewer UMI counts, probably consisting of low-quality, dying cells, were also excluded for further analysis. The identity of specific cell types was determined based on the expression of known marker genes (Extended Data Fig. 15e and Supplementary Table 21). The ten identified cell types were dividing cell (dividing), RGs, ependymal cell, IPC-EN, tripotential intermediate progenitor cell (Tri-IPC), astrocytes, OPCs, intermediate progenitor cell for INs (IPC-IN) and INs.
Classification of glial-progenitor-derived cells by SingleCellNet
To determine the similarity between glial-progenitor-derived cells and our atlas data, we applied SingleCellNet (v.0.1.0), a random-forest-based cell-type classification method35. Specifically, we randomly selected 700 cells from each cell type as the training set. We found the top 60 most differentially expressed genes per cell type, and then ranked the top 150 gene pairs per cell type from those genes. The preprocessed training data were then transformed according to the selected gene pairs and were used to build a multi-class classifier of 1,000 trees. Moreover, we created 400 randomized cell expression profiles to train up an ‘unknown’ category in the classifier. After the classifier was built, we selected 165 cells from each cell type from the held-out data, along with another 165 randomized cells, and assessed the performance of the classifier on the held-out data using precision-recall curves, obtaining an average AUPRC of 0.827. To classify Tri-IPC-derived INs, we transformed the query data with top pairs selected from the optimized training data and classified it with the trained classifier. Here we chose a classification score threshold of 0.2, and cells with scores below this threshold were assigned as unmapped.
Clonal analysis of glial progenitors
For clonal analysis, samples for FACS were processed as above with the following changes: individual tRG, oRG or Tri-IPC cells were sorted using the BigFoot Spectral Cell Sorter (Thermo Fisher Scientific) using single-cell precision mode into a single well of 96-well glass-bottom plates precoated with polyethylenimine and laminin containing 100 μl complete culture medium. For tRGs and oRGs, the complete culture medium was supplemented with 10 ng ml−1 FGF2 to promote initial cell survival and proliferation. The culture medium was changed weekly for a total of 2 weeks. After 2 weeks, cells were fixed and stained in the same way as mentioned above. The following antibodies were used: EOMES (Abcam, ab23345, 1:200), OLIG2 (EMD Millipore, MABN50, 1:200), EGFR (Abcam, ab231, 1:200), SPARCL1 (R&D systems, AF2728, 1:50), SOX10 (Santa Cruz, sc-365692, 1:50) and DLX5 (Sigma-Aldrich, HPA005670, 1:100).
Glial progenitor slice transplantation assay
Glial progenitors were isolated from GW20–24 primary cortical tissue by FACS, as described above. About 200,000 cells were centrifuged at 300g for 5 min and resuspended in 0.5 ml complete culture medium containing 1 × 107 plaque-forming units of CMV-GFP adenoviruses (Vector Biolabs). Next, cells were incubated in a low-attachment plate for 1 h under the normal culture conditions. After infection, cells were washed twice with complete culture medium containing 0.3% BSA and resuspended in slice culture medium. About 25,000 cells were transplanted onto the oSVZ of freshly prepared slices through a pipette. The slices were maintained for 8 days in culture at 37 °C, and the medium was changed every other day.
After 8 days in culture, the slices were fixed with 4% formaldehyde in PBS at room temperature for 1 h, followed by permeabilization and blocking with PBS-based blocking buffer containing 10% donkey serum, 0.2% gelatin and 1% Triton X-100 at room temperature for 1 h. The samples were then incubated with primary antibodies diluted in the blocking buffer at 4 °C for 48 h. Then, 2 days later, the samples were washed in PBS plus 0.1% Triton X-100 four times and incubated with secondary antibodies in the blocking buffer at 4 °C for 24 h. After secondary antibody incubation, the samples were washed twice in PBS plus 0.1% Triton X-100, counterstained with DAPI and washed in PBS again. z-stack images were acquired on the Leica TCS SP8 system using a 25× water-immersion objective. Acquired images were processed using Imaris v.9.7 (Oxford Instruments) and ImageJ (v.1.54)62. The following antibodies were used: GFP (Aveslabs, GFP-1020, 1:1,000), EOMES (Abcam, ab23345, 1:200), NeuN (EMD Millipore, ABN90, 1:250), OLIG2 (EMD Millipore, MABN50, 1:200), EGFR (Abcam, ab32077, 1:200), DLX5 (Sigma-Aldrich, HPA005670, 1:100) and SPARCL1 (R&D systems, AF2728, 1:50).
Glial progenitor xenograft assay
FACS-sorted Tri-IPCs (60,000 cells) were centrifuged and resuspended in Leibovitz’s L-15 medium with DNase I (180 μg ml−1). Immediately before transplantation, cells were further concentrated by centrifugation (4 min, 800g) and resuspended in 2 μl Leibovitz’s L-15 with DNase I. The cell suspension was loaded into bevelled glass micropipettes (about 70–90 μm in diameter, Wiretrol 5 μl, Drummond Scientific) prefilled with mineral oil and mounted onto a microinjector. Recipient mice (NSG, JAX 005557, postnatal day 5) were anaesthetized by hypothermia (about 4 min) and positioned in a clay head mould to stabilize the skull73. Micropipettes were positioned vertically in a stereotactic injection apparatus. Injections were performed in both the left and right hemispheres perpendicular to the skin surface. Eye coordinates were x: 1.5, y: 3.6. A total of 50 nl of cell suspension was released at z: 0.2, 0.4, 0.8 and 1 from the surface of the skin. The mice were returned to their litters after injection.
Immunostaining of xenografted human cells
Twelve weeks after injection, the recipient mice were perfused with 4% PFA and post-fixed in 4% PFA at 4 °C overnight. The samples were cryoprotected in 15% and 30% sucrose in PBS and frozen in OCT. The samples were sectioned at a thickness of 16 µm, air-dried and rehydrated in PBS. Immunostaining was done in the same way as described above for human brain sections. Confocal images were acquired with a Leica TCS SP8 using a 20× oil-immersion objective. Acquired images were processed using ImageJ (v.1.54)62. The following antibodies were used: human nuclear antigen (Abcam, ab191181, 1:200), GABA (Sigma-Aldrich, A2052, 1:250), GFAP (Invitrogen, 13-0300, 1:300) and SOX10 (R&D Systems, AF2864, 1:50).
Classification of Tri-IPC-derived INs
Human ganglionic eminence scRNA-seq data from a previous study33 were downloaded from the GEO (GSE135827) and used as the reference. We integrated all samples using the RPCA methods, subset the data to focus on cells from the ganglionic eminence, reclustered the cells and annotated IN subtypes based on marker genes reported in the literature34 (Extended Data Fig. 17a,b).
To determine the identity of Tri-IPC-derived INs based on the reference dataset, we applied SingleCellNet in a similar way as mentioned above with the following parameter modifications. We randomly selected 400 cells from each cell type as the training set. We found the top 200 most differentially expressed genes per cell type, and then ranked the top 200 gene pairs per cell type from those genes. The preprocessed training data were then transformed according to the selected gene pairs and were used to build a multi-class classifier of 1,000 trees. Moreover, we created 400 randomized cell expression profiles to train up an ‘unknown’ category in the classifier. After the classifier was built, we selected 100 cells from each cell type from the held-out data, along with another 100 randomized cells, and assessed the performance of the classifier on the held-out data using precision-recall curves, obtaining an average AUPRC of 0.901. To classify Tri-IPC-derived INs, we transformed the query data with top pairs selected from the optimized training data and classified it with the trained classifier. Here we chose a classification score threshold of 0.35, and cells with scores below this threshold were assigned as unmapped.
As an alternative classification method to determine the identity of Tri-IPC-derived INs, we performed mutual nearest-neighbour-based label transfer using the MapQuery() function in Seurat v.4. The first 30 principal components were used to identify transfer anchors. Cell-type labels from ref. 33 were transferred to Tri-IPC-derived INs when confidence was high (prediction score > 0.5). Cells with prediction scores equal to or lower than 0.5 were labelled as unmapped.
Classification of Tri-IPC-derived astrocytes
Mouse scRNA-seq data from ref. 36 were downloaded from the Single Cell Portal (SCP1290) and used as the reference. We subset the data and focused on astrocytes and cycling glial cells (defined by the original authors). These cells were reclustered and annotated as Olig2 or S100a11 lineages based on marker genes reported in the literature74 (Extended Data Fig. 17e,f). We used Tri-IPC-derived astrocytes as the query data and applied SingleCellNet in the same way as for Tri-IPC-derived INs. We also applied Seurat label transfer in the same way, except that 20 principal components were used to identify transfer anchors.
We also used astrocytes at the infancy stage from our snMultiome data, when we were able to distinguish the two astrocyte lineages, as the reference. We selected the astrocytes at infancy from the whole dataset and redid nearest-neighbour analysis with 1–50 principal components (already computed after SCTransform and RPCA integration). These cells were reclustered on the basis of the resulting nearest-neighbour graph and annotated on the basis of marker genes reported in the literature74 (Extended Data Fig. 17i,j). We used Tri-IPC-derived astrocytes as the query data, which were reprocessed in the same way as for snMultiome data, including SCTransform v.2 modelling and cell cycle regression. SingleCellNet was applied in the same way as above. For Seurat label transfer, the first 50 principal components were used to identify transfer anchors.
Classification of human GBM cells
We obtained single-cell and single-nucleus RNA-seq data of human GBM cells from the extended GBmap75, downloaded from cellxgene (https://datasets.cellxgene.cziscience.com/ead761be-309f-4b79-8208-41da14ca305f.h5ad). Using the snMultiome atlas data as a reference, we applied SingleCellNet to identify the corresponding cell types of malignant cells in the GBmap. SingleCellNet was executed using the same parameters that were previously applied for the classification of glial progenitor-derived cells. Our analysis yielded an average AUPRC of 0.832. For classification, we set a score threshold of 0.15; cells with scores below this threshold were designated as unmapped.
Building single-cell risk map for cognitive traits and brain disorders by SCAVENGE
We implemented SCAVENGE (v.1.0.2)40 to integrate the single-nucleus ATAC–seq part of the snMultiome data with GWAS data of four cognitive traits (fluid intelligence, processing speed, executive function and working memory) and five neuropsychiatric disorders (ASD, MDD, BPD, ADHD and SCZ). Analysis of Alzheimer’s disease was included as a positive control. For each trait or condition, we performed multi-SNP-based conditional and joint association analysis on all GWAS SNPs with the default settings. A stepwise model selection procedure was implemented to select independently associated SNPs and compute the fine-mapped posterior probability (PP). The PP was imported for our subsequent gchromVAR analysis76, where we built a cell-by-peak count matrix using peaks called from integrated single-nucleus ATAC–seq data. A gchromVAR score indicating potential GWAS signal enrichment over a set of background peaks was calculated for each cell after correcting GC bias. To minimize the batch effects, we used the batch-aligned LSI matrix for the nearest-neighbour graph construction and subsequent network propagation. A trait relevant score (TRS) representing the potential GWAS risk association was assigned to each cell to construct the single-cell risk map for cognitive traits or neurological disorders. To determine the significant trait–cell association, we considered cells receiving the top 0.1% TRS score traits relevant and permuted the network propagation 1,000 times for statistical significance. Cells with P < 0.05 were defined as trait associated. To determine the trait relevance per cell type, we calculated the odds ratio of cells associated with each trait in each cell type over the background and determined statistical significance using a two-sided hypergeometric test followed by Benjamini–Hochberg correction. Cell types with FDR-adjusted P < 0.05 and odds ratio > 1.4 were deemed to be significantly enriched for trait-associated variants. A similar analysis was done for regions and age groups. Finally, the TRS scores were standardized by z transformation for comparison and visualization (Supplementary Tables 23 and 24). The GWAS data used in this study can be downloaded from the following links: fluid intelligence (phenocode 20016), processing speed (phenocode 20023), executive function (phenocode 399) and working memory (phenocode 4282): https://pan.ukbb.broadinstitute.org/downloads/; ASD: https://figshare.com/articles/dataset/asd2019/14671989; MDD: https://datashare.ed.ac.uk/handle/10283/3203; BPD: https://figshare.com/articles/dataset/bip2021_noUKBB/22564402; ADHD: https://figshare.com/articles/dataset/adhd2022/22564390; SCZ: https://figshare.com/articles/dataset/cdg2018-bip-scz/14672019; ALZ: https://vu.data.surfsara.nl/index.php/s/jVlyt1m9Bb2mAki/download?path=%2F&files=PGCALZ2sumstatsExcluding23andMe.txt.gz.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
All raw and aligned snMultiome sequencing data were deposited to the NeMO archive (https://assets.nemoarchive.org/dat-oiif74w). MERFISH data were deposited to the Brain Image Library (https://doi.org/10.35077/g.1156). Processed data are available at an interactive portal (https://cell.ucsf.edu/snMultiome), at CELLxGENE (https://cellxgene.cziscience.com/collections/ad2149fc-19c5-41de-8cfe-44710fbada73) and at Dryad77 (https://doi.org/10.5061/dryad.2280gb612). For inquiries regarding the acquisition of these data, please contact the corresponding authors. JASPAR2020 motif data are available online (https://jaspar2020.genereg.net). PsychENCODE ChIP–seq data from human brain can be downloaded at Synapse (https://www.synapse.org/Synapse:syn51942384.1/datasets). PLAC-seq data from the developing human cortex are available online (https://assets.nemoarchive.org/dat-uioqy8b). Human ganglionic eminence scRNA-seq data are available at the GEO (GSE135827). Mouse developing cortex scRNA-seq data are available from the Single Cell Portal (SCP1290). Extended GBmap data are available from CELLxGENE (https://datasets.cellxgene.cziscience.com/ead761be-309f-4b79-8208-41da14ca305f.h5ad). The GWAS data used in this study can be downloaded online: fluid intelligence (phenocode 20016), processing speed (phenocode 20023), executive function (phenocode 399) and working memory (phenocode 4282): https://pan.ukbb.broadinstitute.org/downloads/; ASD78: https://figshare.com/articles/dataset/asd2019/14671989; MDD: https://datashare.ed.ac.uk/handle/10283/3203; BPD79: https://figshare.com/articles/dataset/bip2021_noUKBB/22564402; ADHD80: https://figshare.com/articles/dataset/adhd2022/22564390; SCZ81: https://figshare.com/articles/dataset/cdg2018-bip-scz/14672019; ALZ: https://vu.data.surfsara.nl/index.php/s/jVlyt1m9Bb2mAki/download?path=%2F&files=PGCALZ2sumstatsExcluding23andMe.txt.gz.
Code availability
The code used for data analysis in this Article is available at GitHub (https://github.com/complexdisease/Human_Cortex_Dev_Multiome).
References
Molnár, Z. et al. New insights into the development of the human cerebral cortex. J. Anat. 235, 432–451 (2019).
Long, H. K., Prescott, S. L. & Wysocka, J. Ever-changing landscapes: transcriptional enhancers in development and evolution. Cell 167, 1170–1187 (2016).
Zhu, K. et al. Multi-omic profiling of the developing human cerebral cortex at the single-cell level. Sci. Adv. 9, eadg3754 (2023).
Mannens, C. C. A. et al. Chromatin accessibility during human first-trimester neurodevelopment. Nature https://doi.org/10.1038/s41586-024-07234-1 (2024).
Trevino, A. E. et al. Chromatin and gene-regulatory dynamics of the developing human cerebral cortex at single-cell resolution. Cell 184, 5053–5069 (2021).
Hao, Y. et al. Integrated analysis of multimodal single-cell data. Cell 184, 3573–3587 (2021).
Velmeshev, D. et al. Single-cell analysis of prenatal and postnatal human cortical development. Science 382, eadf0834 (2023).
Jorstad, N. L. et al. Transcriptomic cytoarchitecture reveals principles of human neocortex organization. Science 382, eadf6812 (2023).
Chen, K. H., Boettiger, A. N., Moffitt, J. R., Wang, S. & Zhuang, X. Spatially resolved, highly multiplexed RNA profiling in single cells. Science 348, aaa6090 (2015).
Stenman, J., Toresson, H. & Campbell, K. Identification of two distinct progenitor populations in the lateral ganglionic eminence: implications for striatal and olfactory bulb neurogenesis. J. Neurosci. 23, 167–174 (2003).
Akay, L. A., Effenberger, A. H. & Tsai, L. H. Cell of all trades: oligodendrocyte precursor cells in synaptic, vascular, and immune function. Genes Dev. 35, 180–198 (2021).
Kriegstein, A. & Alvarez-Buylla, A. The glial nature of embryonic and adult neural stem cells. Annu. Rev. Neurosci. 32, 149–184 (2009).
Fischer, D. S., Schaar, A. C. & Theis, F. J. Modeling intercellular communication in tissues using spatial graphs of cells. Nat. Biotechnol. 41, 332–336 (2022).
Jin, S. et al. Inference and analysis of cell-cell communication using CellChat. Nat. Commun. 12, 1088 (2021).
Bravo González-Blas, C. et al. SCENIC+: single-cell multiomic inference of enhancers and gene regulatory networks. Nat. Methods 20, 1355–1367 (2023).
Loupe, J. M. et al. Multiomic profiling of transcription factor binding and function in human brain. Nat. Neurosci. 27, 1387–1399 (2024).
Song, M. et al. Cell-type-specific 3D epigenomes in the developing human cortex. Nature 587, 644–649 (2020).
Aibar, S. et al. SCENIC: single-cell regulatory network inference and clustering. Nat. Methods 14, 1083–1086 (2017).
Jolma, A. et al. DNA-dependent formation of transcription factor pairs alters their binding specificity. Nature 527, 384–388 (2015).
Wu, W. S. & Lai, F. J. Functional redundancy of transcription factors explains why most binding targets of a transcription factor are not affected when the transcription factor is knocked out. BMC Syst. Biol. 9, S2 (2015).
Street, K. et al. Slingshot: cell lineage and pseudotime inference for single-cell transcriptomics. BMC Genom. 19, 477 (2018).
Van den Berge, K. et al. Trajectory-based differential expression analysis for single-cell sequencing data. Nat. Commun. 11, 1201 (2020).
Cadwell, C. R., Bhaduri, A., Mostajo-Radji, M. A., Keefe, M. G. & Nowakowski, T. J. Development and arealization of the cerebral cortex. Neuron 103, 980–1004 (2019).
Huang, W. et al. Origins and proliferative states of human oligodendrocyte precursor cells. Cell 182, 594–608 (2020).
Fu, Y. et al. Heterogeneity of glial progenitor cells during the neurogenesis-to-gliogenesis switch in the developing human cerebral cortex. Cell Rep. 34, 108788 (2021).
Yang, L., Li, Z., Liu, G., Li, X. & Yang, Z. Developmental origins of human cortical oligodendrocytes and astrocytes. Neurosci. Bull. 38, 47–68 (2022).
Ramos, S. I. et al. An atlas of late prenatal human neurodevelopment resolved by single-nucleus transcriptomics. Nat. Commun. 13, 7671 (2022).
Liu, D. D. et al. Purification and characterization of human neural stem and progenitor cells. Cell 186, 1179–1194 (2023).
Weng, Q. et al. Single-cell transcriptomics uncovers glial progenitor diversity and cell fate determinants during development and gliomagenesis. Cell Stem Cell 24, 707–723 (2019).
Zhang, Y. et al. Cortical neural stem cell lineage progression is regulated by extrinsic signaling molecule sonic hedgehog. Cell Rep. 30, 4490–4504 (2020).
Li, X. et al. Decoding cortical glial cell development. Neurosci Bull. 37, 440–460 (2021).
Andrews, M. G. et al. LIF signaling regulates outer radial glial to interneuron fate during human cortical development. Cell Stem Cell 30, 1382–1391 (2023).
Shi, Y. et al. Mouse and human share conserved transcriptional programs for interneuron development. Science 374, eabj6641 (2021).
Schmitz, M. T. et al. The development and evolution of inhibitory neurons in primate cerebrum. Nature 603, 871–877 (2022).
Tan, Y. & Cahan, P. SingleCellNet: a computational tool to classify single cell RNA-seq data across platforms and across species. Cell Syst. 9, 207–213 (2019).
Di Bella, D. J. et al. Molecular logic of cellular diversification in the mouse cerebral cortex. Nature 595, 554–559 (2021).
Neftel, C. et al. An integrative model of cellular states, plasticity, and genetics for glioblastoma. Cell 178, 835–849 (2019).
Couturier, C. P. et al. Single-cell RNA-seq reveals that glioblastoma recapitulates a normal neurodevelopmental hierarchy. Nat. Commun. 11, 1–19 (2020).
Albiach, A. M. et al. Glioblastoma is spatially organized by neurodevelopmental programs and a glial-like wound healing response. Preprint at bioRxiv https://doi.org/10.1101/2023.09.01.555882 (2023).
Yu, F. et al. Variant to function mapping at single-cell resolution through network propagation. Nat. Biotechnol. 40, 1644–1653 (2022).
Li, Y. E. et al. A comparative atlas of single-cell chromatin accessibility in the human brain. Science 382, eadf7044 (2023).
Nott, A. et al. Brain cell type–specific enhancer–promoter interactome maps and disease-risk association. Science 366, 1134–1139 (2019).
Corces, M. R. et al. Single-cell epigenomic analyses implicate candidate causal variants at inherited risk loci for Alzheimer’s and Parkinson’s diseases. Nat. Genet. 52, 1158–1168 (2020).
Yang, A. C. et al. A human brain vascular atlas reveals diverse mediators of Alzheimer’s risk. Nature 603, 885–892 (2022).
Arranz, A. M. & De Strooper, B. The role of astroglia in Alzheimer’s disease: pathophysiology and clinical implications. Lancet Neurol. 18, 406–414 (2019).
Abrahams, B. S. et al. SFARI Gene 2.0: a community-driven knowledgebase for the autism spectrum disorders (ASDs). Mol. Autism 4, 36 (2013).
Delgado, R. N. et al. Individual human cortical progenitors can produce excitatory and inhibitory neurons. Nature 601, 397–403 (2021).
Wang, L. & Kriegstein, A. Nuclei isolation from tissue for 10x Multiome by iodixanol. Protocols.io https://doi.org/10.17504/PROTOCOLS.IO.EQ2LYJ3NPLX9/V1 (2023).
Wolock, S. L., Lopez, R. & Klein, A. M. Scrublet: computational identification of cell doublets in single-cell transcriptomic data. Cell Syst. 8, 281–291 (2019).
Zhang, Y. et al. Model-based Analysis of ChIP-Seq (MACS). Genome Biol. 9, R137 (2008).
Amemiya, H. M., Kundaje, A. & Boyle, A. P. The ENCODE Blacklist: identification of problematic regions of the genome. Sci. Rep. 9, 9354 (2019).
Stuart, T., Srivastava, A., Madad, S., Lareau, C. A. & Satija, R. Single-cell chromatin state analysis with Signac. Nat. Methods 18, 1333–1341 (2021).
Choudhary, S. & Satija, R. Comparison and evaluation of statistical error models for scRNA-seq. Genome Biol. 23, 27 (2022).
Butler, A., Hoffman, P., Smibert, P., Papalexi, E. & Satija, R. Integrating single-cell transcriptomic data across different conditions, technologies, and species. Nat. Biotechnol. 36, 411–420 (2018).
Waltman, L. & Van Eck, N. J. A smart local moving algorithm for large-scale modularity-based community detection. Eur. Phys. J. B 86, 471 (2013).
Phipson, B. et al. propeller: testing for differences in cell type proportions in single cell data. Bioinformatics 38, 4720–4726 (2022).
Ritchie, M. E. et al. limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 43, e47 (2015).
Schep, A. N., Wu, B., Buenrostro, J. D. & Greenleaf, W. J. chromVAR: inferring transcription-factor-associated accessibility from single-cell epigenomic data. Nat. Methods 14, 975–978 (2017).
Fornes, O. et al. JASPAR 2020: update of the open-access database of transcription factor binding profiles. Nucleic Acids Res. 48, D87–D92 (2020).
Hao, Y. et al. Dictionary learning for integrative, multimodal and scalable single-cell analysis. Nat. Biotechnol. https://doi.org/10.1038/s41587-023-01767-y (2023).
Van Nguyen, L. et al. Fast unfolding of communities in large networks. J. Stat. Mech. 2008, P10008 (2008).
Schindelin, J. et al. Fiji: an open-source platform for biological-image analysis. Nat. Methods 9, 676–682 (2012).
Palla, G. et al. Squidpy: a scalable framework for spatial omics analysis. Nat. Methods 19, 171–178 (2022).
Germain, P. L., Robinson, M. D., Lun, A., Garcia Meixide, C. & Macnair, W. Doublet identification in single-cell sequencing data using scDblFinder. F1000Res. 10, 979 (2022).
Yu, G., Wang, L. G., Han, Y. & He, Q. Y. ClusterProfiler: an R package for comparing biological themes among gene clusters. OMICS 16, 284–287 (2012).
Hie, B., Cho, H., DeMeo, B., Bryson, B. & Berger, B. Geometric sketching compactly summarizes the single-cell transcriptomic landscape. Cell Syst. 8, 483–493 (2019).
Bravo González-Blas, C. et al. cisTopic: cis-regulatory topic modeling on single-cell ATAC-seq data. Nat. Methods 16, 397–400 (2019).
Janky, R. et al. iRegulon: from a gene list to a gene regulatory network using large motif and track collections. PLoS Comput. Biol. 10, e1003731 (2014).
Van de Sande, B. et al. A scalable SCENIC workflow for single-cell gene regulatory network analysis. Nat. Protoc. 15, 2247–2276 (2020).
Scrucca, L., Fraley, C., Murphy, T. B. & Raftery, A. E. Model-Based Clustering, Classification, and Density Estimation Using Mclust in R (CRC Press, 2023).
Rivellese, F. et al. Rituximab versus tocilizumab in rheumatoid arthritis: synovial biopsy-based biomarker analysis of the phase 4 R4RA randomized trial. Nat. Med. 28, 1256–1268 (2022).
Robinson, M. D., McCarthy, D. J. & Smyth, G. K. edgeR: a Bioconductor package for differential expression analysis of digital gene expression data. Bioinformatics 26, 139–140 (2009).
Merkle, F. T., Mirzadeh, Z. & Alvarez-Buylla, A. Mosaic organization of neural stem cells in the adult brain. Science 317, 381–384 (2007).
Zhou, J. et al. Dual lineage origins of neocortical astrocytes. Preprint at bioRxiv https://doi.org/10.1101/2023.09.12.557313 (2023).
Ruiz-Moreno, C. et al. Harmonized single-cell landscape, intercellular crosstalk and tumor architecture of glioblastoma. Preprint at bioRxiv https://doi.org/10.1101/2022.08.27.505439 (2022).
Ulirsch, J. C. et al. Interrogation of human hematopoiesis at single-cell and single-variant resolution. Nat. Genet. 51, 683–693 (2019).
Wang, L. et al. Data for ‘Molecular and cellular dynamics of the developing human neocortex’. Dryad https://doi.org/10.5061/dryad.2280gb612 (2024).
Sullivan, P. GWAS summary statistics from the Psychiatric Genomics Consortium (PGC). Figshare https://doi.org/10.6084/m9.figshare.14671989.v1 (2021).
Sullivan, P. GWAS summary statistics from the Psychiatric Genomics Consortium (PGC). Figshare (2023); https://doi.org/10.6084/m9.figshare.22564402.v1.
Sullivan, P. GWAS summary statistics on ADHD2022. Figshare https://doi.org/10.6084/m9.figshare.22564390.v1 (2023).
Sullivan, P. GWAS summary statistics from the Psychiatric Genomics Consortium (PGC). Figshare https://doi.org/10.6084/m9.figshare.14672019.v1 (2021).
Acknowledgements
We thank the staff at the NIH NeuroBioBank and the University of Maryland School of Medicine Brain and Tissue Bank for providing post mortem brain tissue samples; the staff at the Human Developmental Biology Resource for providing first-trimester brain tissue samples; and the members of the A.R.K. laboratory and T. Nowakowski laboratory for discussions. This work was supported by grants from the Simons Foundation 697827 and 1010017 to J.L. and A.R.K., National Institute of General Medical Sciences (NIGMS) grant R35GM142983 to J.L., National Institute of Mental Health (NIMH) grant U01MH114825 to A.R.K. and E.J.H., National Institute of Neurological Disorders and Stroke (NINDS) grant R35NS097305 to A.R.K., NINDS grant P01NS083513 to A.A.-B., E.J.H. and A.R.K., NIMH grant K99MH131832 to L.W. and NINDS grant R01NS123912 to X.D. J.A.M. was supported by funding from the Government of Catalonia (FI-SDUR 20) and from The Company of Biologists—Development (Travelling Fellowship). We acknowledge the Parnassus Flow Cytometry CoLab (RRID:SCR_018206), supported in part by Grant NIH P30 DK063720 and by the NIH S10 Instrumentation Grant S10 1S10OD021822-01. Sequencing was in part performed at the UCSF CAT, with support from UCSF PBBR, RRP IMIA, and NIH 1S10OD028511-01 grants.
Author information
Authors and Affiliations
Contributions
Conceptualization: L.W., C.W., J.L. and A.R.K. Data curation: L.W. and C.W. Formal analysis: L.W., C.W. and J.A.M. Funding acquisition: L.W., E.J.H., A.A.-B., X.D., J.L. and A.R.K. Investigation: L.W., S.C., G.Z., A.C.-S., S.Z., T.M., S.W., M.S., L.G.O. and Q.B. Methodology: L.W., A.C.-S., S.Z. and X.G. Resources: S.W., M.F.P., E.J.H. and A.R.K. Software: L.W., C.W., J.A.M. and J.J.A. Supervision: A.A.-B., X.D., J.L. and A.R.K. Visualization: L.W., C.W. and J.A.M. Writing—original draft: L.W., C.W. and J.A.M. All of the authors contributed to reviewing and editing of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
A.R.K. is a co-founder, consultant and director of Neurona Therapeutics. J.L. is a co-founder and a member of the scientific advisory board of SensOmics, Inc. The other authors declare no competing interests.
Peer review
Peer review information
Nature thanks the anonymous reviewers for their contribution to the peer review of this work.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended Data Fig. 1 Filtering of the snMultiome data.
a, UMAP plots showing the distribution of cell subclasses in the snMultiome data prior to data filtering. b, UMAP plots showing the distribution of age groups in the snMultiome data prior to data filtering. c, UMAP plots showing the distribution of cells removed during data filtering. d, UMAP plots showing the expression levels of genes identified in the striatum (ISL1 and SIX3), diencephalon (OTX2 and GBX2), neuronal processes (NRGN), and oligodendrocyte processes (MBP). e, Classes, subclasses, and types identified from the snMultiome data.
Extended Data Fig. 2 Quality control of the snMultiome data.
a, Violin plots, box plots, barplots, and UMAP plots of several quality control metrics for evaluating the quality of individual samples in the snMultiome data, including numbers of unique molecular identifiers (# UMIs), numbers of identified genes (# genes), number of fragments in ATAC peaks, transcription start site (TSS) enrichment scores, and proportion of individual cell types in each sample. The legend for cell types can be found in panel b. b, UMAP plots of cells from individual snMultiome datasets separated by age groups. c, UMAP plots generated based on RNA or ATAC data only. The legend can be found in panel a.
Extended Data Fig. 3 Expression patterns of marker genes in the snMultiome data.
UMAP plots of all cells showing the expression levels of cell-type-specific marker genes. The coloured circles and numbers pinpoint specific cell types where the gene is highly expressed. The legend for these numbers can be found in Fig. 1b.
Extended Data Fig. 4 Quality control and annotation of MERFISH data.
a, Violin plots, box plots, barplots, and UMAP plots of several metadata of MERFISH samples, including numbers of detected transcripts (# transcript), numbers of identified genes (# genes), age groups, regions, cell types, and niches. b, PCA plots based on cell-type proportions for individual snMultiome and MERFISH samples in three different age groups. c, UMAP plots of all cells in the MERFISH dataset showing the expression levels of cell-type-specific marker genes.
Extended Data Fig. 5 Spatial distribution of cell types in individual MERFISH samples.
a–f, Spatial distribution of cell types in individual MERFISH samples.
Extended Data Fig. 6 Difference in distribution of MGE- and CGE-derived interneurons in the second-trimester neocortex.
a, Immunostaining of MGE-derived (LGX6+) and CGE-derived (NR2F2+) interneurons in the cortex of a gestational week (GW) 24 sample. MZ, marginal zone; CP, cortical plate; SP/IZ, subplate/intermediate zone; oSVZ, outer subventricular zone; iSVZ, inner subventricular zone; VZ, ventricular zone. b, Odds ratios of the number of CGE-derived interneurons in the MZ versus ventricular/subventricular zones relative to the number of MGE-derived interneurons. Data are presented as mean values with 95% confidence intervals. P values were obtained from two-sided Fisher’s exact test; ***P < 0.001, ****P < 0.0001.
Extended Data Fig. 7 Intercellular communication between cell types in developing human cortex.
a, Heatmaps showing neighbourhood enrichment z scores of each MERFISH sample. The row and column annotations are colour coded by cell types, the legend of which can be found in Fig. 2a. When a particular cell type is not present in the dataset, the neighbourhood enrichment z scores were arbitrarily set to −50. b, Circular maps showing significant intercellular communication determined by NCEM in each MERFISH sample. c, Heatmaps showing the relative strength of outgoing (left) and incoming (right) signalling pathways in individual cell types. The bar graphs on the top and right side of the heatmaps are the sum of communication probability (interaction strength) for each cell type and signalling pathway, respectively.
Extended Data Fig. 8 Effects of somatostatin on the transcriptome of excitatory neurons in the second-trimester human cortex.
a, Violin plots, box plots, barplots, and UMAP plots of several metadata of scRNA-seq datasets from organotypic human brain slice cultures treated with and without somatostatin receptor agonists, including numbers of unique molecular identifiers (# UMIs), numbers of identified genes (# genes), ages, treatments, and cell types. b, UMAP plots of cells in the scRNA-seq dataset showing the expression levels of cell-type-specific marker genes and SSTR2. c, Scatter plots illustrating the Pearson correlation of log fold changes in individual genes between Ostreotide and L-054,264 treatments. d, Gene set enrichment analysis (GSEA) highlighting the effects of L-054,264 and Ostreotide on different types of excitatory neurons. Significant terms, defined by Benjamini–Hochberg adjusted P values < 0.05, were outlined by a red circle. Abs(NES), absolute values of normalized enrichment scores.
Extended Data Fig. 9 SCENIC+ identifies cell-type-specific eRegulons.
a, Enrichment of eRegulon-predicted TF binding sites in ChIP-seq peaks from the human dorsolateral prefrontal cortex. P values were obtained from the two-sided Fisher’s exact test and adjusted using the Benjamini and Hochberg method. b, Overlap between eRegulon-predicted enhancer-promoter interactions and PLAC-seq loops from the developing human cortex. The P value was obtained from the two-sided Fisher’s exact test. c, Heatmaps showing the minimum-maximum normalized TF expression levels, region-based AUC scores, and gene-based AUC scores of eRegulons across cell types. d, Heatmap-dotplots showing the minimum-maximum normalized TF expression levels, region-based AUC scores, and gene-based AUC scores of selective eRegulons across age groups in all cells, Glutamatergic neurons, and GABAergic neurons.
Extended Data Fig. 10 Cell-type-specific gene regulatory networks in the developing cortex.
a, A heatmap showing Jaccard similarity matrix of target regions of cell-type-specific eRegulons listed in Fig. 3a. b, Gene regulatory networks of selective eRegulons in RG-vRG, EN-L4-IT, IN-MGE-PV, astrocyte-protoplasmics and OPCs. TF nodes and their links to enhancers are individually coloured. The size and the transparency of the TF nodes represent their gene expression levels in each cell type. GEX, gene expression; ACC, accessibility; R2G, region-to-gene. c–f, Coverage plots showing aggregated ATAC profiles across cell types on four genomic loci—SOX6, PDGFRA, HOPX, and GAD2. Identified candidate cis-regulatory elements (cCREs) are coloured by their corresponding eRegulons. Region-to-gene links are shown as arcs and colour scaled based on region–gene importance scores obtained from SCENIC+ analysis.
Extended Data Fig. 11 Differentiation trajectories of excitatory neuron lineages.
a–e, UMAP plots of cells belonging to excitatory neuron lineages with clusters connected by a minimum spanning tree showing. The green node indicates the root node, and the red nodes indicate the ending nodes. Cells are colour coded by clusters (a), types (b), age groups (c), regions (d), or pseudotime (e). f, UMAP plots of each of the nine excitatory neuron lineages coloured by pseudotime. g, UMAP plots of excitatory neuron lineages coloured by the five pseudotime segments used for eRegulon activity analysis at bifurcation points. h, UMAP plots highlighting representative eRegulons involved in trajectory determination at bifurcation points.
Extended Data Fig. 12 Markers of V1-specific EN-L4-IT subtype.
a, UMAP plots of all EN-L4-IT colour coded by regions (left) and subtypes (right). b, UMAP plots showing the expression levels of representative differentially expressed genes between V1-specific and common EN-L4-IT neurons. c, In situ hybridization (ISH) of V1-biased (CUX1 and KCNIP1), and common-biased genes in EN-L4-IT neurons in adult human V1 and V2 areas. d, UMAP plots of EN-L4-IT subtype marker genes found in adult human V1.
Extended Data Fig. 13 Markers of human glial cells and their isolation strategies.
a, UMAP plots of cells belonging to glial lineages colour coded by age groups (left), regions (middle), and types (right). b, UMAP plots of cells belonging to glial lineages showing the expression levels of typical marker genes of individual cell types. c, UMAP plots of GW20 to GW23 cells belonging to glial lineages colour coded by age groups (left), regions (middle), and types (right). d, UMAP plots of GW20 to GW23 cells belonging to glial lineages showing the expression levels of typical marker genes of individual cell types. e, UMAP plots of GW20 to GW23 cells belonging to glial lineages showing the expression levels of surface markers used for glial progenitor isolation. f, Schematic of the sorting strategy for glial progenitors. VZ & iSVZ, ventricular zone and inner subventricular zone; oSVZ, outer subventricular zone.
Extended Data Fig. 14 Immunostaining characterization of human glial progenitor differentiation.
a–d, Immunostaining of isolated glial progenitors on days in vitro 1 (DIV1). e, Quantification of six cell types after sorting on DIV1 (n = 5, 5, 5 cultures), including RG or IPC-EN (TFAP2C+), IPC-glia (OLIG2+EGFR+), OPC or oligodendrocyte (OLIG2+EGFR−), astrocyte (SPARCL1+), EN (NeuN+), and IPC-IN or IN (DLX5+). f–i, Immunostaining of progenies of glial progenitors on days in vitro 14 (DIV14). j, Quantification of six cell types after sorting on DIV14 (n = 5, 5, 5 cultures), including RG or IPC-EN (TFAP2C+), IPC-glia (OLIG2+EGFR+), OPC or oligodendrocyte (OLIG2+EGFR−), astrocyte (SPARCL1+), EN (NeuN+), and IPC-IN or IN (DLX5+).
Extended Data Fig. 15 scRNA-seq characterization of human glial progenitor differentiation.
a–d, UMAP plots of isolated glial progenitors and their progenies during in vitro differentiation based on single-cell RNA sequencing data colour coded by datasets (a), stages (b), seeding cell types (c), and types (d). e, UMAP plots of isolated glial progenitors and their progenies showing the expression levels of typical marker genes of individual cell types. f, A Sankey plot showing the mapping of glial progenitors and their progenies to the snMultiome atlas by SingleCellNet. g, UMAP plots of isolated glial progenitors and their progenies separated by seeding cell types and stages.
Extended Data Fig. 16 Lineage potential of human glial progenitors.
a, Schematic of the slice transplantation assay for glial progenitors. Created in BioRender. Wang, L. (2024) BioRender.com/t85o210. b–d, Immunostaining of progenies after progenitor transplantation to acute cortical slices on days in vitro 8. e, Quantification of progeny types after progenitor transplantation to acute cortical slices (n = 5, 5, 5, 5 cultures), including IPC-EN (EOMES+), EN (NeuN+), Tri-IPC (OLIG2+EGFR+), astrocyte (SPARCL1+), OPC or oligodendrocyte (OLIG2+EGFR−), and IPC-IN or IN (DLX5+). f, Schematic of the in vivo transplantation assay for glial progenitors. Created in BioRender. Wang, L. (2024) BioRender.com/f96w125. g, Immunostaining of progenies after progenitor in vivo transplantation into mouse cortex (n = 2 injections). White arrows indicate HNA+GABA+ inhibitory neurons. HNA, human nuclear antigen; L2-3, layer 2-3; L6, layer 6; WM, white matter; V-SVZ, ventricular-subventricular zone; OB, olfactory bulb. h, Immunostaining of progenies after progenitor in vivo transplantation into mouse cortex (n = 2 injections). White arrows indicate HNA+SOX10+ OPCs or oligodendrocytes. Yellow arrows indicate HNA+GFAP+ astrocytes. HNA, human nuclear antigen; L2-3, layer 2-3; L6, layer 6; WM, white matter; V-SVZ, ventricular-subventricular zone; OB, olfactory bulb.
Extended Data Fig. 17 Mapping Tri-IPC progenies to reference data.
a, UMAP plot of a reference human ganglionic eminence dataset33. Cells are colour coded by types. b, UMAP plots of human ganglionic eminence cells showing the expression levels of typical marker genes of individual cell types. c, UMAP plots of Tri-IPC-derived INs projected to the human ganglionic eminence dataset. Cells are colour coded by types and the legend can be found in panel d. d, Identities of Tri-IPC-derived INs mapped by Seurat label transfer. e, UMAP plot of mouse astrocytes from a reference developing mouse cortex dataset36. Cells are colour coded by lineages and the legend can be found in panel h. f, UMAP plots of the reference mouse astrocytes showing the expression levels of typical marker genes of individual astrocyte lineages. g, UMAP plots of Tri-IPC-derived astrocytes projected to the reference mouse astrocytes. Cells are colour coded by lineages and the legend can be found in panel h. h, Identities of Tri-IPC-derived astrocytes mapped by Seurat label transfer. i, UMAP plot of human astrocytes at the infancy stage. Cells are colour coded by lineages and the legend can be found in panel l. j, UMAP plots of human astrocytes showing the expression levels of typical marker genes of individual astrocyte lineages. k, UMAP plots of Tri-IPC-derived astrocytes projected to the reference human astrocytes. Cells are colour coded by lineages and the legend can be found in panel l. l, Identities of Tri-IPC-derived astrocytes predicted by SingleCellNet (top) or mapped by Seurat label transfer (bottom). m, Proportion of each SingleCellNet-predicted cell type across GBM samples.
Extended Data Fig. 18 Neocortical cell association with human cognition and brain disorders.
a, UMAP plot showing the standardized per-cell SCAVENGE trait relevance score (TRS) for Alzheimer’s disease. b, Top, boxplots showing the standardized SCAVENGE TRS for Alzheimer’s disease across cell types. Boxplot centre: median; hinges: the 25th and 75th percentiles; whiskers: standard error. Bottom, bar plots showing the proportion of the cells with enriched trait relevance for Alzheimer’s disease across cell types. Two-sided hypergeometry test; *FDR < 0.01 & odds ratio > 1.4. c, Boxplots showing standardized SCAVENGE TRS for nine cognitive and disease traits across regions. Boxplot centre: median; hinges: the 25th and 75th percentiles; whiskers: standard error. Two-sided hypergeometry test; *FDR < 0.01 & odds ratio > 1.4. d, Heatmap showing the proportion of the cells with enriched trait relevance across regions. Tiles with significant TRS enrichment (two-sided hypergeometric test, *FDR < 0.01 & odds ratio > 1.4) are annotated by their odds ratios. e, Boxplots showing standardized SCAVENGE TRS for nine cognitive and disease traits across age groups. Boxplot centre: median; hinges: the 25th and 75th percentiles; whiskers: standard error. Two-sided hypergeometry test; *FDR < 0.01 & odds ratio > 1.4. f, Heatmap showing the proportion of the cells with enriched trait relevance across developmental stages. Tiles with significant TRS enrichment (two-sided hypergeometric test, *FDR < 0.01 & odds ratio > 1.4) are annotated by their odds ratios.
Supplementary information
Supplementary Tables
Supplementary Tables 1–25.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, L., Wang, C., Moriano, J.A. et al. Molecular and cellular dynamics of the developing human neocortex. Nature 647, 169–178 (2025). https://doi.org/10.1038/s41586-024-08351-7
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s41586-024-08351-7
This article is cited by
-
TSC tunes progenitor balance and upper-layer neuron generation in neocortex
Nature (2026)
-
Childhood brain tumors instruct cranial hematopoiesis and immunotolerance
Nature Genetics (2026)
-
Single rosette-based generation of uniform cortical assembloids recapitulating cellular interactions between neurons and glial cells
Nature Communications (2025)
-
Molecular cartography of the human down syndrome and trisomic mouse brain
Nature Communications (2025)
-
Dual lineage origins contribute to neocortical astrocyte diversity
Nature Communications (2025)
