
Abstract
Lung cancer is an important global health problem, and it is defined by abnormal growth of the cells in the tissues of the lung, mostly leading to significant morbidity and mortality. Its timely identification and correct staging are very important for proper therapy and prognosis. Different computational methods have been used to enhance the precision of lung cancer classification, among which optimization algorithms such as Greylag Goose Optimization (GGO) are employed. These algorithms have the purpose of improving the performance of machine learning models that are presented with a large amount of complex data, selecting the most important features. As per lung cancer classification, data preparation is one of the most important steps, which contains the operations of scaling, normalization, and handling gap factor to ensure reasonable and reliable input data. In this domain, the use of GGO includes refining feature selection, which mainly focuses on enhancing the classification accuracy compared to other binary format optimization algorithms, like bSC, bMVO, bPSO, bWOA, bGWO, and bFOA. The efficiency of the bGGO algorithm in choosing the optimal features for improved classification accuracy is an indicator of the possible application of this method in the field of lung cancer diagnosis. The GGO achieved the highest accuracy with MLP model performance at 98.4%. The feature selection and classification results were assessed using statistical analysis, which utilized the Wilcoxon signed-rank test and ANOVA. The results were also accompanied by a set of graphical illustrations that ensured the adequacy and efficiency of the adopted hybrid method (GGO + MLP).
Similar content being viewed by others

Introduction
Lung cancer is a highly significant and fatal illness globally. According to the latest estimates from the World Health Organization (WHO), over 7.6 million fatalities occur annually globally as a result of lung cancer. Furthermore, the global incidence of cancer is projected to increase, reaching around 17 million cases by 20301. Early detection of cancer is crucial since it has a tendency to metastasize and becomes incurable when it spreads extensively. Diagnosing lung cancer is challenging due to the manifestation of symptoms at the advanced stage, making it very difficult to achieve successful treatment outcomes, Fig. 1 shows Comparison between healthy lung and cancer lung. Imaging methods such as Computed Tomography (CT), Positron Emission Tomography (PET), Magnetic resonance imaging (MRI), and X-ray are used to take images of lungs for assessment. Lung cancer detection employed image processing and deep learning techniques where precision can be enhanced by implementing these methodologies. Detecting and determining the form, size, and location of a tumor is a challenging undertaking. Early detection is crucial for efficient time management, as it allows for necessary medical interventions2. Nevertheless, radiologists continue to have challenges in discerning between malignant and benign nodules. Distinguishing between malignant nodules and benign ones by visual inspection is subjective and the outcomes vary across various observers and instances. Typically, proficient radiologists have superior accuracy in categorizing nodules compared to novice radiologists. The need for dependable and unbiased analysis has spurred the creation of computer-assisted systems3.

Comparison between healthy lung and cancer lung.
The use of Machine Learning (ML) and Neural Networks (NN) in the categorization of Lung Cancer is not a new4. Employing machine learning techniques, such as optimizer and ensemble regression models, can be advantageous in attaining promising outcomes for both classification and regression problems5. Medical image recognition techniques can be applied as an initial diagnostic tool that hints about a potential illness6. Choosing appropriate features and building a highly efficient classifier for pulmonary nodules are crucial in the development of reliable Content-Based Image Retrieval (CBIR) and Computer-Aided (CAD) systems. Typically, CAD systems have two main stages: feature extraction and categorization. CBIR often incorporates a substantial number of visual elements, such as texture, form, and granulometry, in order to construct the search index7. Constructing machine learning architectures necessitates a proficient amalgamation of hyperparameters to enhance classification performance and precision. Tackling combinatorial issues with manual approaches can be daunting and hampers efficiency. Nevertheless, metaheuristic algorithms have been suggested as a means to optimize the process of acquiring the most optimal combination of hyperparameters needed for enhanced performance. Metaheuristic algorithms are optimization methods that draw inspiration from nature. They aim to discover optimal solutions characterized by local search, global search, and sometimes randomization. These algorithms are known for their great performance in finding acceptable optimization solutions. Swarm intelligence algorithms have effectively addressed intricate real-world challenges in engineering, medical sciences, and other scientific fields by achieving minimal computational power8. Metaheuristic algorithms are optimization approaches that employ iterative strategies to explore a vast search space and identify the optimal solution. The metaheuristic method is utilized to get the optimal combination of weights necessary for solving the feature extraction and classification challenge9.
Greylag Goose Optimization (GGO) algorithm has demonstrated encouraging outcomes in many optimization problems, encompassing feature selection and parameter optimization in several sectors, such as healthcare, finance, and engineering. We chose GGO as a metaheuristic optimization technique because of its proven track record in comparable optimization problems and its distinctive characteristics that may offer benefits over alternative optimization approaches. The purpose of integrating ML methods with a metaheuristic algorithm is to optimize the performance of these approaches in terms of accuracy. Enhancing performance in illness detection, such as lung cancer, can lead to improved diagnostic precision and prompt treatment. In this paper, incorporating the GGO metaheuristic algorithm with MLP can enhance parameter optimization and increase its capacity to learn and categorize intricate patterns within the data. Consequently, this work seeks to integrate the GGO-MLP algorithm with specific preprocessing strategies in order to enhance the classification accuracy of lung cancer textual data. Initially, the input data is subjected to preprocessing, which involves scaling, normalization, and removal of null values. Following pre-processing, the subsequent task involves extracting the ideal collection of features that might augment the accuracy of lung cancer categorization. The GGO method is built using a binary format for the purpose of extraction to find the cancerous lung states. The subsequent step is categorizing the lung illness according to the extraction of distinctive features. The classification step utilizes many classifiers such as SVC, DTC, RFC, KNC, and MLP. The findings indicated that the Multilayer Perceptron (MLP) is the most optimal classifier. The hyperparameter of the MLP model is tuned using GGO, and the performance is evaluated against six other optimizers (SC, MVO, PSO, WOA, GWO, and FOA). The GGO with MLP model yielded the most optimal outcomes for the classification of lung cancer.
The specific enhancements proposed in our methodology are:
-
1.
Normalization and scaling Data normalization and scaling were performed to standardize the input features. This step is necessary to ensure that all features contributed equally to the model training process and to improve the convergence speed of the optimization algorithms.
-
2.
Choosing optimization techniques We used seven different binary optimization algorithms, Binary Greylag Goose Optimization (bGGO), Binary Sine Cosine Algorithm (bSC), Binary Mean Variance Optimization (bMVO), Binary Particle Swarm Optimizer (bPSO), Binary Whale Optimization Algorithm (bWOA), Binary Gray Wolf Optimizer (bGWO) and Binary Falcon Optimization Algorithm (bFOA). Each technique was used to identify the most relevant features, thus reducing the dimensionality of the data and improving classification performance.
-
3.
Feature selection using bGGO algorithm Specifically, the bGGO algorithm was used to select the optimal subset of features. The goal was to remove irrelevant and redundant features, thus simplifying the input data and improving the efficiency and accuracy of the classification models.
-
4.
Choosing machine learning classifiers We evaluated several machines learning classifiers, including Support Vector Classifier (SVC), Decision Tree (DT), Random Forest Classifier (RFC), K-Nearest Neighbors (KNN), and Multi-Layer Perceptron (MLP). This diverse selection allowed us to compare the performance of different models with the selected features.
-
5.
Parameter tuning using GGO For MLP classifier, we proposed to use the GGO algorithm to optimize its parameters. The GGO algorithm iteratively adjusts the parameters to find the optimal configuration that gives the highest classification accuracy. The algorithm starts by generating a set of solutions, each representing a different set of MLP parameters. Each solution was evaluated based on its performance on the validation set and assigned a fitness score.
-
6.
Statistical analysis The results of feature selection and classification were evaluated using statistical tests such as Wilcoxon signed-rank test and ANOVA test. These tests provided an accurate evaluation of the performance improvements achieved by our proposed method.
The structure of this paper is as follows: Section "Related work" provides an overview of relevant state-of-the-art literature. Section "Material and methods" provides an elaborate depiction of the proposed approach. The experimental results as well as discussion are presented in Section "The proposed framework". Section "Experimental results" presents the conclusions and future directions.
Related work
Due to the potential for increased survival rates, researchers are primarily focused on developing novel methods for the automated identification and diagnosis of significant lung nodules, as early detection is crucial in the case of lung cancer. This section presents research findings relating to lung cancer classification, based on ML/DL and textural/image analysis. Mohamed et al.9 suggested a hybrid convolutional neural network (CNN) and metaheuristic algorithm. Initially, they constructed a CNN structure and subsequently calculated the solution vector of the model. The obtained solution vector was utilized in the Ebola optimization search algorithm (EOSA) to determine the optimal combination of weights and bias for training the CNN model to effectively address the classification challenge. Upon completing extensive training of the EOSA-CNN hybrid model, the researchers achieved the best configuration, resulting in good performance. The lung cancer dataset from the Iraq-Oncology Teaching Hospital/National Center for Cancer Diseases (IQ-OTH/NCCD), which is available to the public, was used for experimentation. The results indicated that the EOSA metaheuristic algorithm achieved a classification accuracy of 0.9321. In addition, they computed and reported the performance comparisons of EOSA-CNN with other approaches, including GA-CNN, MVO-CNN, LCBO-CNN, WOA-CNN, SBO-CNN, and the traditional CNN. The findings indicated that EOSA-CNN had a specificity of 0.7941, 0.9328, and 0.97951, as well as a sensitivity of 0.9038, 0.9071, and 0.13333 for normal, malignant, and benign cases, respectively. Ren et al.10 introduced is a novel hybrid framework named LCGANT, including of two primary components. The initial component is a deep convolutional GAN (Generative Adversarial Network), which is capable of generating synthetic lung cancer images. The second component is a VGG-DF model, which incorporates regularization and transfer learning techniques, to accurately categorize lung cancer images into three distinct classifications. Their attained result for accuracy was 99.84% ± 0.156%, for precision was 99.84% ± 0.153%, for sensitivity was 99.84% ± 0.156%, and for F1-score was 99.84% ± 0.156%. Ananya Bhattacharjee et al.11, outlined a precise approach for identifying cancerous nodules in computed tomography imaging. They utilized a combination of an optimized random forest classifier and a K-means visualization tool to achieve the most accurate findings. The model's hyperparameters were fine-tuned to ensure optimal performance, and the visualization tool was used to distinguish between malignant and non-malignant clusters. Among the four experiments conducted for hyperparameter optimization, the most successful model accurately identified cases as either malignant or non-malignant and obtained a 10-Fold cross-validation accuracy of 92.14% on the LIDC-IDRI dataset. Furthermore, the visualization configuration that yielded the best results achieved an inertia score of 16.21, which was the lowest, and a silhouette score of 0.815, which was the greatest. Vijh et al.12 designed a pulmonary neoplasm diagnostic system utilizing a range of image processing methodologies. The Whale Optimization Algorithm (WOA) is utilized to pick the most optimal and conspicuous subset of features. They proposed the WOA_SVM, a novel approach for automating the diagnosis of lung CT images to determine their normality or abnormality. The suggested methodology's performance was assessed by measuring accuracy, sensitivity, and specificity. Utilizing a radial bias function support vector kernel, the results indicate an accuracy of 95%, sensitivity of 100%, and specificity of 92%. Shakeel et al.13 examined biological characteristics associated with lung cancer through the application of neural and soft computing methodologies. The pertinent features were chosen based on the redundancy relevancy feature criterion and then inputted into the feature spaces and subjected to the Wolf prey searching method. The features with the highest fitness value were chosen and utilized as optimized ones to remove the weak classifiers. The testing characteristics were classified using the discrete AdaBoost optimized ensemble learning generalized neural network (DAELGNN), which effectively trained and classified the features into normal and lung cancer features. The system's efficiency was assessed by examining the testing and training characteristics, resulting in a minimum error rate of 0.0212 and a high prediction rate of 99.48%. Nanglia et al.4 suggested technique combines a Support Vector Machine with a Feed-Forward Back Propagation Neural Network to develop a hybrid approach that effectively reduces the computational complexity of lung cancer classification. Their suggested KASC hybrid algorithm approach is implemented by combining the effective SURF feature extraction technology, the efficient optimization technique GA, and SVM with the polynomial kernel using FFBPNN. The hybridization approach yielded significantly improved performance metrics for lung cancer classification on a dataset of 500 CT images. Specifically, the accuracy, average precision, recall, and f-score achieved were 98.08%, 98.17%, 96.5%, and 97%, respectively. Nancy et al.14 proposed machine learning may be used in the process of diagnosing lung cancer. They employed the CLAHE algorithm to enhance the overall image quality. The K Means approach is used when there is a requirement to segment an image. In this instance, feature selection is achieved through the utilization of the Particle Swarm Optimization (PSO) method. Subsequently, the images undergo categorization using the SVM, ANN, and KNN algorithms to classify them. Compared to other approaches, PSO-SVM has exceptional performance in accurately identifying instances of lung cancer, with an accuracy of 97.6% and a specificity of 99%. Table 1 displays a comparison with state-of-the-art for the most referenced studies.
Material and methods
Greylag Goose Optimization (GGO) Algorithm
The optimization approach presented in this study is referred to as the Greylag Goose Optimization (GGO) algorithm. The GGO method starts by producing a set of individuals in a random manner, as seen in Algorithm (1). Every participant presents a potential solution that might be considered as a candidate solution to the problem. The GGO population consists of individuals denoted as Yi (i = 1, 2,…, n), where n is the total number of individuals in the population, as a gaggle. An objective function, denoted as Fn, is chosen to assess the individuals inside the group. By evaluating the objective function for every participant (agent) Yi, the optimal solution (leader) is determined and denoted as Z. The GGO algorithm utilizes the Dynamic Groups behavior to categorize individuals into two groups: an exploration group (n1) and an exploitation group (n2). The total number of solutions inside each group is dynamically controlled throughout each iteration based on the optimal solution. GGO commences the groups with an equal distribution of 50% exploration and 50% exploitation. Subsequently, the total number of agents in the exploration group (n1) is reduced, while the number of agents in the exploitation group (n2) is raised. However, if the objective function value of the best solution remains same for three consecutive iterations, the algorithm will begin to expand the number of agents in the exploration group (n1) in order to obtain a different best solution and hopefully avoid local optima18. Exploration has two important functions; it helps identify interesting regions inside the search space and prevents stagnation at local optima by advancing towards the optimal solution. Striving for optimal resolution by implementing this strategy, the geese explorer will actively seek out favorable new areas to investigate in close proximity to its present location. This is achieved by iteratively evaluating many potential adjacent choices in order to choose the optimal one based on its fitness. The GGO method employs the following equations to do this task, updating the B and D vectors as B = 2b.m1 − b and D = 2.m2 throughout iterations with a parameter adjusted linearly from 2 to 0:
where Y(t) presents an individual at iteration t. The Y∗(t) denotes the optimal location of the leader (best solution). The Y(t + 1) represents the adjusted location of the individual. The values of m1 and m2 values are randomly changing within the range of 0 to 1.
The equation below will be employed by selecting three random search individuals, referred to as YPaddle1, YPaddle2, and YPaddle3, to ensure that the individuals are not influenced by a single leader position, hence promoting greater exploration. The current search agent's position will be changed as follows for |B| is greater than or equal to 1.
where the values of w1, w2, and w3 are adjusted within the range of 0 to 2. The values of w1, w2, and w3 are updated within the range of 0 to 2. The parameter p exhibits an exponential decrease and is determined by the following equation:
where iteration number is denoted as “t”, and “tmax” specifies the maximum number of iterations.
The second updating procedure is as follows for m3 values greater than or equal to 0.5, where the values of b and B vectors values are reduced.
where a is a fixed value, l is a randomly selected value from range of − 1 to 1. The w4 parameter is adjusted within the range of 0 to 2, whereas m4 and m5 parameters are modified within the range of 0 to 1.
Exploitation operation
The exploitation group is responsible for enhancing the existing solutions. The GGO determines the individual with the best fitness at the end of each round and grants them corresponding recognition. The GGO utilizes two distinct strategies in order to accomplish its purpose of exploitation, which is elaborated below.
Moving towards the best solution
The subsequent equation is employed to advance towards the optimal solution. The three sentries (solutions), YS entry1, YS entry2, and YS entry3, direct other agents (YNonS entry) to adjust their locations towards the predicted location of the prey. The subsequent equations illustrate the updating locations procedure.
where the values of B1, B2, B3 are determined by the equation B = 2b.m1 − b, where b is a constant. Similarly, the values of D1, D2, D3 are determined by the equation D = 2m2. The modified population locations, Y(t + 1), can be calculated by taking the average of the three solutions: Y1, Y2, and Y3 as follows.
The Triangle Inequality is the second mathematical lemma that may be employed in the analysis of the GGO algorithm throughout the exploitation phase. The Triangle Inequality is a fundamental principle in metric spaces, asserting that the length of any side of a triangle is always less than or equal to the sum of the lengths of the other two sides. For GGO, this implies that the distance between any two individuals is less than or equal to the combined distances of these agents to a third individual in the search space. The most favorable option is situated in close proximity to the optimal response (leader) during flight. As a result, certain individuals are motivated to seek improvements by exploring areas adjacent to the optimal solution, referred to as YFlock1. In order to address the issue of local optima, the GGO employs the aforementioned procedure, which impacts both local and global optima, utilizing the subsequent equation.
The Law of Large Numbers is the third mathematical concept that may be employed in the investigation of the GGO algorithm to effectively address the issue of local optima. The Law of Large Numbers is an essential concept in probability theory which asserts that as the size of the sample grows, the average of the sample approaches the average of the entire population. Within the framework of GGO, this implies that as the quantity of individuals in the swarm grows, the swarm as a collective will progressively approach the global optimum.
The GGO provides outstanding exploration capabilities by employing a mutation approach and scanning participants of the exploration group. The GGO has the ability to delay convergence due to its robust exploring abilities. Algorithm 1 includes the GGO pseudo-code, as we Initially provide GGO with essential facts, including the size of the population, rate of mutation, and number of iterations. The GGO thereafter divides the participants into two groups: those engaged in exploratory work and the other involved in exploitative labor. The GGO approach adjusts the size of each group while it iteratively searches for the optimal solution. In order to introduce diversity and conduct thorough investigation, the GGO employs a random reordering of the responses throughout each iteration.
Within a single iteration, a solution parameter from the exploration group may transfer to the exploitation group in the manner described below. The GGO's exclusive approach ensures the leader's continuous tenure in position during the process. The GGO algorithm seeks to update the locations of both the exploration group (n1) and the exploitation group (n2). The parameter m1 is modified iteratively according to the equation m1 = \(d(1- \frac{t}{{t}_{max}})\), where t represents current iteration, d denotes a constant, and \({t}_{max}\) specifies the number of iterations. After each iteration, GGO modifies the individuals in the search space and randomly shuffles their order to shift their roles between the exploration and exploitation groups. During the last stage, GGO retrieves the optimal solution.

Algorithm 1: GGO algorithm.
Binary GGO Optimization Algorithm
The GGO optimization algorithm is a more effective approach for improving the feature selection of MLP parameters. The GGO utilizes the binary format for feature selection.
Feature selection problems revolve around a restricted search space that just encompasses binary values of 0 and 1. The objective is to determine the significance of a particular feature. Therefore, the ongoing GGO values are converted to a binary [0, 1] format in the binary GGO technique suggested in this section, in order to align with the feature selection process. The fundamental purpose of this procedure, as outlined in Eqs. (8, 9), is to convert the continuous data into binary data using the following Sigmoid function.
where \({Bi}_{t}^{*}\) represents the best solution at specific iteration t. Algorithm 2 presents the proposed bGGO stages utilized to choose the optimal feature set, enhancing the Caries' case classification accuracy.

Algorithm 2: bGGO algorithm.
Multilayer Perceptron (MLP) Model
Multilayer perceptron models, derived from the neural architecture of the human brain, have significant aptitude in representing the nonlinear behavior of intricate systems. Moreover, these models provide the capability to tackle prediction problems with nonlinear structure. This model functions by acquiring knowledge about the problem-solving procedure in order to get the desired outcome by identifying the underlying relationship inside the process. In order to achieve this objective, a substantial amount of data is utilized during the training phase, leveraging the discovered relationship in that phase to compute the desired output. Among several neural network models, the back-propagation network is the most commonly utilized. This network is composed of layers, each containing parallel-acting units known as neurons. Each layer is fully interconnected with the preceding and subsequent layers19.
The proposed framework
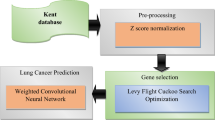
In this paper, the initial phase involves data processing, which includes removing null values, normalizing, and scaling data. The primary focus in this stage is to prepare and expand the input data. This study employed feature selection approaches to carry out 7 optimization techniques in binary format- namely, Greylag Goose Optimization (GGO)18, Sine Cosine Algorithm (SC)20, Mean variance optimization (MVO)21, Particle Swarm Optimizer (PSO)22, Whale Optimization Algorithm (WOA)23, Gray Wolf Optimizer (GWO)24, and Falcon Optimization Algorithm (FOA)25. The second phase involves the process of selecting features, using the proposed feature selection approach. The pertinent features are subsequently extracted using bGGO. The objective of this step is to determine the optimal characteristics that will enable precise classification of the input data. This step offers the advantage of diminishing the overall quantity of features by deleting irrelevant ones. The input data was classified using ML classifiers, with features picked based on the bGGO. The ML models proposed in this study include the Support Vector Classifier (SVC)26, Decision Tree (DT)27, Random Forest Classifier (RFC)28, 1 K-Nearest Neighbors (KNN)29, and multilayer perceptron (MLP)30. The parameters of the MLP are optimized to effectively utilize the proposed optimization technique. The objective of this stage is to choose the optimal set of classification parameters. The algorithm begins by producing a collection of solutions for different parameter setups. Each key, or individual Greylag Goose, is allocated a fitness score depending on its performance on a validation set. In order to identify the optimal solutions, individuals within the population are systematically traversed over the search space. GGO utilizes weighted vectors to direct individuals to suitable destinations. These vectors are calculated using the fitness ratings of population. The algorithm consistently adjusts the placements of the participants to accurately reflect the optimal solution. GGO employs an iterative process to progressively improve the solutions with the goal of reaching the ideal configuration of MLP parameters. Once the convergence threshold is attained, the algorithm terminates after a specific number of iterations. In this case, the optimal solution is chosen based on the parameter configuration with the highest fitness value. This research explores how GGO can enhance the tuning parameters of MLP (Multilayer Perceptron). The sequential process of the proposed framework is visually depicted in Fig. 2.

The proposed lung cancer classification framework.
Experimental results
This section describes the assessment of the proposed algorithm in several experimental conditions. The tests employed traditional mathematical functions as reference points to ascertain their minimum values within a designated search area. These functions are frequently utilized in the previous research to evaluate the effectiveness of optimization strategies, and there are several optimization methods available in the literature. This study conducted a comparison analysis to demonstrate the higher performance and effectiveness of the proposed algorithm, Greylag Goose Optimization (GGO), compared to six known optimization techniques. The algorithms GGO, SC, MVO, PSO, WOA, GWO, and FOA were chosen because to their extensive acknowledgment and practical significance. The study platform employed the following technical specifications: a primary memory of 16 GB, an Intel Core i7 CPU, anda graphics processing unit (GPU) utilizing a GeForce RTX2070 Super with 8 GB of RAM. On the other hand, the software specifications were made up of Ubuntu 20.04 as the operating system, TensorFlow 1.15, CUDA9.0, Cudnn7.1, and Python 3.7 for the Spider Integrated Development Environment (IDE).
Dataset description
Machine learning and data science specialists may utilize this dataset to construct prediction models for diagnosing lung cancer, examine the influence of different cancer-related characteristics, and devise algorithms to enhance cancer therapy and prevention. This research uses a data set termed "Lung Cancer Dataset", which was gathered and submitted to Kaggle. The efficacy of cancer classification and prediction systems enables individuals to ascertain their susceptibility to cancer at a minimal expense. Moreover, it aids specialists in making informed decisions in accordance with their cancer risk profile. The data is gathered from the online lung cancer prediction system on the website, available at: https://www.kaggle.com/datasets/mysarahmadbhat/lung-cancer.
The input features of the used dataset consist of Gender, Smoking, Age, Yellow fingers, Peer_pressure, Anxiety, Chronic Disease, Swallowing Difficulty, Allergy, Fatigue, Wheezing, Alcohol, Shortness of Breath, Coughing, and Chest pain. The attributes count is 16, and there are 284 occurrences. These variables are used to classify the output variable, which is Lung Cancer. Figure 3 depicts a scatter plot that showcases the relationship between the input and output variables of the Lung Cancer dataset.

Scatter plot for each feature in the dataset.
Figure 4 exhibits the correlation matrix, which is a helpful statistical instrument for analyzing the relationship between variables in the dataset. It often generates a matrix that shows the pairwise correlations between all variables. The correlation coefficients, which span from − 1 to + 1, signify the relative significance and direction of the interactions. In order to examine the relationships, patterns, and potential predictors within the data, we may employ a correlation matrix to discover variables that have positive or negative correlations. This information is crucial for predictive modeling as it aids in the selection of pertinent characteristics, the reduction of dimensionality, and the identification of multicollinearity difficulties31.

A correlation matrix between features in the dataset.
Feature selection results
This study employed feature selection techniques to carry out seven optimization algorithms in binary format, specifically: Greylag Goose Optimization (GGO), Gray Wolf Optimizer (GWO), Mean variance optimization (MVO), Whale Optimization Algorithm (WOA), Sine Cosine Algorithm (SC), Particle Swarm Optimizer (PSO), and Falcon Optimization Algorithm (FOA). Table 2 presents an evaluation of the outcomes attained by different feature selection techniques. The table clearly illustrates that the proposed bGGO achieved the best results against the other binary feature selection algorithms in the term of average error, average select size, average fitness, best fitness, worst fitness and standard deviation fitness. Lower values for average error, average select size, average fitness, best fitness, worst fitness and standard deviation fitness indicate the best results. The average error, average select size, average fitness, best fitness, worst fitness and standard deviation fitness values are 0.7743031, 0.7271031, 0.8375031, 0.7393031, 0.8378031 and 0.6598031, respectively.
The Fig. 5 displays a graph that compares the average error of the proposed feature selection technique with six other feature selection strategies. The bGGO technique has the lowest average error, so showcasing its robustness, as shown in this figure.

The Average Error of the Results Acquired using bGGO, the Proposed Feature Selection Technique.
Table 3 illustrates the superior performance of the proposed bGGO technique compared to previous feature selection strategies across many measures. The p-values were computed by comparing the outcomes of each algorithm pair, revealing that the proposed feature selection technique (bGGO) exhibits statistically significant superiority. The null hypothesis and the alternative hypothesis are the primary hypotheses under consideration in this study. The null hypothesis, shown as H0, assumes that the mean values (m) of bGGO are equal to the mean values of bGWO, bPSO, bWOA, bSC, bMVO, and bFOA. However, the H1 hypothesis does not consider the averages of the algorithms. To conduct this inquiry, the Wilcoxon rank-sum test was employed. The results of the Wilcoxon rank-sum test are presented in Table 3. The proposed technique has statistical superiority over previous techniques, as seen by its lower p-value (p < 0.005). A one-way analysis of variance (ANOVA) test was performed to see if there were statistically significant differences between the proposed bGGO technique and the other binary optimization techniques. The results of the ANOVA test are presented in Table 4. The results shown in these tables confirm the superiority, significance, and effectiveness of the proposed feature selection technique.
The plots in Fig. 6 illustrate the results achieved by the proposed feature selection technique. The figure employs residual plots, quartile–quartile (QQ), homoscedasticity, and heatmap to showcase the effectiveness and reliability of the proposed technique. The results shown in the QQ plot demonstrate a strong correlation with a linear trend, revealing that the selected features are reliable in correctly determining the presence of lung cancer. Moreover, the focus on results is further underscored by the reported outcomes in the homoscedasticity and residual plots. Additionally, the superiority of the proposed technique is further evidenced by the heatmap depicted in Fig. 5, which clearly illustrates that the proposed technique surpassed the other six binary feature selection strategies. The effectiveness of the bGGO technique is confirmed by the heatmap, as it achieved the most optimal results compared to other feature selection strategies.

Analysis plots of the obtained outcomes based on bGGO, the proposed feature selection technique.
Classification results
A supplementary experiment was conducted to showcase the influence of the feature selection technique on the classification findings. Machine learning classifiers were employed to categorize the input data based on characteristics chosen according to the bGGO. The bGGO technique was employed to enhance the network's characteristics with the aim of optimizing performance. The classification outcomes for several machine learning models following feature selection are displayed in Table 5. The ML models listed in this table include the Support Vector Classifier (SVC), Decision Tree Classifier (DTC), Random Forest Classifier (RFC), K Neighbors Classifier (KNC), and multilayer perceptron (MLP). The MLP model achieved the greatest values of 0.9180327, 0.92668, 0.9091, 0.9133, 0.9231, 0.9199 and 0.935 for accuracy, sensitivity, specificity, p-value, n-value, F-score and Area Under the ROC Curve (AUC) respectively. The MLP model acts as a fitness function and is optimized using the GGO algorithm and six additional optimization techniques. The outcomes for classification of the seven optimization algorithms, using the fitness function of the MLP model, are presented in Table 6. The findings of GGO combined with MLP are compared to those of SC, GWO, PSO, WOA, FOA, MVO with MLP to demonstrate the superiority of the proposed approach (GGO + MLP). The GGO + MLP approach demonstrated superior performance with accuracy, sensitivity, specificity, p-value, n-value F-score and Area Under the ROC Curve (AUC) with values of 0.983837, 0.977337, 0.990237, 0.989957, 0.977961, 0.983607 and 0.993, respectively. Various optimizers were employed to refine the parameters of the MLP, and the outcomes were investigated and assessed. The data shown in this table clearly demonstrates that the proposed approach surpasses the previous optimization approaches. These findings clearly show the necessity of feature selection in order to enhance the accuracy of the classification results.
Table 7 demonstrates the parameter settings for Greylag Goose Optimization (GGO), Gray Wolf Optimizer (GWO), Mean variance optimization (MVO), Whale Optimization Algorithm (WOA), Sine Cosine Algorithm (SC), Particle Swarm Optimizer (PSO), and Falcon Optimization Algorithm (FOA).
The efficacy of the proposed GGO + MLP approach for optimizing the objective function is confirmed by a comparative analysis with other optimization algorithms utilizing the MLP model. The accuracy and histogram of the results obtained using GGO + MLP are presented in the accuracy plots depicted in Figs. 7 and 8, correspondingly. The accuracy plot demonstrates that the proposed approach surpassed the other six optimization algorithms while using the MLP model. In addition, the accuracy histogram plot demonstrates the effectiveness of the proposed GGO + MLP approach in accurately classifying lung cancer cases in the input dataset.

Assessing the accuracy of the GGO + MLP approach and optimization algorithms using the MLP model, considering the objective function.

Histograms of the accuracy results achieved by GGO + MLP approach as well as alternative combinations of optimization techniques with MLP models.
The statistical differences between the proposed algorithm and other competing algorithms are evaluated using ANOVA and Wilcoxon's rank-sum tests. The ANOVA results for the proposed GGO + MLP approach are presented in Table 8. The Wilcoxon's rank-sum test, as presented in Table 9, is employed to evaluate the presence of a statistically significant difference in the outcomes produced by the algorithms. A p-value below 0.05 indicates statistically significant supremacy. The outcomes reveal that the GGO + MLP approach is superior and shows the statistical significance of the approach.
The statistical findings in Table 8 demonstrate the comparative efficiency of the GGO + MLP approach compared to other five optimizers (SC, GWO, PSO, WOA, FOA, and MVO) with MLP model on benchmark functions. Table 9 illustrates that the GGO + MLP approach outperformed the other six optimizers using the MLP model due to its employment of two separate exploitation procedures in each cycle. The initial procedure entails progressing towards the most optimal solution identified at a specific point, whereas the second approach involves aggressively pursuing superior solutions in close vicinity. The GGO + MLP approach can get exceptional results by implementing these procedures to effectively use the search space. In order to achieve optimal use, it is imperative to maintain a harmonious equilibrium between exploration and exploitation within the search domain. Furthermore, it is crucial to initiate the exploitation process at an early stage in every iteration and gradually augment the total number of the participants in exploitation group. In general, the GGO algorithm demonstrated superior performance compared to other optimizers on most of the unimodal benchmark functions.
Figure 9 exhibits the residual plot, QQ plot, heteroscedasticity plot, and heat map for this scenario. The figure employs residual plots, quartile-quartile (QQ) plots, and homoscedasticity to showcase the effectiveness and robustness of the proposed GGO + MLP approach. The efficacy of the selected features in case categorization is demonstrated by the values depicted in the QQ plot, which approximately fit to a linear trend. The data shown in the residual and homoscedasticity plots provide more evidence to support these results. Moreover, the superiority of the proposed approach is further evidenced by the heatmap depicted in Fig. 5, which clearly illustrates that the proposed approach outperformed the other six binary feature selection techniques. The effectiveness of the GGO + MLP approach is confirmed by the heatmap, as it achieved the most optimal results compared to other feature selection strategies. The analysis plots shown in Fig. 8 demonstrate the effectiveness of the proposed GGO + MLP approach in addressing the optimization concerns for categorizing lung cancer patients discussed in this article.

Analysis plots of the obtained results using the proposed GGO + MLP approach.
To verify the performance of the proposed model, we used two benchmark functions, namely, Rastrigin function and Ackley function. Table 10 demonstrates the results of GGO algorithm compared to others optimization algorithms using Rastrigin function using the metrics, average error, average select size, average fitness, best fitness, worst fitness and standard deviation fitness. As demonstrated in Table 10, GGO algorithm gives the best results in terms of average error, average select size, average fitness, best fitness, worst fitness and standard deviation fitness.
Table 11 demonstrates the results of GGO algorithm compared to others optimization algorithms using Ackley function using the metrics, average error, average select size, average fitness, best fitness, worst fitness and standard deviation fitness. As demonstrated in Table 11, GGO algorithm gives the best results in terms of average error, average select size, average fitness, best fitness, worst fitness and standard deviation fitness.
Table 12 demonstrates a performance comparison of proposed work with a recent existing system.
Statistical analysis of reference models results
Among the visualization methods applied in statistics of the results of this prototypical approach, the description of the distribution of the results is performed. A KDE Plot is given in Fig. 10, which is comprehensive in analyzing models' accuracy. This graph output measures differences in both norms and fluctuations between various models of the algorithm in question. The role of observation is vital in enhancing the efficacy of such models since it helps to identify the particular models that are performing well.

KDE plot of accuracy of reference models results.
The KDE (Kernel Density Estimation) plots help to estimate the probability density function of a continuous random variable. Here, the graph shows the error levels of the reference models in the x-axis and then the number of times an error level happens in the y-axis. The KDE plot assists researchers in understanding the distribution behavior of the accuracy by identifying frequent routines, examples of modes and often some clusters of high-performant models.
Therefore, a Box Plot with Swarm Overlay illustrates the distribution of precision in addition to the reference models in Fig. 11. This way, it is not only a short description of the accuracy values but also a comparison of the models, depicting the median, quartiles, and possibly the outliers. Annotations on individual parts of data clouds are added, including united data. This detail lifts the level of resolution and provides information about the accuracy and deviations from the most common form of an example.

Box plot with swarm overlay: accuracy by reference models.
Figure 12 shows a Pairplot with Regression Lines for the Reference Models Results. The network diagram technique thus helps examine the interrelation of all the variables considered to be of particular interest, such as accuracy, sensitivity, specificity, and so forth, for all the considered reference models. Each relation between the variables is sketched as a scatterplot, with the lines representing regression (showing the trend between these variables) as well.

Pairplot with Regression Lines for Reference Models Results.
Figure 13 is the representation of a Regression Plot; this illustration reveals the relationship between Accuracy and F-Score when using the Reference Models Results. These two observations graphically demonstrate the relationship between these two most important metrics, thus helping researchers quantify the matter of a tradeoff between accuracy and F-score. The regression line is fitted to the inter-connected data plots, which advertises the direction and the strength of Accuracy, and F-Score link relative to different reference models.

Regression Plot: Accuracy vs. F-Score for Reference Models Results.
Statistical analysis of optimization results
The KDE chart in Fig. 14 highlights the accuracy distribution from the specimen of the optimization process. The visualization will show the levels of dispersion and measure a central tendency for the reference models, just like a KDE plot. This will help with understanding the variability and accuracy. The curve shape and density analyses provide a way to see the trends and patterns in the optimization outcomes so that different strategies may be compared.

KDE plot of accuracy of optimization results.
Figure 15, which KDE Plot powers, is supplemented by another Box Plot demonstrating the distribution of error levels of optimization models. The visualization technique very well captures the composite values like the median, the percentiles and, could be, the outlier of the accuracy values in order to compare them to different optimization schemes.

Box plot with swarm overlay: accuracy by optimization models.
Rounding off the metrics evaluation, Fig. 16 ranks optimization models using different metrics such as Accuracy, Sensitivity, Specificity, PPV, NPV, and F1 Score. The performance of all the optimization models is evaluated comprehensively using multiple performance metrics, which help in selecting the most appropriate model, tuning its parameters, and finally in process improvement.

Performance of the Reference models using Accuracy, Sensitivity (TRP), Specificity(TNP) by Model, Pvalue (PPV), Pvalue (NPV), FScore by Optimization Models.
Limitations
GGO algorithm study in improving lung cancer classification shows good results, especially in improving feature selection and classification accuracy. However, there are several limitations and directions for future work that can be addressed to further improve the effectiveness of GGO in this field:
-
The performance of the GGO algorithm was tested on one dataset only that may not represent the variety of real-world scenarios. Results may vary across different datasets, which may affect the generalizability of the results.
-
Classification accuracy depends largely on the quality and completeness of the input data. Any inconsistencies or missing values in the data can affect the results.
Conclusion and future work
The GGO algorithm was introduced in this work with the objective of improving the accuracy of lung cancer case classification. In the beginning, data preparation techniques such as scaling, normalization, and removal of null values are carried out. In addition, the feature selection is performed utilizing the binary format of GGO (bGGO). The GGO algorithm's binary format is specifically intended to choose the most optimum combination of features that can improve classification accuracy when compared to six other binary optimization algorithms (SC, MVO, PSO, WOA, GWO, and FOA). The classification phase utilizes many classifiers, such as SVC, DTC, RFC, KNC, and MLP. The findings indicated that the Multilayer Perceptron (MLP) emerged as the most effective classifier, achieving an accuracy rate of 91.8%. The hyperparameter of the MLP model is tuned using GGO, and the outcome is compared to six alternative optimizers. The GGO with MLP model generated the highest result, with an accuracy of 98.4%. The statistical analysis employed the Wilcoxon signed-rank test and ANOVA for the feature selection and classification outcomes. Furthermore, a set of visual representations of the results was created to confirm the robustness and effectiveness of the proposed approach. Overall, the experimental and statistical results clearly indicate that the proposed approach outperforms other competing approaches for classifying lung cancer. The effective selection of cancer features, and the reduction of feature dimensionality enhanced the overall prediction accuracy and successfully mitigated the problem of overfitting in cancer features analysis. Enhancing the early prediction rates of lung cancer may be achieved by acquiring and analyzing sensor data, then employing an optimum approach in the future. The performance of the GGO algorithm was tested on specific dataset for lung cancer classification, so in the future, several large datasets can be used for generalizing the results. Also, in the future several optimization models and deep learning models32,33,34 can be used for lung cancer classification.
References
Asuntha, A. & Srinivasan, A. Deep learning for lung Cancer detection and classification. Multimed. Tools Appl. 79, 7731–7762 (2020).
Chaturvedi, P., Jhamb, A., Vanani, M. & Nemade, V. Prediction and classification of lung cancer using machine learning techniques. In IOP Conference Series: Materials Science and Engineering 12059 (IOP Publishing, 2021).
Zhu, Y. et al. Feature selection and performance evaluation of support vector machine (SVM)-based classifier for differentiating benign and malignant pulmonary nodules by computed tomography. J. Digit. Imaging 23, 51–65 (2010).
Nanglia, P., Kumar, S., Mahajan, A. N., Singh, P. & Rathee, D. A hybrid algorithm for lung cancer classification using SVM and Neural Networks. ICT Express 7(3), 335–341 (2021).
Elshewey, A. M. et al. A Novel WD-SARIMAX model for temperature forecasting using daily Delhi climate dataset. Sustainability 15(1), 757 (2022).
Elhoseny, M., Tarek, Z. & El-Hasnony, I. M. Advanced cognitive algorithm for biomedical data processing: COVID-19 pattern recognition as a case study. J. Healthc. Eng. 2022, 1–11 (2022).
Deserno, T. M., Antani, S. & Long, R. Ontology of gaps in content-based image retrieval. J. Digit. Imaging 22, 202–215 (2009).
Ezugwu, A. E. et al. Metaheuristics: A comprehensive overview and classification along with bibliometric analysis. Artif. Intell. Rev. 54, 4237–4316 (2021).
Mohamed, T. I. A., Oyelade, O. N. & Ezugwu, A. E. Automatic detection and classification of lung cancer CT scans based on deep learning and ebola optimization search algorithm. PLoS ONE 18(8), e0285796 (2023).
Ren, Z., Zhang, Y. & Wang, S. A hybrid framework for lung cancer classification. Electronics 11(10), 1614 (2022).
Bhattacharjee, A., Murugan, R. & Goel, T. A hybrid approach for lung cancer diagnosis using optimized random forest classification and K-means visualization algorithm. Health Technol. (Berl). 12(4), 787–800 (2022).
Vijh, S., Gaur, D. & Kumar, S. An intelligent lung tumor diagnosis system using whale optimization algorithm and support vector machine. Int. J. Syst. Assur. Eng. Manag. 11, 374–384 (2020).
Shakeel, P. M., Tolba, A., Al-Makhadmeh, Z. & Jaber, M. M. Automatic detection of lung cancer from biomedical data set using discrete AdaBoost optimized ensemble learning generalized neural networks. Neural Comput. Appl. 32, 777–790 (2020).
Nancy, D. P. et al. Optimized feature selection and image processing based machine learning technique for lung cancer detection. IJEER 10(4), 888–894 (2022).
Joshi, A. A. & Aziz, R. M. A two-phase cuckoo search based approach for gene selection and deep learning classification of cancer disease using gene expression data with a novel fitness function. Multimed. Tools Appl. 83, 71721–71752 (2024).
Saxena, A., Chouhan, S. S., Aziz, R. M. & Agarwal, V. A comprehensive evaluation of Marine predator chaotic algorithm for feature selection of COVID-19. Evol. Syst. 15, 1235–1248 (2024).
Yaqoob, A., Verma, N. K., Aziz, R. M. & Saxena, A. Enhancing feature selection through metaheuristic hybrid cuckoo search and Harris Hawks optimization for cancer classification. In Metaheuristics for Machine Learning: Algorithms and Applications 95–134 (Springer, 2024).
El-kenawy, E. S. M. et al. Greylag Goose Optimization: Nature-inspired optimization algorithm. Expert Syst. Appl. 238, 122147 (2024).
Samadianfard, S. et al. Wind speed prediction using a hybrid model of the multi-layer perceptron and whale optimization algorithm. Energy Rep. 6, 1147–1159 (2020).
Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl.-Based Syst. 96, 120–133 (2016).
Rigamonti, A. Mean-variance optimization is a good choice, but for other reasons than you might think. Risks 8(1), 29 (2020).
Piotrowski, A. P., Napiorkowski, J. J. & Piotrowska, A. E. Particle swarm optimization or differential evolution: A comparison. Eng. Appl. Artif. Intell. 121, 106008 (2023).
Mirjalili, S. & Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 95, 51–67 (2016).
Al-Tashi, Q., Md Rais, H., Abdulkadir, S. J., Mirjalili, S. & Alhussian, H. A review of grey wolf optimizer-based feature selection methods for classification. In Evolutionary Machine Learning Techniques: Algorithms and Applications 273–86 (Springer, 2020).
de Vasconcelos Segundo, E. H., Mariani, V. C. & dos Santos, C. L. Design of heat exchangers using falcon optimization algorithm. Appl. Therm. Eng. 156, 119–144 (2019).
Saigal, P. & Khanna, V. Multi-category news classification using support vector machine based classifiers. SN Appl. Sci. 2(3), 458 (2020).
Shams, M. Y. et al. A machine learning-based model for predicting temperature under the effects of climate change. In The Power of Data: Driving Climate Change with Data Science and Artificial Intelligence Innovations 61–81 (Springer, 2023).
Tarek, Z. et al. Soil erosion status prediction using a novel random forest model optimized by random search method. Sustainability 15(9), 7114 (2023).
Elshewey, A. et al. Weight prediction using the hybrid stacked-LSTM food selection model. Comput. Syst. Sci. Eng. 46(1), 765–81 (2023).
Al Bataineh, A., Kaur, D. & Jalali, S. M. J. Multi-layer perceptron training optimization using nature inspired computing. IEEE Access 10, 36963–36977 (2022).
Saeed, M. et al. Electrical power output prediction of combined cycle power plants using a recurrent neural network optimized by waterwheel plant algorithm. Front. Energy Res. 11, 1234624 (2023).
Shams, M. Y., El-kenawy, E. S., Ibrahim, A. & Elshewey, A. M. A hybrid dipper throated optimization algorithm and particle swarm optimization (DTPSO) model for hepatocellular carcinoma (HCC) prediction. Biomed. Signal Process. Control 85, 104908 (2023).
Elshewey, A. M., Tawfeek, S. M., Alhussan, A. A., Radwan, M. & Abed, A. H. Optimized deep learning for potato blight detection using the waterwheel plant algorithm and sine cosine algorithm. Potato Res. https://doi.org/10.1007/s11540-024-09735-y (2024).
Shams, M. Y., Tarek, Z., El-kenawy, E. S., Eid, M. M. & Elshewey, A. M. Predicting Gross Domestic Product (GDP) using a PC-LSTM-RNN model in urban profiling areas. Comput. Urban Sci. 4(1), 3 (2024).
Acknowledgements
Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2024R 308), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
All authors have contributed equally.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Elkenawy, ES.M., Alhussan, A.A., Khafaga, D.S. et al. Greylag goose optimization and multilayer perceptron for enhancing lung cancer classification. Sci Rep 14, 23784 (2024). https://doi.org/10.1038/s41598-024-72013-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-72013-x
Keywords
This article is cited by
-
Prediction of death in burn patients infected with antibiotic-resistant Staphylococcus aureus using machine learning based techniques
BMC Infectious Diseases (2026)
-
Optimization of proton exchange membrane fuel cell design parameters using Tianji’s horse racing optimization
Scientific Reports (2026)
-
FetalMLOps: operationalizing machine learning models for standard fetal ultrasound plane classification
Medical & Biological Engineering & Computing (2026)
-
A combined voting mechanism in KNN and random forest algorithms to enhance the diabetic retinopathy eye disease detection
Advances in Computational Intelligence (2026)
-
Benchmarking Ensemble Learning Approaches for Coronary Artery Disease Classification
International Journal of Computational Intelligence Systems (2026)
